SWE QA Pro 저장소 수준 코드 이해를 위한 대표 벤치마크와 확장형 학습법
SWE‑QA‑Pro는 장기 저장소 수준의 코드 이해를 평가하기 위해 긴 꼬리(롱테일) 저장소와 실행 가능한 환경을 기반으로 만든 새로운 벤치마크이다. 이 벤치마크는 이슈 기반 클러스터링으로 주제 균형을 맞추고, 직접 답변이 가능한 질문을 필터링해 도구 사용이 필수적인 문제만 남긴다. 또한, 작은 오픈 모델이 효율적인 도구 활용과 추론을 학습하도록 설계된 두 단계(SFT → RLAIF) 훈련 레시피를 제시한다. 실험 결과, Qwen‑3‑8B 모델…
저자: Songcheng Cai, Zhiheng Lyu, Yuansheng Ni
본 논문은 저장소 수준 코드 이해를 평가하고 향상시키기 위한 새로운 벤치마크와 학습 레시피를 제안한다. 기존의 저장소 QA 벤치마크는 인기 있는 몇몇 프로젝트에 편중돼 있어 실제 소프트웨어 엔지니어링 작업에서 나타나는 다양한 문제 유형을 충분히 반영하지 못한다. 또한, 질문에 대해 사전 학습된 LLM이 코드베이스를 탐색하지 않아도 정답을 도출할 수 있는 경우가 많아, 모델이 실제로 저장소를 탐색하고 이해하는 능력을 정확히 측정하기 어렵다.
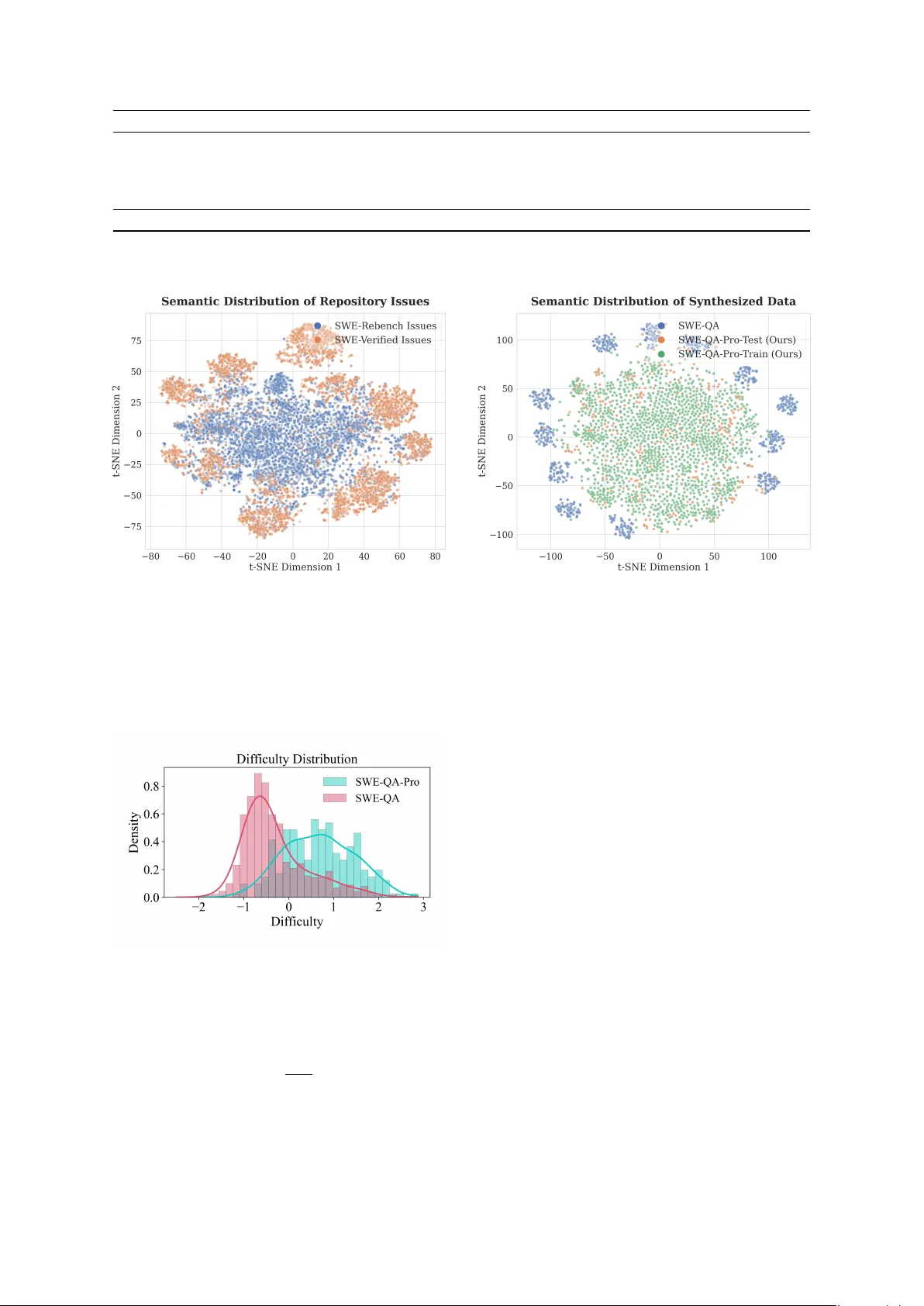
이를 해결하기 위해 저자들은 먼저 ‘긴 꼬리’ 저장소와 실행 가능한 환경을 확보했다. GitHub Issue 데이터를 1,687,638개, 3,468개 저장소에서 수집하고, Qwen‑3‑8B 임베딩을 이용해 두 단계의 K‑Means 클러스터링(10 → 50)을 수행했다. 이후 GPT‑4.1이 자동 라벨링을 수행하고, 인간 검증을 통해 48개의 의미론적 서브클래스를 정의함으로써, 다양한 소프트웨어 엔지니어링 작업(구성 파일 관리, 데이터 파이프라인, 인프라 스크립트 등)을 균형 있게 포함시켰다.
