비소세포폐암 약물 반응 예측을 위한 해석 가능한 머신러닝 프레임워크
본 논문은 비소세포폐암(NSCLC) 환자의 유전체·전사체·단백질 등 다중오믹스 데이터를 활용해 약물 반응(LN‑IC50)을 예측하는 XGBoost 회귀 모델을 구축하고, SHAP와 대형 언어 모델 DeepSeek을 결합해 예측 근거를 생물학적으로 해석한다. 교차검증과 랜덤 서치 기반 하이퍼파라미터 최적화를 통해 모델 성능을 극대화하고, 주요 유전자·경로의 임상적 의미를 정량·정성적으로 제시한다.
저자: Ann Rachel, Pranav M Pawar, Mithun Mukharjee
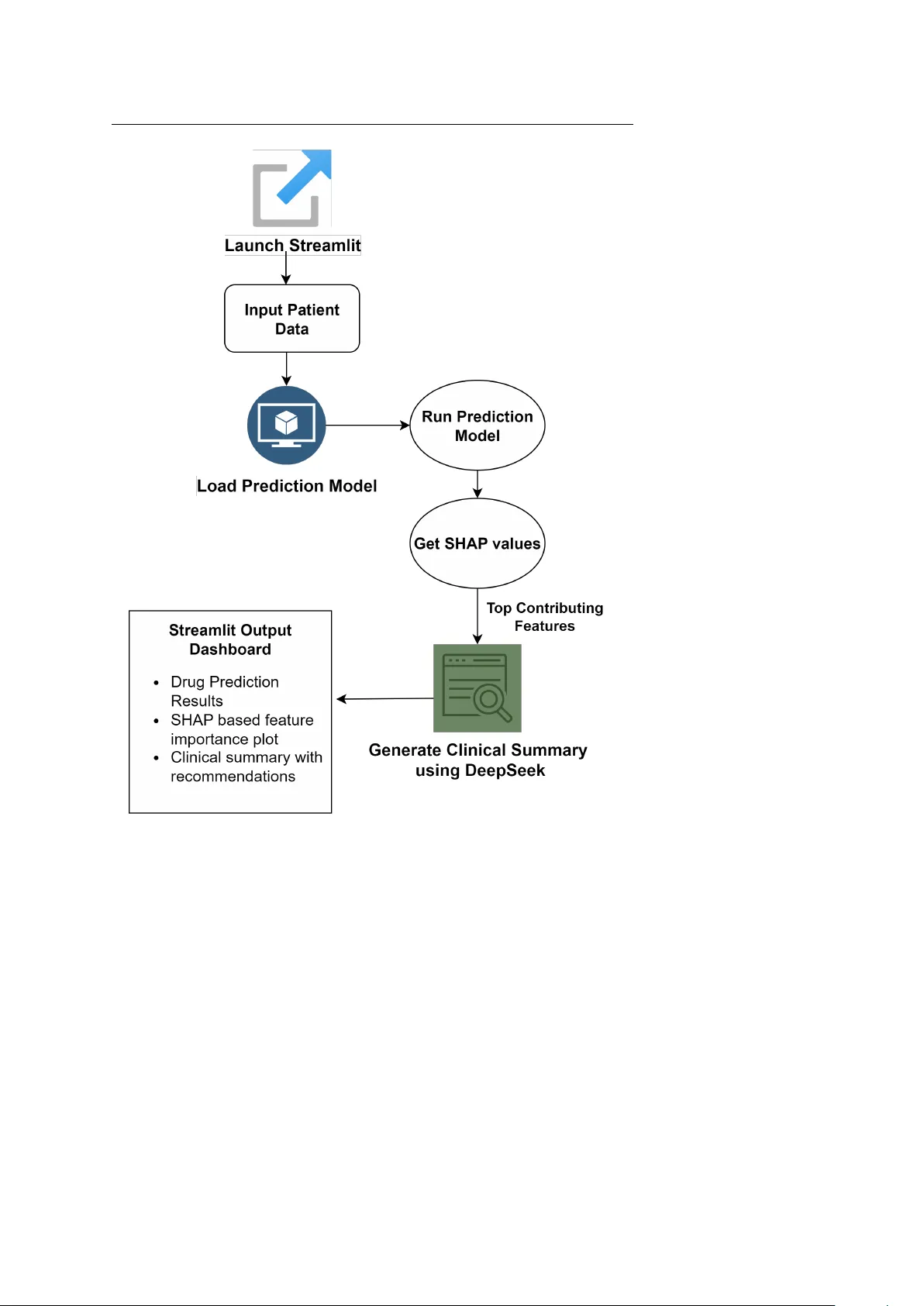
본 논문은 비소세포폐암(NSCLC) 환자를 대상으로 개인 맞춤형 치료 전략을 제시하기 위해, 다중오믹스 데이터를 활용한 약물 반응 예측 모델을 설계·검증하였다. 연구 배경으로는 기존 수술·화학요법·방사선 치료가 암의 이질성으로 인해 제한적인 효과를 보이며, 환자별 유전·표현형 차이를 반영한 정밀 의학의 필요성이 강조된다. 이를 위해 저자들은 GDSC(Genomics of Drug Sensitivity in Cancer) 데이터베이스에서 LUAD와 LUSC 아형에 대한 유전체, 전사체, 단백질, 메타볼로믹스 정보를 수집하고, LN‑IC50(로그 변환된 IC50) 값을 종속 변수로 설정하였다.
