시각 분류기의 널스페이스 의미 해석: SING 방법
본 논문은 이미지 분류기의 최종 선형 레이어가 가진 널스페이스(불변 공간)를 활용해, 동일한 로짓을 내는 입력 집합을 생성하고 이를 다중모달 비전‑언어 모델(CLIP)과 연결해 인간이 이해할 수 있는 텍스트와 시각 예시로 해석한다. 제안된 SING 프레임워크는 단일 이미지, 클래스별, 모델 전체 수준에서 널스페이스가 얼마나 의미 정보를 “누출”하는지 정량·정성적으로 평가한다. 실험 결과 ResNet‑50은 널스페이스에 의미 속성을 많이 포함하는…
저자: Harel Yadid, Meir Yossef Levi, Roy Betser
**1. 연구 배경 및 동기**
현대의 이미지 분류기는 복잡한 내부 표현을 학습하지만, 이러한 표현이 어떻게 결정 경계에 영향을 미치는지는 여전히 불투명하다. 특히 마지막 선형 레이어의 널스페이스는 입력을 변형해도 로짓을 그대로 유지하는 “불변 집합(equivalent set)”을 만든다. 기존 연구는 널스페이스가 존재한다는 사실만을 확인했으며, 그 안에 어떤 의미가 담겨 있는지는 정량·정성적으로 파악하지 못했다. 의미가 포함된 널스페이스는 모델이 의도치 않은 속성(예: 배경, 색상)에 의존하게 만들며, 이는 공정성·보안 측면에서 위험하다. 따라서 널스페이스의 의미를 인간이 이해할 수 있는 형태로 해석하는 방법이 필요했다.
**2. SING 프레임워크 개요**
SING은 네 단계 파이프라인으로 구성된다.
- **(a) 널스페이스 분해**: 목표 모델의 마지막 FC 레이어 W 에 대해 SVD를 수행한다. 비특이값이 0인 오른쪽 특이벡터 Vₙ 이 널스페이스를 정의하고, 이를 이용해 투영 연산자 Πₙ = VₙVₙᵀ 를 만든다.
- **(b) 피처‑CLIP 변환기 학습**: 원본 피처 f (차원 m)과 동일 이미지에 대한 CLIP 이미지 임베딩 z_img (차원 n)을 매핑하는 선형 변환 T_Θ 를 MSE 손실과 L2 정규화로 학습한다. 선형성 덕분에 널스페이스 성분을 별도로 변환할 수 있다.
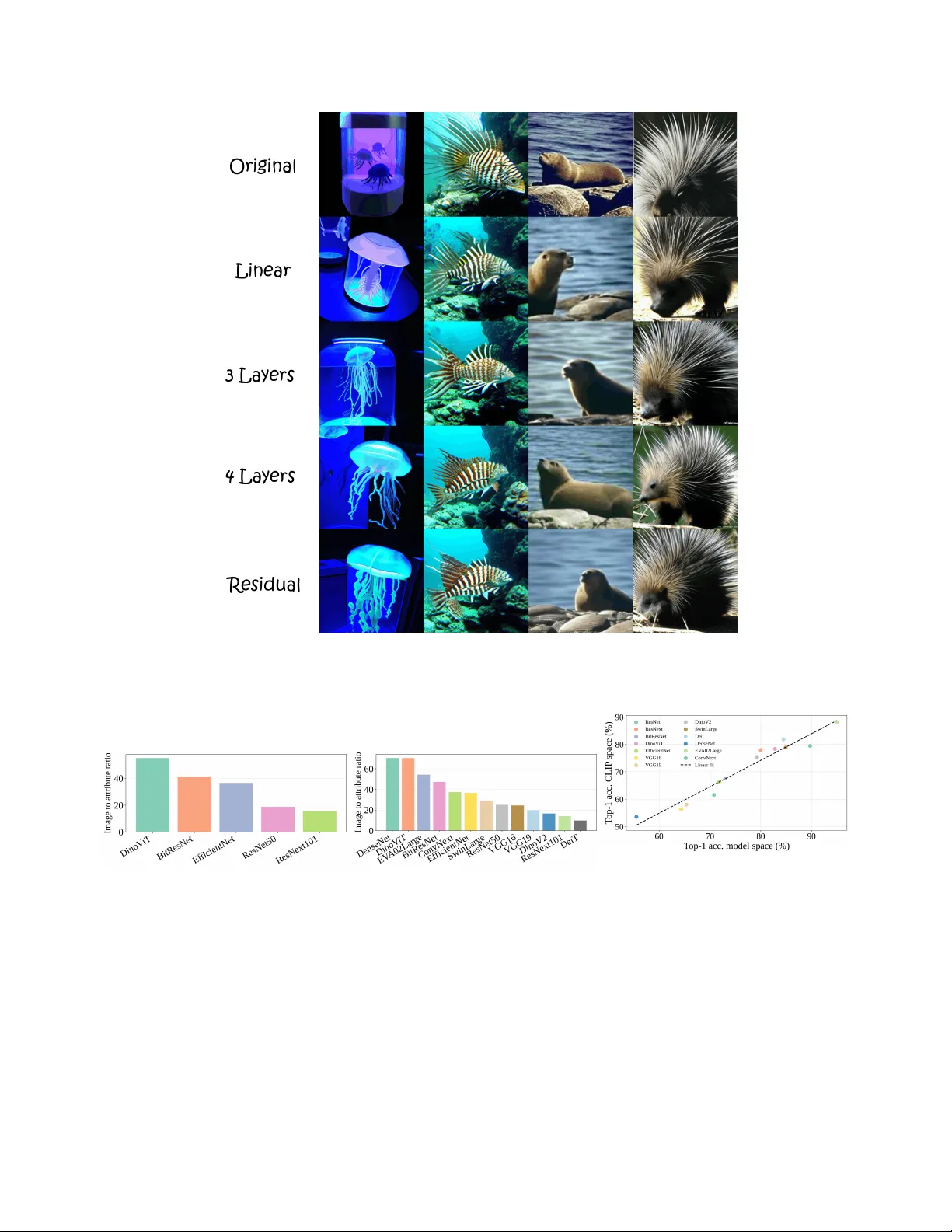
- **(c) 등가 피처 생성**: 원본 피처 f 에 널스페이스 성분 Πₙf 를 빼거나, 원하는 방향 ν ∈ span(Vₙ) 을 더해 등가 피처 \tilde{f} 를 만든다. 두 피처는 W·f = W·\tilde{f} 이므로 로짓이 동일하다.
