CTI REALM AI 에이전트 탐지 규칙 생성 능력 평가 벤치마크
CTI-REALM은 사이버 위협 인텔리전스(CTI)를 해석하고 실시간 탐지 규칙을 작성하는 AI 에이전트를 평가하기 위한 벤치마크이다. 실제 공격 시뮬레이션 로그와 CTI 보고서를 제공하고, 에이전트가 단계별 도구를 사용해 Sigma와 KQL 규칙을 생성하도록 설계되었다. 최종 탐지 정확도와 중간 체크포인트 기반 보상이 함께 측정되며, 16개 최신 LLM 모델을 실험한 결과 Claude Opus 4.6이 가장 높은 0.637 점수를 기록했다. …
저자: Arjun Chakraborty, S, ra Ho
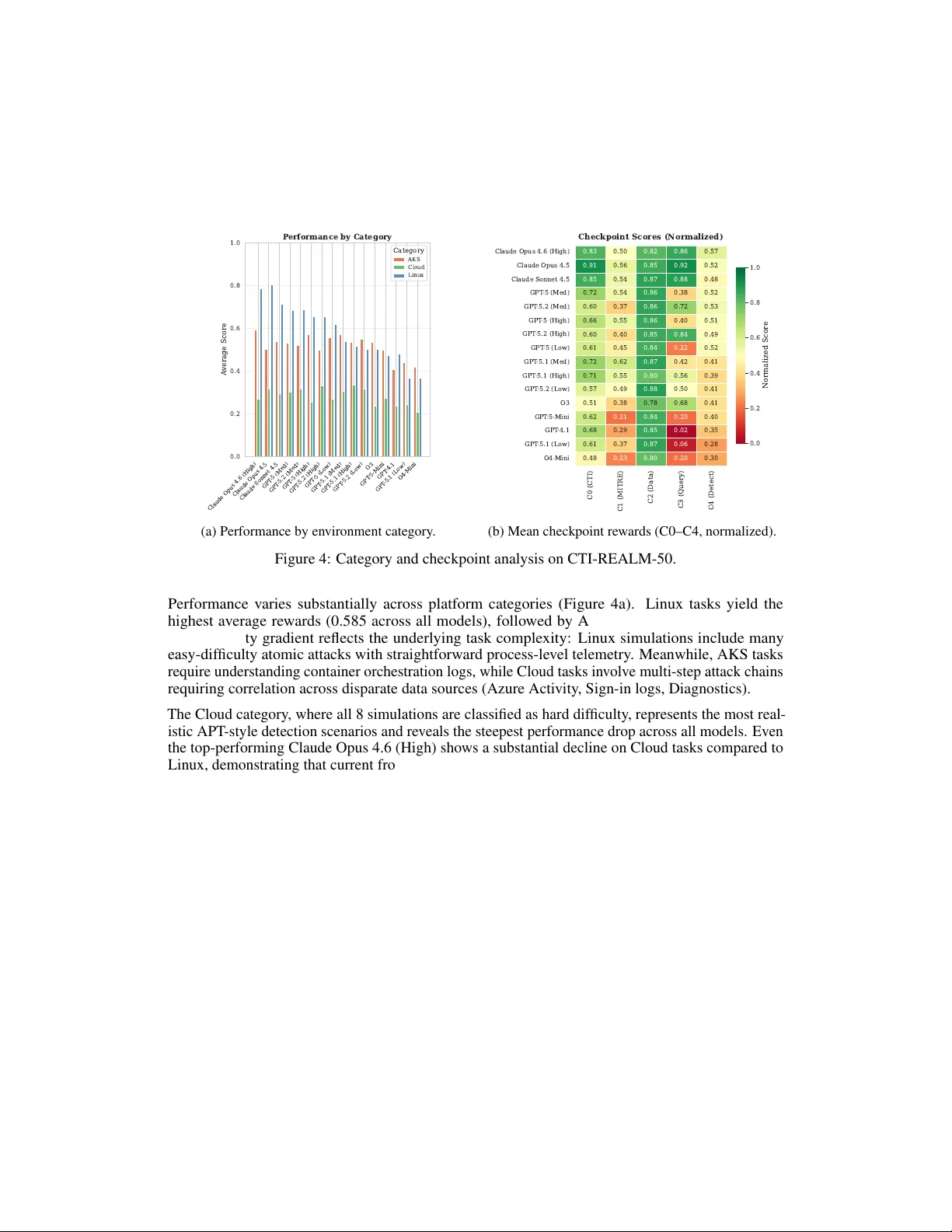
이 논문은 사이버 위협 인텔리전스(CTI)를 해석하고 실시간 탐지 규칙을 생성하는 AI 에이전트를 평가하기 위해 설계된 CTI-REALM 벤치마크를 소개한다. 기존 사이버 보안 벤치마크는 주로 지식 기반 질문이나 단일 단계 규칙 생성에 초점을 맞추었지만, 실제 보안 분석가가 수행하는 복합적인 워크플로우—CTI 보고서 분석, 데이터 소스 탐색, 쿼리 작성, 규칙 검증—를 포괄하지 못했다. CTI-REALM은 이러한 전체 파이프라인을 재현함으로써 모델의 종합적인 탐지 엔지니어링 능력을 측정한다.
