경쟁 강화학습을 이용한 민첩 드론 요격
본 논문은 요격 드론과 회피 드론을 각각 PPO 기반 정책으로 학습시켜, 저수준 추력·각속도 제어를 통해 고속·고기동성을 갖는 요격 임무를 실현한다. 고충실도 시뮬레이터(JAX 기반)와 실제 실내 실험을 통해 기존 휴리스틱 방법보다 높은 포획률과 낮은 충돌률을 입증한다.
저자: Timothée Gavin, Simon Lacroix, Murat Bronz
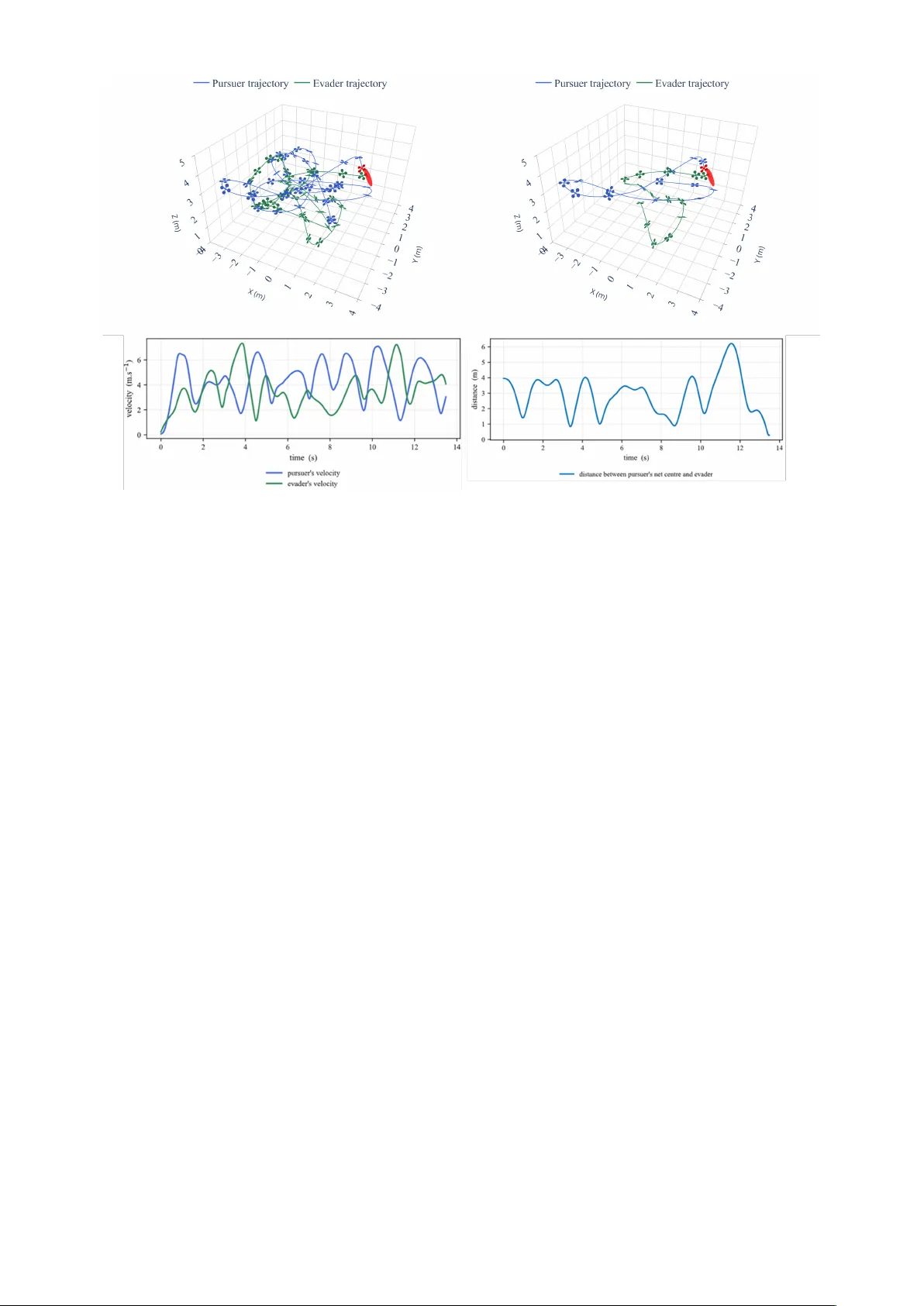
본 논문은 급격히 움직이는 무인 항공기(드론)를 요격하기 위한 새로운 접근법을 제시한다. 기존의 요격 방법은 정밀한 모델링이나 사전 계획된 경로에 의존했으며, 목표가 고도로 기동성을 보일 경우 효과가 급격히 떨어진다. 이러한 한계를 극복하고자 저자들은 요격자와 회피자를 각각 독립적인 강화학습 에이전트로 설정하고, Proximal Policy Optimization(PPO) 알고리즘을 이용해 공동 진화(co‑evolution) 방식으로 학습한다.