- **(d) 의미 측정 및 시각화**: 변환기 T_Θ 를 통해 f 와 \tilde{f} 를 CLIP 이미지 임베딩 z_img, \tilde{z}_img 으로 변환하고, 텍스트 프롬프트 z_text (예: “an image of a ”)와의 코사인 각도를 이용해 두 메트릭을 계산한다.
**3. 정의된 메트릭**
- **Attribute Score (AS)**: 텍스트와 원본·변형 이미지 임베딩 사이 각도 차이. 양수이면 변형 이미지가 텍스트와 더 가까워져, 널스페이스에 해당 텍스트와 연관된 의미가 있었음을 의미한다.
- **Image Score (IS)**: 원본과 변형 이미지 임베딩 사이 각도. 널스페이스가 풍부할수록 IS가 크게 나오며, 이는 로짓은 유지하면서도 시각적·의미적 변형이 가능함을 나타낸다.
**4. 실험 설계**
- **모델 비교**: ResNet‑50, ViT‑B/16, DINO‑ViT 등 3가지 대표 모델을 대상으로 16개의 ImageNet 클래스를 무작위 추출해 각 모델의 AS·IS 분포를 측정했다. DINO‑ViT는 AS가 거의 0에 가깝고 IS가 넓게 퍼져 있어, 널스페이스가 비핵심 변이를 허용하지만 클래스 의미는 보존한다는 점을 확인했다. 반면 ResNet‑50은 높은 AS와 비교적 낮은 IS를 보여, 널스페이스에 클래스 의미가 섞여 있음을 드러냈다.
- **클래스·속성 분석**: 각 클래스별로 AS 평균을 구해 “dog”, “bird” 등 특정 클래스가 널스페이스에 얼마나 많은 의미를 포함하는지 정량화했다. 또한 “snow”, “grass”, “urban” 등 열린 어휘 200여 개에 대해 원본·변형 피처 간 각도를 측정해, 널스페이스가 특정 환경 속성(예: 배경)과 강하게 연관되는 경우를 시각화했다.
- **단일 이미지 진단**: 몇몇 오분류 사례에 대해 널스페이스 제거 전후 이미지를 생성하고, AS·IS 값을 확인함으로써 왜 모델이 특정 속성에 과도하게 의존했는지 설명했다. 예를 들어, 배경에 “snow”가 있는 이미지에서 널스페이스를 제거하면 클래스 프롬프트와의 AS가 크게 감소하고, 모델이 “dog”을 올바르게 인식하게 되었다.
**5. 널스페이스 조작 가능성**
SING은 널스페이스를 이용해 의미를 은닉하는 방향으로도 활용될 수 있음을 보였다. 특정 텍스트 임베딩 z_text 에 대한 반대 방향 ν ∈ span(Vₙ) 을 선택해 원본 피처에 더하면, 로짓은 변하지 않지만 CLIP 이미지 임베딩에서는 해당 의미가 사라진다. 이는 “비밀스러운” 속성을 모델에 숨기면서도 예측 성능을 유지하는 기술적 가능성을 시사한다.
**6. 결론 및 의의**
SING은 (1) 널스페이스를 직접 탐색해 의미를 추출, (2) 멀티모달 언어 모델을 브릿지로 활용해 인간 친화적인 텍스트·시각 예시를 제공, (3) AS·IS라는 두 축의 정량적 지표로 모델·클래스·이미지 수준에서 의미 누출을 체계적으로 비교·진단한다는 세 가지 핵심 기여를 한다. 이를 통해 연구자는 모델 선택 시 “의미 보존 vs 의미 누출” 트레이드오프를 명확히 파악할 수 있으며, 향후 모델 보안·공정성·디버깅 도구로 확장될 여지를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기