오픈소스 LLM으로 UML 클래스 다이어그램 채점 혁신
** 본 연구는 92개의 UML 클래스 다이어그램을 대상으로 여섯 가지 오픈소스 대형 언어 모델(LLM)의 채점 결과를 교육조교(TA)의 평가와 비교한다. 개별 채점 기준별 정확도는 최고 88.56%, 전체 점수와 TA 점수 간 피어슨 상관계수는 0.798에 달한다. 모델별 편향과 오류 패턴을 분석하고, 최적 모델을 구성해 TA 수준에 근접한 성능을 확인함으로써, 비용 효율적인 자동 채점 파이프라인의 실현 가능성을 제시한다. **
저자: Matthijs Jansen op de Haar, Nacir Bouali, Faizan Ahmed
**
본 논문은 대학 수준 소프트웨어 설계 과목에서 학생들이 제출한 UML 클래스 다이어그램을 자동으로 채점하기 위한 파이프라인을 제안하고, 이를 실제 교육 현장에서 활용 가능한 수준으로 검증한다. 연구의 핵심 동기는 (1) 기존 자동 채점 연구가 주로 비용이 많이 드는 상용 LLM을 사용하고, (2) 전체 다이어그램 점수만을 평가해 채점 기준별 정밀도가 부족하다는 점이다. 이를 해결하기 위해 저자들은 오픈소스 LLM을 활용하고, 채점 결과를 교육조교(TA)의 평가와 개별 기준별로 비교하는 방식을 채택하였다.
**데이터와 평가 설계**
- **데이터**: 1학년 소프트웨어 설계 시험에서 수집된 92개의 UML 클래스 다이어그램. 각 다이어그램은 JSON과 PNG 두 형식으로 제출되며, JSON에는 클래스·연관·다중성 정보가 구조화돼 있다.
- **채점 루브릭**: 40개의 세부 기준(클래스 존재, 연관 관계, 다중성 등)으로 구성되며, 각 기준은 0, 0.5, 1점으로 채점한다.
- **인간 채점**: 3명의 TA가 루브릭에 따라 점수를 부여하고, 일관성을 위해 사전 협의 및 교차 검증을 수행한다.
**LLM 기반 자동 채점 파이프라인**
1. **파싱 단계**: 기존 파서는 학생이 라벨을 임의 위치에 배치하거나 다중성을 텍스트 형태로 표기하는 등 비표준 입력을 제대로 처리하지 못했다. 새 파서는 라벨 위치와 내용 모두를 검사해 다중성(숫자, ‘*’, ‘many’, 한글 숫자 등)을 인식하고, 가장 가능성이 높은 클래스와 연결한다.
2. **프롬프트 설계**: 파싱된 자연어 설명을 고정 프롬프트에 삽입한다. 프롬프트는 (a) 루브릭 전체를 제공, (b) 각 기준별 점수만 반환하도록 명시, (c) 필요 시 각 기준에 대한 설명·근거를 요구한다. 총점은 LLM이 직접 계산하지 않고 외부에서 합산한다.
3. **모델 선택**: 비용·오픈소스·인기 등을 고려해 GLM‑4.7, DeepSeek‑V3.2, Mistral‑24B, MiniMax‑M2.1, Gemma‑3‑27B, Qwen‑3‑80B 등 6가지 모델을 선정하였다. 모든 모델은 온도 0으로 실행해 결정론적 출력을 확보하였다.
**실험 결과**
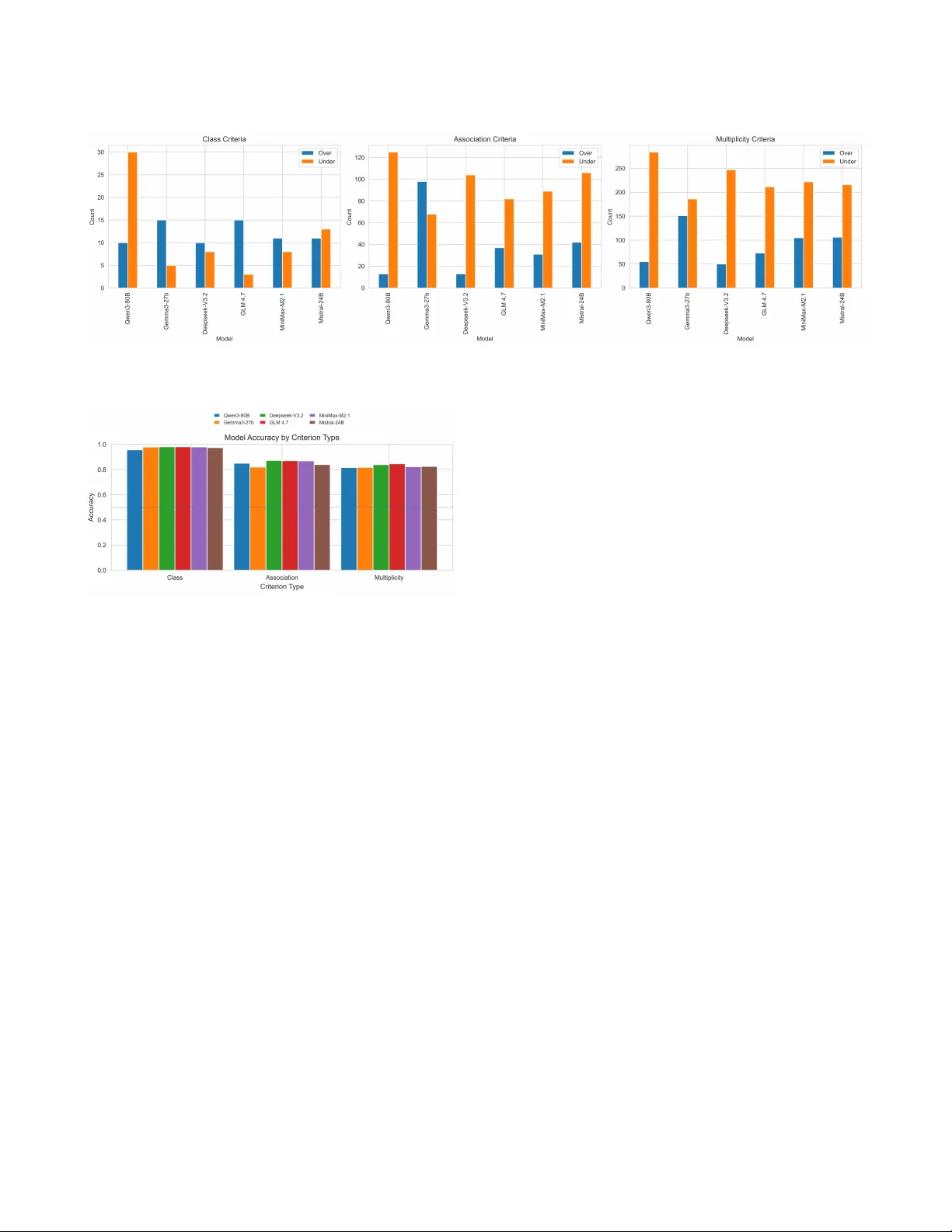