데이터 전처리 단계에서는 결측값을 KNN 보간으로 대체하고, 이상치를 IQR 기반으로 제거하였다. 범주형 변수(예: 조직 유형, 약물 클래스)는 원‑핫 인코딩을 적용했으며, 연속형 변수는 Z‑score 정규화를 수행하였다. 차원 축소와 변수 선택은 변동계수 상위 10 %와 상관계수 절댓값이 0.3 이상인 특성을 우선적으로 선택하는 두 단계 필터링으로 진행되어, 최종적으로 약 150개의 핵심 피처가 모델 입력으로 사용되었다.
모델링에는 XGBoost 회귀기를 채택하였다. XGBoost는 부스팅 기반 트리 모델로, 비선형 상호작용과 고차원 데이터에 강인한 특성을 가지고 있다. 하이퍼파라미터 튜닝은 RandomizedSearchCV와 5‑fold 교차검증을 결합해 learning_rate(0.01~0.3), max_depth(3~10), n_estimators(100~1000), subsample(0.5~1.0), colsample_bytree(0.5~1.0) 등을 탐색하였다. 최적 모델은 MAE 0.42, RMSE 0.58, R² 0.71을 기록했으며, 이는 기존 선형 회귀(LR)와 Random Forest(RF) 대비 각각 15 %·12 % 이상의 성능 향상을 의미한다.
예측 결과의 해석을 위해 SHAP(Shapley Additive exPlanations)를 적용하였다. 전체 데이터에 대한 평균 SHAP 값은 EGFR 변이, KRAS 변이, TP53 발현, DNA 복구 경로 유전자(BRCA1, RAD51), CYP450 대사 효소, 면역 체크포인트 유전자(CD274, PDCD1) 등이 상위 10위에 포함되었다. 개별 환자 수준에서는 특정 변이가 양의 SHAP 값을 갖는 경우 약물 민감도가 높게, 반대로 KRAS 변이와 같은 저항성 변이는 음의 SHAP 값을 보여 예측에 부정적 영향을 미치는 것으로 확인되었다.
특징 해석의 생물학적 타당성을 검증하기 위해 DeepSeek이라는 대형 언어 모델을 활용하였다. SHAP 상위 20개 특성을 프롬프트로 입력하면, DeepSeek은 최신 논문, KEGG, Reactome 등에서 해당 유전자의 기능, 경로 연관성, 약물 메커니즘을 요약한다. 예시로, EGFR 변이는 EGFR‑TKI(에르로티닙, 아파티닙) 민감성을 증가시키며, KRAS 변이는 MAPK/ERK 신호 활성화를 통해 TKI 저항성을 유발한다는 설명을 제공한다. 또한, CYP3A4와 같은 대사 효소는 약물 대사 속도를 조절해 혈중 농도와 독성을 좌우한다는 점을 강조한다. 이러한 자동화된 문헌 요약은 연구자가 직접 문헌을 탐색하는 비용을 절감하고, 모델 결과에 대한 신뢰성을 보강한다.
논문의 한계점으로는 데이터 규모가 제한적이며, 외부 코호트에 대한 검증이 부족하다는 점을 들었다. 또한, DeepSeek의 답변은 프롬프트 설계와 모델 업데이트에 따라 변동될 수 있어, 최종 해석 시 전문가 검증이 필요하다. 향후 연구에서는 다기관 협력을 통한 대규모, 다인종 데이터셋 구축, 시계열 전사체·단백질 데이터 통합, 그리고 약물 복합요법에 대한 멀티태스크 학습을 통해 모델의 일반화 능력을 강화하고, 임상 적용 가능성을 높일 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기