계층적 명령 수행을 위한 제약 강화 학습 프레임워크 HIPO
HIPO는 시스템 프롬프트를 명시적 제약으로 다루는 CMDP 기반 강화학습 방법으로, 프라임‑듀얼 최적화를 통해 시스템 준수성을 보장하면서 사용자 요청의 효용을 최대화한다. 다양한 모델(Qwen, Phi, Llama)에서 시스템 준수와 사용자 효용 모두 크게 향상되었으며, 학습 과정에서 모델이 시스템 토큰에 더 많은 어텐션을 할당하는 메커니즘을 발견했다.
저자: Keru Chen, Jun Luo, Sen Lin
본 논문은 대형 언어 모델(LLM)에서 시스템 프롬프트와 사용자 프롬프트가 계층적 우선순위를 갖는 상황, 즉 Hierarchical Instruction Following(HIF) 문제를 다룬다. 기존 RLHF, DPO와 같은 강화학습 기반 정렬 방법은 단일 목표를 최적화하기 때문에 시스템 프롬프트를 절대적인 제약으로 다루지 못한다. 반면, 감독 학습(SFT)은 시스템 준수 데이터를 필터링해 학습하지만, 비준수 데이터를 전혀 활용하지 못하고 우선순위 구조를 알고리즘 수준에서 구현하지 못한다는 한계가 있다.
이를 해결하기 위해 저자들은 HIF를 Constrained Markov Decision Process(CMDP)로 공식화한다. 입력 x는 시스템 프롬프트 x_sys와 사용자 프롬프트 x_user로 구성되며, 정책 πθ는 x를 조건으로 응답 y를 생성한다. 두 개의 보상 함수 r_sys(x,y)와 r_user(x,y)를 정의하고, 시스템 준수 기대값 J_sys(θ)≥τ라는 제약 하에 사용자 효용 J_user(θ)를 최대화한다. 라그랑지안 L(θ,λ)=J_user(θ)+λ(J_sys(θ)−τ)를 도입해 프라임‑듀얼 최적화 문제로 변환한다.
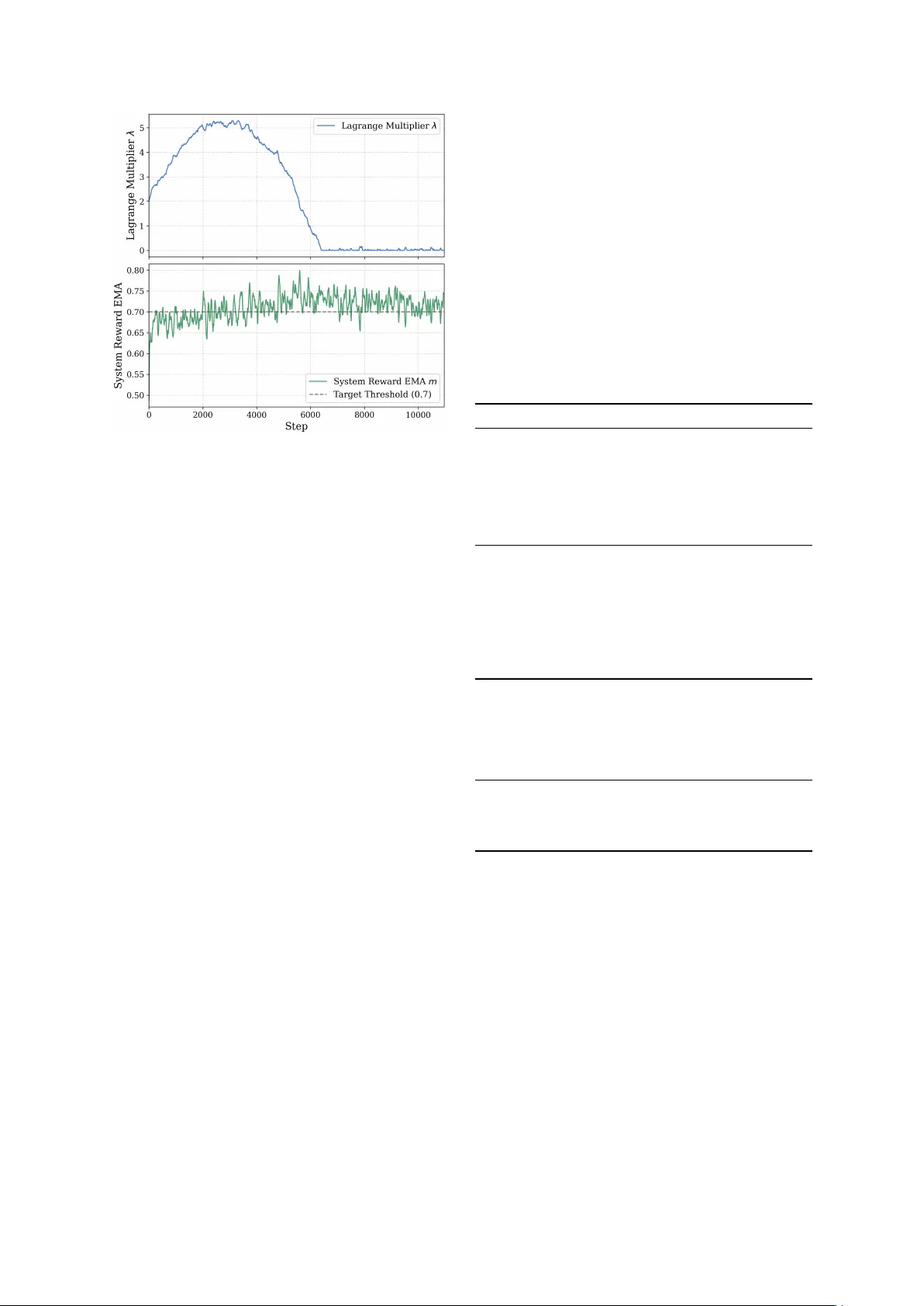
학습 알고리즘인 HIPO는 다음과 같은 핵심 요소를 포함한다. 첫째, 그룹 기반 샘플링(GRPO) 방식을 차용해 각 프롬프트에 대해 G개의 응답을 기존 정책 πθ_old에서 샘플링한다. 둘째, LLM-as-a-Judge 프로토콜을 이용해 시스템 준수와 사용자 효용을 각각 독립적으로 평가한다. 이는 두 평가가 서로 간섭하지 않도록 별도 프롬프트를 사용해 점수를 얻는 방식이다. 셋째, 그룹 내 평균 μ와 표준편차 σ를 이용해 정규화된 어드밴티지 A_user(i), A_sys(i)를 계산하고, 현재 라그랑지 승수 λ_t를 가중치로 하여 결합 어드밴티지 A_comb(i)=A_user(i)+λ_t·A_sys(i)를 만든다. 