파슈토코프 12억 단어 규모 저자원 언어를 위한 대규모 코퍼스와 평가 파이프라인
파슈토코프는 파슈토어 1.25 억 단어(2.81 백만 문서) 규모의 코퍼스를 39개 출처에서 수집·정제한 뒤, 재현 가능한 파이프라인으로 전처리하였다. XLM‑R‑base 모델을 파슈토코프로 추가 MLM 사전학습하면 퍼플렉시티가 25 % 감소하고, WikiANN 파슈토 NER에서 엔티티 F1이 10 % 상대 향상된다. 또한, 베레벨레 독해 벤치마크에서 Gemma‑3n이 64.6 % 정확도를 기록, 파슈토어에 대한 최초 LLM 베이스라인을 제공한…
저자: Hanif Rahman
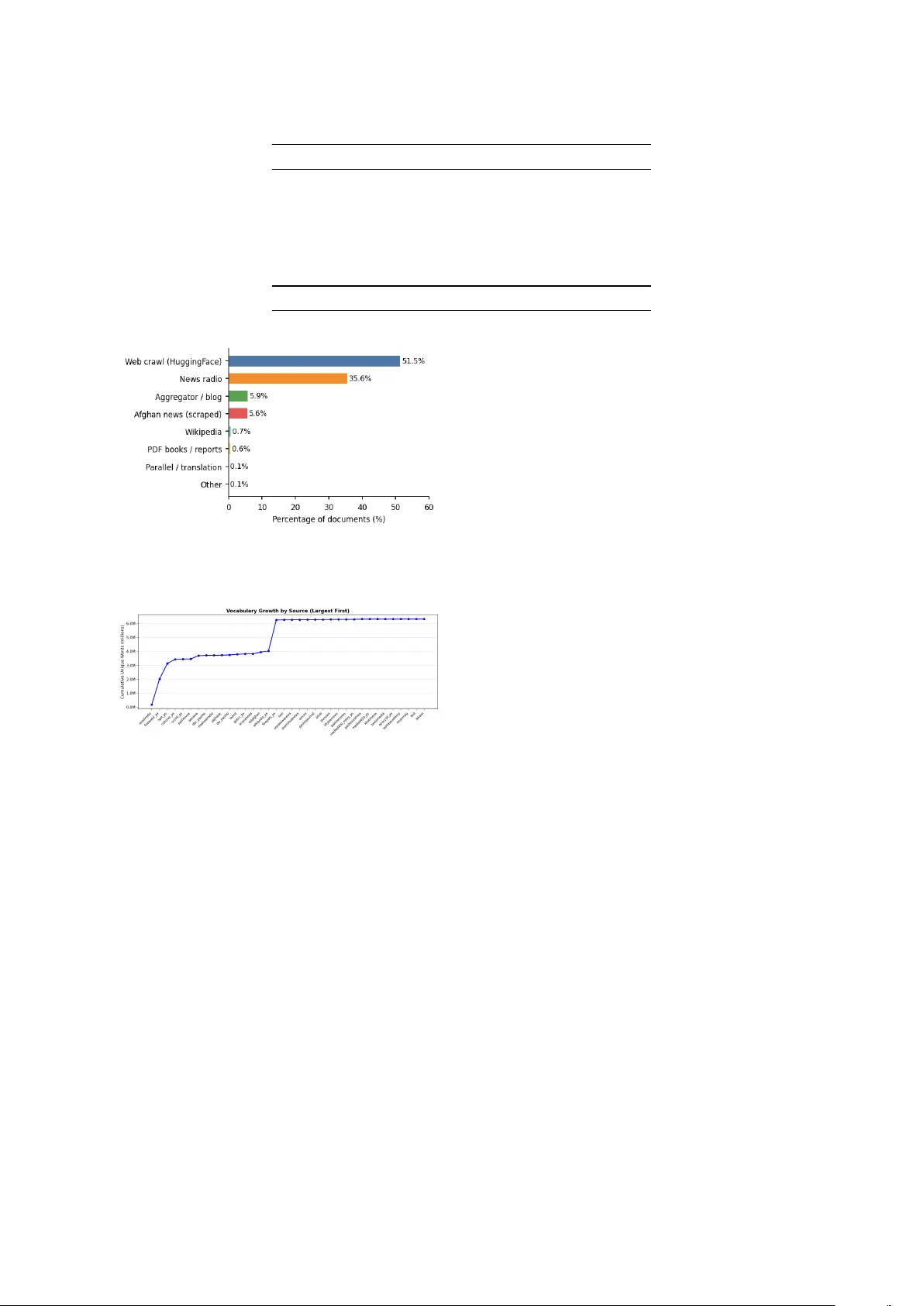
이 논문은 파슈토어(60 백만 명 사용)라는 저자원 언어를 위해 1.25 억 단어 규모의 파슈토코프(PashtoCorp) 코퍼스를 구축하고, 이를 활용한 평가 스위트와 재현 가능한 파이프라인을 제시한다. 코퍼스는 39개의 이질적인 출처를 통합했으며, 여기에는 7개의 HuggingFace 데이터셋(OSCAR, CulturaX, CC‑100, MADLAD‑400, GlotCC, FineWeb2, HPL T)과 32개의 맞춤형 웹 스크래퍼가 포함된다. 각 스크래퍼는 시작 URL, 페이지네이션 규칙, CSS 선택자를 정의해 자동화된 크롤링을 수행하고, 언어 식별 단계에서 파슈토어 유니코드 범위에 기반해 70 % 이상 토큰이 파슈토어인 문서만을 통과시킨다. 이후 SHA‑256 해시 기반 중복 제거와 최소 토큰 수(10) 필터링을 거쳐 최종 2,810,913개의 문서와 1,249,765,401개의 토큰을 확보했다.
