다이나믹 젠슨섀넌 재생으로 강화학습 다양성 보존
본 논문은 온‑policy 강화학습인 GRPO가 과거 롤아웃을 버리는 비효율성을 개선하기 위해, 시간에 민감한 동적 버퍼와 Jensen‑Shannon 발산 기반 정규화를 결합한 DyJR 프레임워크를 제안한다. DyJR은 최신 샘플만을 FIFO 방식으로 유지하고, 과거 성공 정책을 동적 기준 분포로 삼아 현재 정책과의 JS 발산을 최소화함으로써 다양성 붕괴를 방지한다. 수학 추론 및 Text‑to‑SQL 벤치마크에서 기존 GRPO와 Replay …
저자: Long Li, Zhijian Zhou, Tianyi Wang
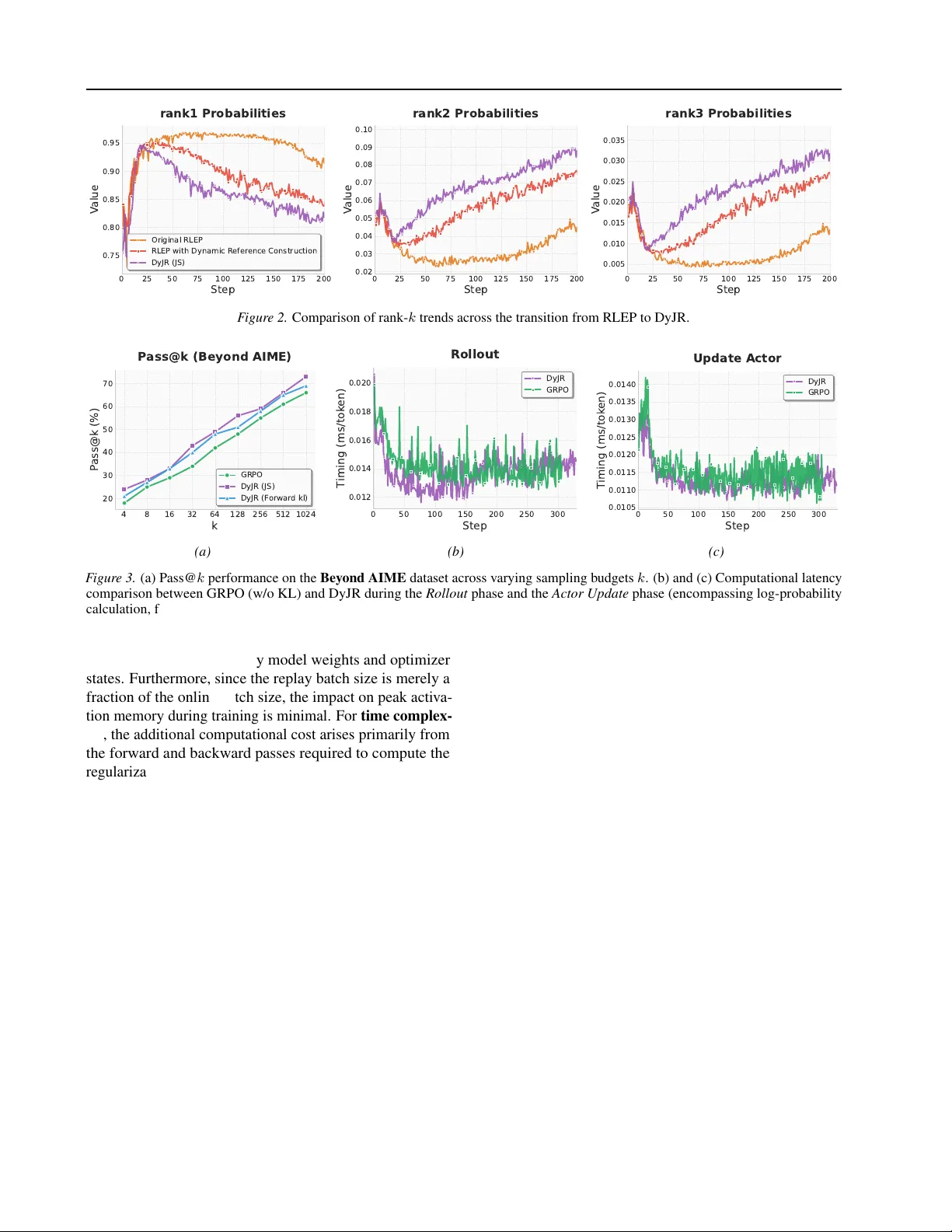
본 논문은 대형 언어 모델(LLM)의 논리적 추론 능력을 강화하기 위해 사용되는 강화학습(RL VR)에서, 온‑policy 알고리즘인 GRPO가 롤아웃 데이터를 한 번만 사용하고 버리는 비효율성을 지적한다. 기존의 Experience Replay 기반 방법들은 과거 샘플을 추가적인 정답 인스턴스로 활용해 정책 업데이트에 직접 사용하지만, 이는 높은 계산 비용과 함께 모드 붕괴(mode collapse)를 초래한다는 문제점을 가지고 있다. 저자들은 “역사적 데이터는 정확성을 강화하기보다 다양성을 유지하는 데 더 큰 가치를 가진다”는 관점을 제시하고, 이를 구현하기 위한 두 가지 핵심 메커니즘을 설계한다.
첫 번째 메커니즘은 **시간‑민감 동적 버퍼(Time‑Sensitive Dynamic Buffer)**이다. 버퍼는 FIFO(First‑In‑First‑Out) 정책을 따르며, ‘Max Age(M)’라는 최대 나이 제한을 두어 최근 M 스텝 이내에 생성된 성공(보상 = 1) 샘플만 보관한다. 또한, 학습 초기(대략 첫 20 스텝)에는 버퍼 용량을 일시적으로 확대하고, 목표 채우기 비율 η를 5%에서 20%로 상승시켜 다양한 탐색 경로를 확보한다. 이후 학습이 진행됨에 따라 버퍼 용량을 점진적으로 축소함으로써 메모리 사용량을 최소화한다. 이 과정에서 각 샘플은 (입력 x, 출력 y, 로그 π_old) 형태로 저장되며, 이는 현재 정책과의 확률 비율을 계산하는 데 필요하다.
두 번째 메커니즘은 **Jensen‑Shannon Divergence Regularization**이다. 기존 Replay 방법이 과거 샘플을 직접 정책 그래디언트에 포함시켜 모드 수축을 일으키는 반면, DyJR은 현재 정책 πθ와 버퍼에 저장된 정책들의 혼합 분포 Q_B 사이의 JS 발산을 최소화한다. JS 발산은 KL 발산의 대칭형이며
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기