초고속 고품질 원격탐사 단일 이미지 깊이 추정 D3 RSMDE
본 논문은 원격탐사 영상에서 실시간으로 고품질 단일 이미지 깊이 지도를 생성하기 위해, Vision Transformer 기반의 빠른 구조 예측과 경량 U‑Net을 이용한 확산 기반 디테일 보강을 결합한 D3‑RSMDE 프레임워크를 제안한다. 구조 사전 정보를 활용해 초기 확산 과정을 대체하고, Progressive Linear Blending Refinement(PLBR)와 VAE 기반 잠재 공간에서의 확산을 통해 40배 이상의 추론 속도 향…
저자: Ruizhi Wang, Weihan Li, Zunlei Feng
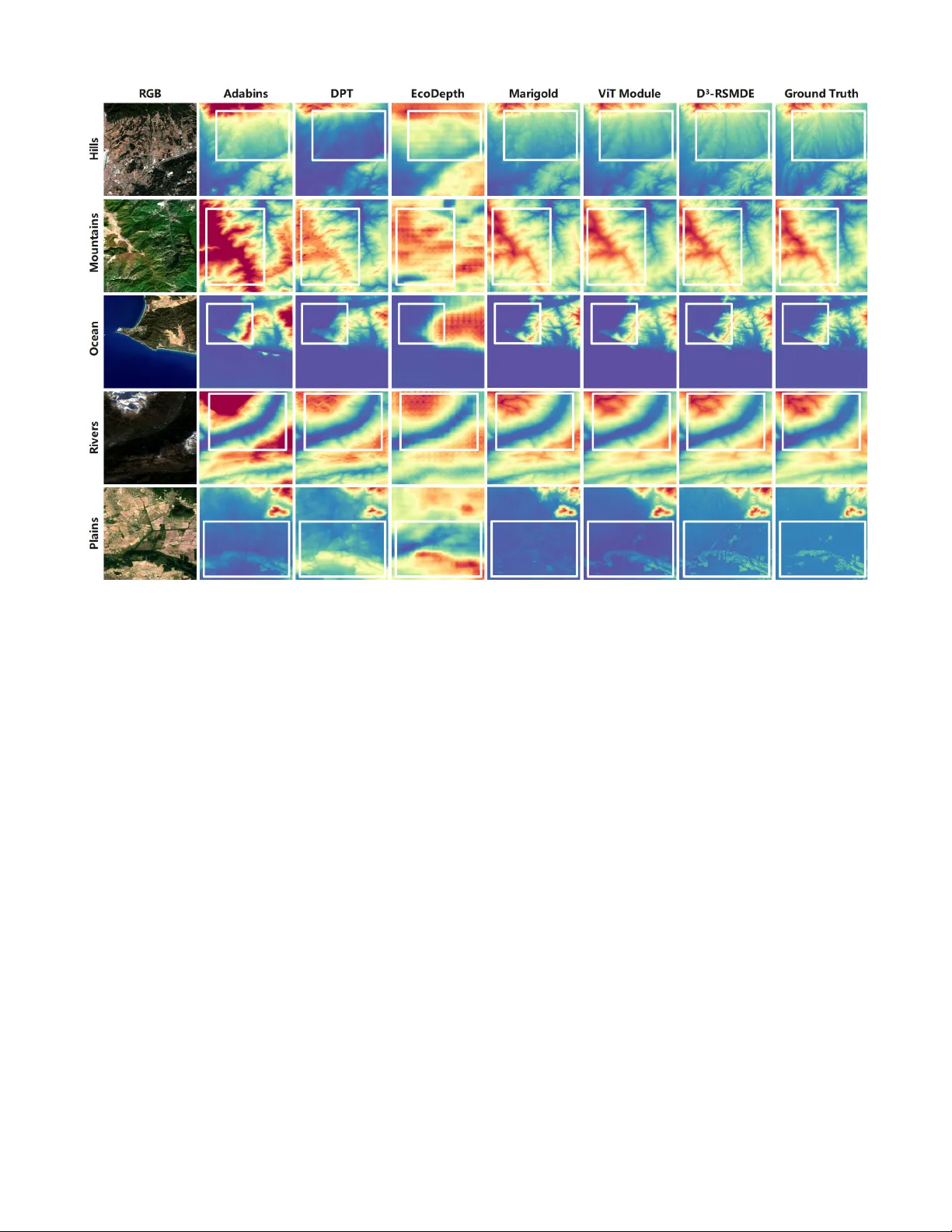
본 논문은 원격탐사 이미지에서 실시간으로 고품질 단일 이미지 깊이 추정을 수행하는 새로운 프레임워크 D3‑RSMDE를 제안한다. 기존 방법은 정확도와 효율성 사이에 뚜렷한 트레이드오프가 존재했으며, Vision Transformer(ViT) 기반 모델은 빠르지만 고주파 디테일이 부족하고, 확산 모델은 디테일 복원에 강하지만 연산 비용이 prohibitive했다. 저자들은 이러한 양쪽의 약점을 동시에 보완하고자, 두 모델의 장점을 결합한 하이브리드 구조를 설계했다.
