다중 단계 검색을 위한 에이전트 플래닝과 실행: APEX‑Searcher
APEX‑Searcher는 복잡한 다중 홉 질문에 대해 검색 과정을 ‘계획’과 ‘실행’ 두 단계로 분리한다. 계획 단계에서는 강화학습과 과제 분해 보상을 이용해 최적의 서브‑태스크 시퀀스를 생성하고, 실행 단계에서는 고품질 다중 홉 데이터에 대한 지도학습(SFT)으로 각 서브‑태스크를 반복적으로 수행한다. 실험 결과, 기존의 단일 라운드 혹은 엔드‑투‑엔드 학습 기반 RAG보다 다중 홉 QA와 에이전트 플래닝 모두에서 크게 향상된 성능을 보였다…
저자: Kun Chen, Qingchao Kong, Zhao Feifei
1. 서론
대형 언어 모델(LLM)은 방대한 사전 학습을 통해 다양한 언어 이해·생성 능력을 보이지만, 지식이 파라미터에 고정돼 있어 최신 정보 접근이 어렵고, 훈련 분포를 벗어난 질문에 대해 허위 정보를 생성하는 ‘환각(hallucination)’ 문제가 있다. 이를 보완하기 위해 Retrieval‑Augmented Generation(RAG)이 도입되었으며, 외부 지식베이스(예: 위키피디아)와 결합해 정확성을 높인다. 그러나 전통적인 RAG는 단일 라운드 검색에 의존해 복잡한 다중 홉 질문을 처리하기에 한계가 있다.
2. 관련 연구
- 표준 RAG: 인덱싱‑검색‑생성 3단계 파이프라인으로, 단일 검색으로 충분한 정보를 얻을 수 있는 단순 질의에 적합하지만, 다중 홉 질문에서는 정밀도·재현율이 떨어진다.
- 반복 RAG(Iterative RAG): 질문‑답변‑재질문을 반복해 점진적으로 컨텍스트를 확장한다. HotpotQA 등에서 성능 향상을 보였지만, 반복 과정에서 의미적 불연속과 불필요한 정보 축적 문제가 존재한다.
- 에이전트형 RAG(Agentic RAG): LLM이 도구(검색 엔진)를 언제 호출할지 스스로 판단하도록 설계돼, 장기 목표 달성에 유리하지만 명확한 사전 플랜이 없어서 작업 망각, 반복 검색 등 비효율이 발생한다.
- 플래닝 연구: 구조화된 지식이나 메타‑학습을 활용해 계획 능력을 강화하려는 시도가 있었지만, 다중 라운드 검색에 플래닝을 적용한 사례는 드물다.
3. APEX‑Searcher 개요
APEX‑Searcher는 “Agentic Planning + Iterative Sub‑Task Execution”이라는 두 단계 프레임워크를 제안한다.
- **계획 단계**: 복잡한 질문 Q를 서브‑태스크 시퀀스 S={s₁,…,sₙ}으로 분해한다. 이를 순차적 의사결정 문제로 보고, 강화학습(RL) 기반의 Planning Agent가 정책 πₚₗₐₙ을 학습한다. 정책 최적화에는 Group Relative Policy Optimization(GRPO)을 사용해 가치 함수를 별도로 학습하지 않고, 동일 프롬프트에 대한 다중 샘플의 평균 보상을 기준선으로 삼는다. 보상은 인간 주석 플랜과 생성 플랜 사이의 F1‑스코어(의미 유사도 기반)로 정의된다.
- **실행 단계**: 분해된 각 서브‑태스크를 반복 검색‑생성 루프를 통해 해결한다. 여기서는 고품질 다중 홉 데이터셋을 이용해 Supervised Fine‑Tuning(SFT)으로 모델을 미세조정한다. SFT는 “약한 추론·강한 구조” 특성을 가진 작업(쿼리 생성, 문서 추출, 답변 합성 등)에 명시적 지도 신호를 제공해, RL 단계에서 발생할 수 있는 오류 누적을 방지한다.
4. 기술 상세
- **GRPO 수식**: 정책 파라미터 θ를 업데이트할 때, 동일 질문에 대해 G개의 출력 oᵢ를 샘플링하고, 각 출력에 대한 상대 보상 Aᵢₜ을 계산한다. KL‑다이버전스 정규화(β)와 클리핑(ε) 기법을 적용해 안정성을 확보한다.
- **플랜 프롬프트**: “복잡한 문제를 2‑4개의 서브‑문제로 분해하고, #1, #2 형태로 이전 서브‑문제의 답을 참조하라”는 형식으로 LLM이 구조화된 플랜을 생성하도록 유도한다.
- **보상 설계**: 인간 주석 플랜 S_gold와 모델 생성 플랜 S_gen 사이의 의미적 유사도 Cᵢⱼ를 문장‑Transformer로 인코딩한 뒤, F1‑스코어를 산출한다. 이는 플랜의 정확도와 완전성을 동시에 평가한다.
- **SFT 커리큘럼**: 다중 홉 QA 데이터(HotpotQA, Musique 등)를 기반으로, 각 서브‑태스크에 대해 입력‑출력 쌍을 제공한다. 모델은 “쿼리 → 검색 → 답변” 흐름을 학습하며, 동적 종료 판단(continue/stop)과 컨텍스트 관리(이전 서브‑답변 통합)도 함께 학습한다.
