통합 음색 제어를 위한 단순 교차‑어텐션 프레임워크 CAST‑TTS
CAST‑TTS는 음성 프롬프트와 텍스트 프롬프트를 하나의 모델에서 동시에 활용할 수 있도록 설계된 비자율(TTS) 시스템이다. 사전 학습된 스피커 인코더와 Flan‑T5 텍스트 인코더로부터 얻은 특징을 동일한 timbre 임베딩 공간에 정렬하고, 단일 교차‑어텐션 레이어로 이를 합성 백본에 주입한다. 3단계의 멀티스테이지 학습(음성 사전학습 → 텍스트 정렬 → 공동 파인튜닝)으로 크로스‑모달 정렬을 효율화했으며, 실험 결과 기존 전용 모델들과…
저자: Zihao Zheng, Wen Wu, Chao Zhang
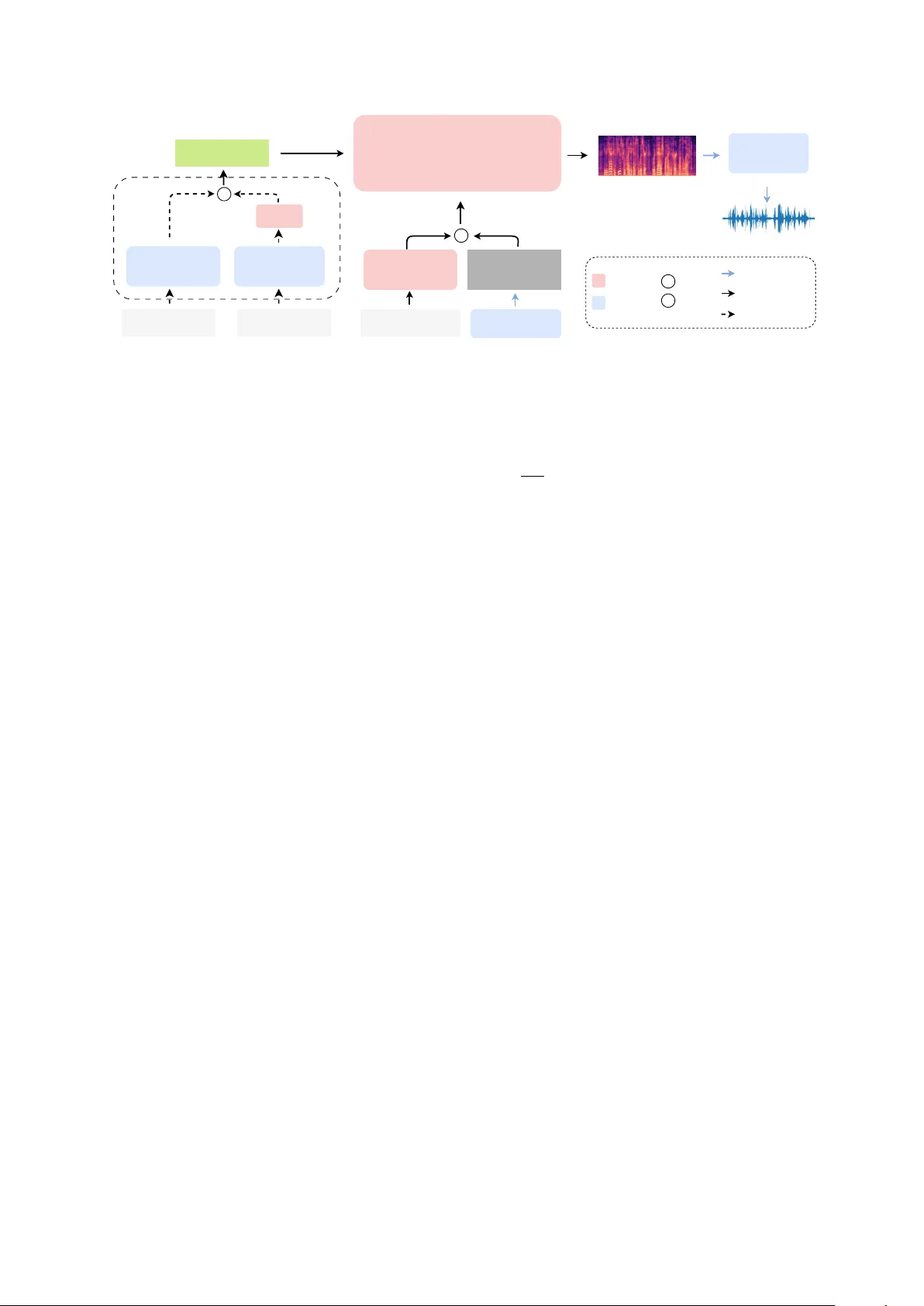
본 논문은 현재 텍스트‑투‑스피치(TTS) 시스템이 음성 프롬프트와 텍스트 프롬프트를 각각 별도 모델로 다루는 한계를 지적하고, 두 종류의 음성 스타일 제어를 하나의 통합 모델에서 처리할 수 있는 새로운 프레임워크 CAST‑TTS를 제안한다. CAST‑TTS는 크게 두 부분으로 구성된다. 첫 번째는 “timbre encoder”로, 음성 프롬프트와 텍스트 프롬프트를 각각 사전 학습된 스피커 인코더와 Flan‑T5 텍스트 인코더를 통해 특징 벡터로 변환한다. 음성 프롬프트는 ECAP‑A‑TDNN(또는 WavLM 기반) 스피커 인코더를 사용해 시퀀스 형태의 timbre 임베딩 T를 생성하고, 텍스트 프롬프트는 Flan‑T5로 인코딩한 뒤 가벼운 선형 프로젝터를 통해 동일 차원의 timbre 임베딩 공간에 매핑한다. 이때 “speech‑rich” 공간을 기준으로 텍스트 임베딩을 정렬함으로써, 텍스트가 제공하는 거친 스타일 정보도 고해상도 음성 특성에 자연스럽게 매핑된다.