코퍼스 규모는 기존 OSCAR 파슈토 서브셋(≈31 M 단어)보다 40배, 이전 최대 파슈토 전용 코퍼스(≈15 M 단어)보다 83배에 달한다. 어휘 측면에서는 6,322,778개의 고유 형태를 포함하고, 전체 어휘의 35 %가 전체 문서의 0.6 %에 해당하는 PDF·책(FinePDFs)에서 기인한다는 점을 강조한다. Zipf 법칙 분석 결과 α=1.624(R²=0.985)로, 파슈토어의 풍부한 굴절 형태가 높은 α값을 만든다.
모델 실험에서는 XLM‑R‑base에 파슈토코프의 100 M 토큰(전체의 8 %)을 추가 MLM 사전학습(750 스텝, 배치 32, LR 1e‑4)했다. 이 과정에서 퍼플렉시티가 8.08→6.06(25.1 % 감소)했으며, WikiANN 파슈토 NER에서 엔티티 F1이 19.0 %→21.0 %(+10.3 % 상대)로 향상되고 변동성은 4.7 %→0.7 %로 7배 감소했다. 특히 훈련 샘플이 50문장일 때 F1이 27 % 상승하는 등 데이터 효율성이 크게 개선되었다. 반면, 소셜 미디어 기반 POLD 공격적 언어 탐지에서는 파슈토코프가 91.6 % 어휘를 커버하지만, 도메인 불일치로 성능 향상이 미미했다(94.5 %→94.0 % F1).
소스별 기여도 분석에서는 위키피디아가 전체 문서의 0.7 %에 불과함에도 NER 성능에 가장 큰 영향을 미쳐, 제거 시 엔티티 F1이 47 % 감소한다는 결과가 나왔다. 웹 크롤링은 퍼플렉시티 감소에 가장 크게 기여했으며, 라디오 방송은 어휘 다양성은 낮지만 NER에 일정 기여를 보였다. 이러한 정량적 ablation은 코퍼스 구축 시 양보다 질·다양성에 중점을 두어야 함을 시사한다.
베레벨레(Pashto) 독해 벤치마크에서는 기존 임베딩 기반 방법이 무작위 수준(≈25 %)에 머물렀으나, 대형 멀티링꾼 LLM인 Gemma‑3n‑E4B가 64.6 % 정확도를 기록, 파슈토어에 대한 최초 공개 LLM 베이스라인을 제공했다. 이는 파슈토코프가 대규모 사전학습 데이터로 활용될 경우, 언어 모델이 복합적인 이해 능력까지 확장될 가능성을 보여준다.
논문의 논의에서는 (1) 도메인 정렬이 다운스트림 성능에 결정적 영향을 미친다(뉴스·위키피디아와 NER, 소셜 미디어와 POLD 간 격차), (2) 소수의 고품질 문서(PDF·책)가 어휘 다양성에 큰 기여를 한다, (3) 현재 실험은 전체 코퍼스의 8 %만 사용했으므로 전체 규모 학습 시 더 큰 성능 향상이 기대된다, (4) 파슈토코프는 87.8 %가 뉴스·웹 크롤링이며, 방글라데시·아프가니스탄 중심이므로 파슈토어 방언(파키스탄·디아스포라) 편향이 존재한다는 한계를 인정한다.
재현성 측면에서 코퍼스 구축 파이프라인은 단일 머신에서 24시간 이내에 완료되며, 사전학습은 Apple M4(MPS/Metal)만으로 158분에 수행된다. 파이프라인은 유니코드 범위만 교체하면 다른 아라비아 스크립트 언어(다리, 우르두, 신디)에도 적용 가능하고, 스크립트 교체만으로 전 세계 저자원 언어에 확장할 수 있다.
결론적으로, 파슈토코프는 저자원 언어 NLP 연구에 필요한 대규모 고품질 코퍼스를 제공하고, 도메인 정렬·소스 다양성·재현 가능성에 대한 실증적 인사이트를 제시함으로써 향후 다국어 모델 개발 및 저자원 언어 지원에 중요한 기반을 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기