다음으로 질문을 생성하고 난이도를 조정했다. 각 클러스터에서 20개의 이슈를 샘플링해 Claude Code에게 자동으로 새로운 문제‑해답 쌍을 생성하도록 했다. 생성된 질문은 인간 annotator가 검증·수정하고, Claude Code와 인간 답변을 교차 검증해 최종 정답을 확정했다. 이후 직접 답변(툴 없이 한 번에)과 도구 사용(코드 탐색, 파일 검색 등) 두 모델을 비교해, 직접 답변이 높은 점수를 얻는 질문을 자동으로 제외했다. 난이도는 GPT‑4o, Claude Sonnet 4.5, Gemini 2.5 Pro 세 모델의 직접 답변 점수를 Z‑스코어로 정규화하고, 부정적인 합의 점수를 난이도 지표로 삼아 필터링하였다. 이 과정을 거쳐 최종 벤치마크는 260개의 질문(26개 저장소, 4‑9개 질문/클러스터)으로 구성되었으며, 각 질문은 코드베이스 탐색이 필수적인 ‘에이전트 전용’ 문제이다.
훈련 측면에서는 작은 오픈 모델이 효율적인 도구 사용과 다단계 추론을 학습하도록 두 단계 레시피를 설계했다. 첫 단계인 Supervised Fine‑Tuning(SFT)에서는 Claude Sonnet 4.5가 만든 1,000개의 멀티턴 툴 호출 트랜잭션을 Qwen‑3‑8B에 학습시켜, 툴 호출 구문과 기본적인 도구 사용 패턴을 익히게 했다. 두 번째 단계인 Reinforcement Learning from AI Feedback(RLAIF)에서는 동일 질문에 대해 Claude Code가 만든 고품질 레퍼런스 답변을 기준으로 LLM‑as‑Judge가 5가지 평가 차원(정확성, 완전성, 관련성, 명료성, 추론 품질)으로 보상을 산출했다. 보상 설계 시 정확성에 높은 가중치를 부여하고 명료성에 낮은 가중치를 적용해, ‘정답이면서도 간결한’ 답변을 유도하였다.
실험 결과, Qwen‑3‑8B 모델은 이 레시피를 적용했을 때 SWE‑QA‑Pro에서 GPT‑4o보다 2.31점 높은 점수를 기록했으며, Claude Sonnet 4.5와 DeepSeek‑V3.2와의 격차도 크게 축소했다. 특히, 에이전트 워크플로우가 직접 답변보다 평균 13점 높은 차이를 보인 점은, 필터링된 질문이 실제로 코드베이스 탐색을 요구한다는 것을 입증한다. 이는 작은 오픈 모델이라도 적절한 툴 사용과 단계적 추론을 학습하면, 상용 대형 모델에 근접한 성능을 낼 수 있음을 시사한다.
논문의 주요 기여는 다음과 같다. (1) 긴 꼬리 저장소와 실행 가능한 환경을 활용한 고품질 벤치마크 구축, (2) 직접 답변 기반 난이도 캘리브레이션을 통한 도구 사용 필요성 검증, (3) SFT와 RLAIF를 결합한 확장 가능한 훈련 파이프라인 제시. 향후 연구에서는 다중 프로그래밍 언어·프레임워크를 포함한 멀티모달 저장소, 인간 피드백을 결합한 다중 단계 RL, 실시간 코드 실행 결과를 활용한 동적 평가 메트릭 등을 추가해 에이전트 기반 코드 이해의 실용성을 더욱 높일 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기