두 번째는 Flow‑Matching 기반의 비자율(Non‑Autoregressive) 트랜스포머 백본이다. 입력으로는 noisy mel‑spectrogram M, 문자 임베딩 C, 그리고 timbre 임베딩 T가 들어간다. M과 C는 먼저 self‑attention을 통해 내부 표현을 정제하고, 이후 timbre 임베딩 T와 cross‑attention을 수행한다. 이 단일 cross‑attention 메커니즘이 음성·텍스트 두 모달리티를 동일하게 융합하도록 설계돼, 기존 연구에서 보였던 복잡한 마스킹 전략이나 다중 손실 함수 없이도 안정적인 학습이 가능하다. 백본은 adaLN‑zero 초기화와 긴 skip‑connection을 적용해 깊은 네트워크에서도 그래디언트 소실을 방지한다. 최종적으로 예측된 mel‑spectrogram는 BigVGAN vocoder를 통해 고품질 오디오 파형으로 변환된다.
학습은 세 단계로 진행된다. 1) Speech‑prompt 데이터만 사용해 ConvNeXt‑V2와 트랜스포머를 사전 학습, 기본 음성 생성 능력을 확보한다. 2) Text‑prompt 데이터만으로 프로젝터를 학습, 텍스트 임베딩을 이미 학습된 speech‑derived timbre 공간에 정렬한다. 3) 두 데이터셋을 합쳐 전체 파라미터를 공동 파인튜닝해 크로스‑모달 정합성을 최적화한다. 이 과정에서 스피커 인코더와 Flan‑T5는 frozen 상태를 유지해 사전 지식 손실을 방지한다.
실험에서는 LibriTTS‑R 기반 음성 프롬프트와 CapTTS 기반 텍스트 프롬프트 각각에 대해 평가를 수행했다. 객관적 지표로는 Word Error Rate(WER), Speaker Similarity(SPK‑Sim), Style‑ACC(연령·성별·피치·톤·속도 정확도), UTMOS(음질) 등을 사용했고, 주관적 지표로는 MOS 기반 자연스러움(N‑MOS)과 유사성(Sim‑MOS)을 10명의 청취자를 대상으로 측정했다. 결과적으로 CAST‑TTS는 음성 프롬프트 조건에서 SPK‑Sim 78.4%로 최고 성능을 보였으며, 텍스트 프롬프트 조건에서도 WER 3.89%와 Style‑ACC 91.15%를 기록해 기존 대형 모델들을 앞섰다. Ablation 연구에서는 (1) ECAP‑A‑TDNN 스피커 특징이 mel‑spectrogram보다 스피커 정체성 전달에 유리함을 확인했고, (2) cross‑attention 기반 CAST‑CA 구조가 concat‑self‑attention 기반 CAST‑SA 대비 전반적인 품질과 SPK‑Sim에서 우수함을 입증했다. (3) 멀티스테이지 학습이 단일 end‑to‑end 학습이나 task‑vector 보강 방식보다 일관된 성능 향상을 제공한다는 점도 강조된다.
결론적으로 CAST‑TTS는 복잡한 마스킹이나 다중 손실 없이도 음성·텍스트 두 종류의 프롬프트를 하나의 모델에서 자유롭게 교체·조합할 수 있는 실용적인 프레임워크를 제공한다. 이는 멀티모달 음성 합성, 사용자 맞춤형 TTS 서비스, 그리고 음성·텍스트 기반 스타일 제어 연구에 중요한 기반이 될 것으로 기대된다. 또한, 단일 cross‑attention 메커니즘이 크로스‑모달 정렬을 효율적으로 수행한다는 점은 향후 다른 생성 모델(예: 텍스트‑투‑이미지, 텍스트‑투‑오디오)에도 적용 가능한 일반적인 설계 원칙으로 활용될 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기