첫 번째 단계는 ViT 기반 모듈을 이용해 빠르게 구조적인 coarse depth map을 생성하는 것이다. 여기서는 Hierarchical Depth Normal(HDN) 손실을 적용해 전역적인 구조 일관성과 로컬 디테일을 동시에 학습한다. ViT는 입력 이미지를 패치 단위로 토큰화하고, 다중 레이어의 self‑attention을 통해 장거리 의존성을 포착한다. 중간 단계에서 다중 스케일 피처를 추출하고, RefineNet‑스타일 디코더를 통해 반 해상도 수준의 깊이 지도를 출력한다.
두 번째 단계는 이 coarse depth를 구조 사전으로 활용해 경량 확산 리파인먼트를 수행한다. 저자들은 기존 확산 모델이 초기 단계에서 순수 노이즈부터 전체 구조를 재구성하는 비효율성을 지적하고, 대신 coarse depth와 ground‑truth depth를 라인형으로 블렌딩하는 PLBR(Progressive Linear Blending Refinement) 전략을 도입했다. PLBR은 \(\bar\alpha_t = \epsilon^{T-1}(T-t-1)\) 라는 스케줄을 사용해, t가 커질수록 coarse depth의 비중이 감소하고 ground‑truth에 가까워지는 형태로 학습 데이터를 생성한다. 이렇게 생성된 다양한 “노이즈 레벨” 샘플을 조건부 확산 네트워크가 학습한다.
효율성을 높이기 위해 전체 확산 과정은 사전 학습된 VAE(Variational Autoencoder)의 잠재 공간에서 수행된다. VAE는 입력 이미지와 깊이 지도 모두를 저차원 latent representation으로 압축하며, 이를 통해 픽셀 공간에서의 연산량을 크게 줄인다. 경량 U‑Net 기반의 확산 디코더는 텍스트 cross‑attention이나 다중 소스 조건부 모듈을 제거하고, 이미지와 timestep 정보를 중심으로 설계돼 메모리 사용량을 최소화한다.
실험에서는 5개의 원격탐사 데이터셋(예: ISPRS Vaihingen, DFC2019 등)에서 Marigold, EcoDepth 등 최신 확산 기반 모델과 비교했다. D3‑RSMDE는 LPIPS 점수에서 평균 11.85% 개선을 보였으며, 추론 시간은 14 초( Marigold)에서 0.35 초 이하로 40배 이상 가속화되었다. 또한, VRAM 사용량은 8 GB 이하로 유지돼 일반적인 GPU에서도 실시간 배포가 가능하다. Ablation Study 결과, ViT 사전 예측 없이 바로 확산을 수행하면 LPIPS가 크게 악화되고, VAE 없이 픽셀 공간에서 확산하면 메모리 요구량이 3배 이상 증가한다는 것을 확인했다.
논문의 주요 기여는 다음과 같다. (1) 구조 사전으로 초기 확산 과정을 대체해 효율성을 극대화한 D3‑RSMDE 프레임워크 제안, (2) PLBR이라는 비마코프식 라인형 블렌딩 전략을 도입해 전역 구조와 디테일을 동시에 보존, (3) VAE 기반 잠재 공간에서 경량 확산을 수행해 메모리와 연산량을 크게 감소.
한계점으로는 VAE와 ViT 사전 학습 단계가 필요하고, 매우 고해상도(>4K) 이미지에 대해서는 잠재 차원과 샘플링 스텝을 재조정해야 할 가능성이 있다. 향후 연구에서는 멀티스케일 VAE 설계, 텍스처 강화용 추가 어텐션 모듈, 그리고 다양한 원격탐사 센서(멀티스펙트럼, SAR)와의 멀티모달 통합을 통해 더욱 일반화된 깊이 추정 시스템을 구축할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기