- **전체 점수 수준**: GLM‑4.7이 ρ = 0.798, MAE = 3.22점으로 가장 높은 상관관계와 최소 평균 절대 오차를 기록했다. Mistral‑24B, DeepSeek‑V3.2, MiniMax‑M2.1도 ρ > 0.75를 달성했다. 이는 기존 연구에서 보고된 상용 모델(GPT‑o1‑mini, Claude Sonnet)과 동등하거나 우수한 수준이다.
- **편향 분석**: 대부분의 모델이 TA보다 낮은 점수를 주는 ‘하향 편향’이 존재했다. Qwen‑3‑80B는 평균 –0.087점, DeepSeek‑V3.2는 –0.067점, GLM‑4.7은 –0.045점의 차이를 보였다. Gemma‑3‑27B는 거의 편향이 없었다(–0.007점).
- **기준별 정확도**: 3,680개의 (40 × 92) 채점 사례를 분석한 결과, 전체 정확도는 85%~89% 사이였다. 클래스 존재 판단은 97.5%로 가장 높았으며, 연관 관계는 84.7%, 복잡한 다중성은 82.7%로 낮았다. 특히 ‘Maintenance Operator’와 복합 관계 체인 등 후반에 등장하는 항목은 55% 이하의 정확도를 보였다.
- **모델별 특성**: Qwen‑3‑80B와 Mistral‑24B는 복합 관계와 다중성에서 과소평가 경향이 강했으며, Gemma‑3‑27B는 과대평가 경향이 뚜렷했다. GLM‑4.7은 전반적으로 가장 균형 잡힌 성능을 보여, 가장 낮은 편향(–0.011점)과 높은 정확도를 기록했다.
**최적 모델 및 혼합 이니셔티브**
각 기준별 최고 성능을 보인 모델을 조합한 가상의 ‘최적 모델’을 구성하였다. 이 모델은 전체 점수에서 TA와 거의 동일한 상관계수(≈0.80)와 MAE(≈3.1점)를 달성했으며, 개별 기준에서도 평균 정확도가 90%에 육박했다. 이러한 결과는 (1) 인간‑인‑루프(HITL) 혹은 혼합 이니셔티브 채점 시스템에서 LLM이 초기 채점 베이스로 활용될 수 있음을, (2) 모델별 강점을 적절히 결합하면 인간 수준의 정밀도를 얻을 수 있음을 시사한다.
**시사점 및 한계**
- **실용성**: 오픈소스 LLM은 비용·투명성 측면에서 대학 교육에 적합하며, 파싱·프롬프트 설계만 적절히 하면 상용 모델과 동등한 성능을 낼 수 있다.
- **제한점**: 복잡한 관계·다중성 판단에서 여전히 오류가 많으며, 모델별 편향이 피드백의 공정성을 위협한다. 따라서 자동 채점 후 인간 검증 단계가 필요하다.
- **미래 연구**: (a) 파싱 정확도 향상을 위한 모델‑기반 라벨 인식, (b) 편향 보정을 위한 후처리 알고리즘, (c) 실제 교육 현장에서의 혼합 이니셔티브 워크플로우 설계와 사용자 경험 평가가 요구된다.
결론적으로, 본 연구는 오픈소스 LLM을 활용한 UML 클래스 다이어그램 자동 채점이 기술적·경제적으로 타당함을 입증하고, 개별 채점 기준별 정밀 분석을 통해 인간과의 정렬 정도를 명확히 제시한다. 이는 교육기관이 자동 채점 시스템을 도입하거나 기존 시스템에 LLM을 보조 도구로 통합하는 데 실질적인 로드맵을 제공한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기