5. 실험 및 결과
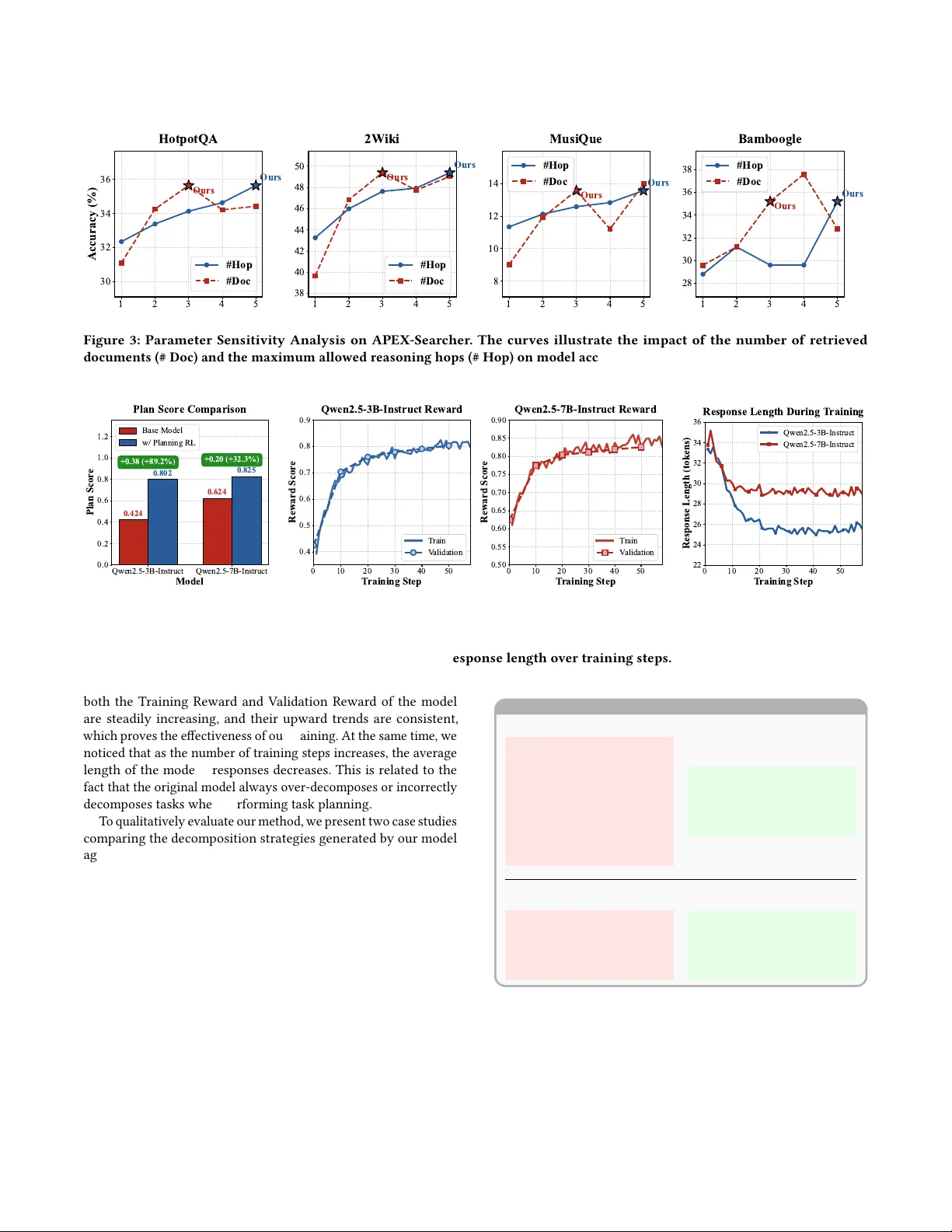
- **벤치마크**: HotpotQA, ComplexWebQuestions, Musique 등 3가지 다중 홉 QA 데이터셋에서 기존 최첨단 모델(Iter‑RAG, Search‑R1 등) 대비 평균 4‑7% 절대 정확도 향상을 기록했다.
- **플래닝 평가**: 계획 단계에서 생성된 플랜의 F1‑스코어가 0.85 이상으로, 인간 주석과 높은 일치도를 보였다. 이는 전체 시스템이 불필요한 검색 루프에 빠지는 현상을 크게 감소시켰다.
- **효율성**: RL 단계는 2‑3 epoch만에 수렴했으며, SFT 단계는 기존 단일 모델 대비 30% 적은 학습 시간으로 동일 수준 이상의 성능을 달성했다.
- **소규모 모델 적용**: LLaMA‑7B 기반 APEX‑Searcher도 LLaMA‑13B 기반 모델에 근접한 성능을 보여, 프레임워크의 모델‑독립성을 확인했다.
6. 결론 및 향후 연구
APEX‑Searcher는 “계획 + 실행”이라는 명확한 구조와 각각에 최적화된 학습 전략(RL + SFT)을 통해 다중 홉 질문에 대한 검색·추론 효율을 크게 개선하였다. 플래닝 단계에서의 명시적 목표 설정이 실행 단계의 오류 전파를 억제하고, SFT가 제공하는 구조적 지도는 RL의 희소 보상 문제를 보완한다. 향후 연구에서는 플래닝 단계에 메타‑학습을 도입해 새로운 도메인에 대한 적응성을 높이고, 비언어적 도구(예: 데이터베이스 쿼리, 코드 실행)와의 연계도 탐색할 계획이다.
---
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기