데이터셋은 37개의 공개 CTI 보고서와 Microsoft, Datadog, Palo Alto, Splunk 등에서 제공된 검증된 탐지 규칙을 기반으로 구성되었다. 각 보고서는 Linux 엔드포인트, Azure Kubernetes Service(AKS), Azure 클라우드 인프라에서 실제 공격 시뮬레이션을 통해 생성된 로그와 매핑된다. 시뮬레이션은 Atomic Red Team 테스트를 변형하여 단일 단계 공격부터 복잡한 다단계 침투 시나리오까지 포함한다. 난이도는 Easy, Medium, Hard 세 단계로 구분되며, Cloud 시나리오는 특히 Hard 수준에 해당한다.
벤치마크는 두 개의 평가 세트, CTI-REALM‑25와 CTI-REALM‑50을 제공한다. 전자는 빠른 프로토타이핑을 위한 소규모 샘플이며, 후자는 전체 난이도와 플랫폼을 포괄하는 확장된 평가이다. 평가 환경은 Docker 기반 컨테이너에 구현되어, CTI 저장소, Kusto 클러스터, 다양한 로그 소스, MITRE ATT&CK 데이터베이스, Sigma 규칙 DB 등을 포함한다. 에이전트는 8가지 전용 API(CTI 검색, 스키마 조회, KQL 실행 등)를 통해 이 환경과 상호작용한다.
평가 프레임워크는 탐지 규칙 생성을 마르코프 결정 과정(MDP)으로 모델링하고, C0~C4 다섯 개 체크포인트에 가중치를 부여한 보상 함수를 정의한다. C0는 CTI 보고서의 핵심 정보를 올바르게 식별했는지를 LLM‑as‑judge로 평가하고, C1은 MITRE ATT&CK 기술 매핑을 Jaccard 유사도로 측정한다. C2는 관련 로그 소스와 필드를 정확히 찾아냈는지를, C3은 최소 두 번 이상의 성공적인 쿼리 실행을 보상한다. 최종 C4는 생성된 Sigma와 KQL 규칙의 탐지 정확도를 F1‑score와 LLM‑as‑judge를 결합해 점수화한다. 전체 보상은 0~1 사이이며, 중간 체크포인트는 정책 학습을 위한 신호로 활용될 수 있다.
실험에서는 16개의 최신 LLM 모델을 동일한 ReAct 기반 에이전트에 탑재해 CTI-REALM‑50 전체에 적용하였다. 모델은 Anthropic Claude Opus 4.6(High), Opus 4.5, Sonnet 4.5와 OpenAI GPT‑5 시리즈(5, 5.1, 5.2 각 고·중·저 추론 노력), GPT‑5‑Mini, GPT‑4.1, O3, O4‑Mini 등을 포함한다. 각 모델은 최대 70개의 메시지(툴 호출 및 생각 기록) 제한 하에 작업을 수행했다. 결과는 Claude Opus 4.6이 0.637의 최고 점수를 기록했으며, Opus 4.5가 0.624, GPT‑5 고성능 변형이 그 뒤를 이었다.
주요 발견은 다음과 같다. 첫째, CTI‑specific 툴을 비활성화한 경우 전체 보상이 평균 12% 감소했으며, 이는 도구가 모델의 추론을 실질적으로 보강한다는 증거다. 둘째, 메모리 증강(사전 컨텍스트 제공) 실험에서 작은 모델의 성능 격차가 33% 감소했으며, 이는 프롬프트 엔지니어링과 외부 지식 주입이 모델 효율성을 크게 향상시킬 수 있음을 보여준다. 셋째, 동일 모델을 여러 번 실행한 변동성 분석에서 대부분의 모델이 0.02 이하의 표준편차를 보이며 결과가 안정적이었다.
논문의 한계로는 현재 Azure 전용 인프라에 초점을 맞추어 다른 클라우드 환경(예: AWS, GCP)으로의 일반화가 제한적이며, LLM‑as‑judge의 주관적 평가가 일부 편향될 가능성이 있다. 또한 70 메시지 제한이 실제 SOC 작업량과 정확히 일치하지 않을 수 있다. 향후 연구 방향은 멀티클라우드 시나리오 확대, 인간‑에이전트 협업 인터페이스 설계, 강화학습 기반 정책 최적화, 그리고 LLM‑as‑judge의 객관성 강화 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기