넷째, PPO 클리핑과 KL 다이버전스 페널티 β를 포함한 surrogate loss를 최적화해 정책 파라미터 θ를 업데이트한다. 다섯째, λ는 시스템 준수 차이를 기반으로 경사 하강법으로 업데이트하며, λ가 0 이하가 되지 않도록 max(0,·) 연산을 적용한다.
실험에서는 Qwen‑3 시리즈(1.7B, 4B, 8B), Phi‑3‑3.8B, Llama‑3.2‑3B 등 다양한 모델에 HIPO를 적용하였다. 평가 지표는 별도의 LLM‑as‑Judge를 통해 측정한 시스템 준수 점수와 사용자 효용 점수이며, 기존 RLHF, DPO, SFT, 그리고 다목적 선형 스칼라화 기법과 비교했다. 결과는 HIPO가 시스템 준수율을 95% 이상 유지하면서도 사용자 효용을 10~20% 향상시키는 것으로 나타났다. 특히, 시스템 준수 임계값 τ를 높게 설정해도 사용자 효용이 급격히 감소하지 않는 점이 주목할 만하다.
메커니즘 분석에서는 학습 전후 모델의 어텐션 분포를 시각화했을 때, HIPO를 적용한 모델이 시스템 프롬프트 토큰에 더 높은 어텐션 가중치를 할당한다는 현상을 발견했다. 이는 제약 최적화가 모델 내부 표현을 자동으로 재조정해, 시스템 제약을 더 잘 인식하도록 만든다는 실증적 증거이다.
논문의 주요 기여는 다음과 같다. (1) HIF를 CMDP로 공식화함으로써 기존 방법이 놓친 계층적 우선순위 구조를 이론적으로 정의했다. (2) 프라임‑듀얼 안전 강화학습과 그룹 기반 어드밴티지 추정을 결합한 HIPO 알고리즘을 제안해, 시스템 준수와 사용자 효용을 동시에 최적화했다. (3) 다양한 모델과 규모에 걸친 광범위한 실험을 통해 제안 방법의 일반성을 입증했고, 어텐션 재배치 메커니즘을 통해 왜 성능이 향상되는지 설명했다.
한계점으로는 LLM-as‑Judge의 품질에 크게 의존한다는 점, λ와 τ 같은 하이퍼파라미터 튜닝이 작업마다 민감할 수 있다는 점, 그리고 현재는 오프라인 데이터셋 기반 학습에 초점을 맞추어 실시간 인터랙션 환경에서의 적용 가능성을 검증하지 않았다는 점을 들 수 있다. 향후 연구에서는 더 견고한 자동 평가 모델 개발, 온라인 학습과 연계한 동적 λ 조정, 그리고 복합적인 다중 제약(예: 안전성, 편향, 비용) 상황에 대한 확장성을 탐구할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기