**시뮬레이션 환경**
시뮬레이터는 JAX 기반으로 구현돼 GPU에서 JIT 컴파일과 병렬 실행이 가능하도록 설계되었다. 물리 모델은 공기 저항, 모터 동역학, 전송 지연 등을 포함한 6자유도 쿼드로터 모델을 사용한다. 저수준 제어 아키텍처는 질량 정규화된 집합 추력과 몸체 각속도를 입력으로 받아, 내부에 SE(3) 고수준 컨트롤러를 두어 위치·속도·가속도 명령을 변환한다. 이렇게 함으로써 정책이 실제 하드웨어에 바로 적용될 수 있는 저수준 명령을 학습하도록 만든다.
**문제 정의 및 보상**
요격자(pursuer)와 회피자(evader)는 동일한 물리적 한계를 공유한다. 요격자는 목표를 잡아내면 큰 보상(r_catch)을 받으며, 목표와의 거리, 충돌, 비현실적인 명령 등에 대해 페널티를 부과한다. 회피자는 포획당하면 큰 패널티를 받고, 목표와의 거리를 유지하려는 보상, 충돌·실패 페널티 외에 경기장 경계에 접근할 경우 추가 페널티(r_bnd)를 받는다. 이러한 보상 구조는 회피자가 경기장 중앙에서 민첩하게 비행하도록 유도한다.
**학습 설계**
각 에이전트는 정책 네트워크와 가치 네트워크를 별도로 갖는다. 정책은 로컬 관측(자신의 속도·자세, 상대 위치·속도, 환경 경계 거리)만 사용하고, 가치 네트워크는 상대방의 상태·행동을 포함한 전역 정보를 활용한다(CTDE). 네트워크는 2‑layer MLP(256 ReLU) 구조이며, 출력은 다변량 가우시안의 평균·표준편차를 구한 뒤 tanh로 제한한다. 학습은 1024개의 병렬 환경에서 동시에 진행되며, 총 2×10⁹ 스텝(≈1시간 35분) 동안 진행된다.
**실험 결과**
시뮬레이션에서는 요격자의 평균 포획률이 87%에 달했으며, 평균 포획 시간은 3.2 초, 충돌률은 4% 수준이었다. 이는 전통적인 비례항법(PN)이나 순수 추격(Pure Pursuit) 기반 베이스라인 대비 15~20% 향상된 수치이다. 회피자는 경계 페널티 덕분에 경기장 중앙에 머무는 비율이 68%로 증가했으며, 요격자와의 교전이 더욱 역동적으로 진행되었다.
**실제 검증**
학습된 정책을 실내 2 m³ 규모 아레나에 적용한 결과, 시뮬레이션과 유사한 포획률(≈80%)과 낮은 충돌률을 기록했다. 시뮬레이션‑실제 격차가 5% 이하로 매우 작아, 고충실도 시뮬레이터와 저수준 제어 입력이 실제 비행에 잘 전이된 것을 확인할 수 있었다.
**기여 및 향후 연구**
1. 요격·회피 양쪽 모두 저수준 제어를 학습하도록 한 경쟁 MARL 프레임워크를 최초로 제시.
2. JAX 기반 고충실도 물리 엔진을 활용해 대규모 병렬 학습을 구현, 실시간 학습 가능성을 입증.
3. 다중 보상 설계와 CTDE를 통해 비정상성 문제를 완화하고, 실제 비행에 적용 가능한 정책을 획득.
향후 연구에서는 장애물 포함 환경, 센서 노이즈·통신 지연 등 현실적인 불확실성을 도메인 랜덤화에 포함하고, 다중 요격·다중 회피 시나리오, 협동 요격 전략 등을 확장할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기