AI라이브 믹서 실시간 무지연 자동 음악 믹싱 시스템
본 논문은 라이브 공연에서 발생하는 악기 간 음향 누설(bleed)과 영상·음향 동기화 요구를 해결하기 위해, 제로 레이턴시(Zero‑Latency)로 동작하는 딥러닝 기반 자동 멀티트랙 믹싱 모델인 AiLive Mixer(ALM)를 제안한다. 기존 오프라인 전용 자동 믹싱 시스템과 달리, ALM은 두 단계의 프레임 레이트(Multi‑Rate)와 트랜스포머‑인코더, GRU, RMS 조건화 등을 결합해 채널 간 상호관계와 시간적 맥락을 학습한다.…
저자: Devansh Zurale, Iris Lorente, Michael Lester
**1. 연구 배경 및 목적**
음악 믹싱은 원시 오디오 트랙의 볼륨 균형, 이펙트 적용 등을 통해 최종 사운드를 완성하는 복합 작업이며, 전문 엔지니어의 숙련도가 필요하다. 최근 딥러닝 기반 자동 믹싱(Automatic Music Mixing, AMM) 연구가 활발히 진행됐지만, 대부분은 스튜디오 환경에서 격리된 트랙을 전제로 오프라인 처리에 초점을 맞추었다. 라이브 공연에서는 악기들이 동일 공간에 배치돼 마이크 간에 음향 누설(bleed)이 발생하고, 영상·음향 동기화를 위해 레이턴시가 10 ms 이하로 제한된다. 이러한 두 가지 제약을 동시에 만족하는 시스템은 아직 존재하지 않는다. 본 논문은 이러한 공백을 메우기 위해 ‘제로 레이턴시 자동 멀티트랙 믹서’를 설계·구현하고, 실시간 라이브 환경에서의 성능을 검증한다.
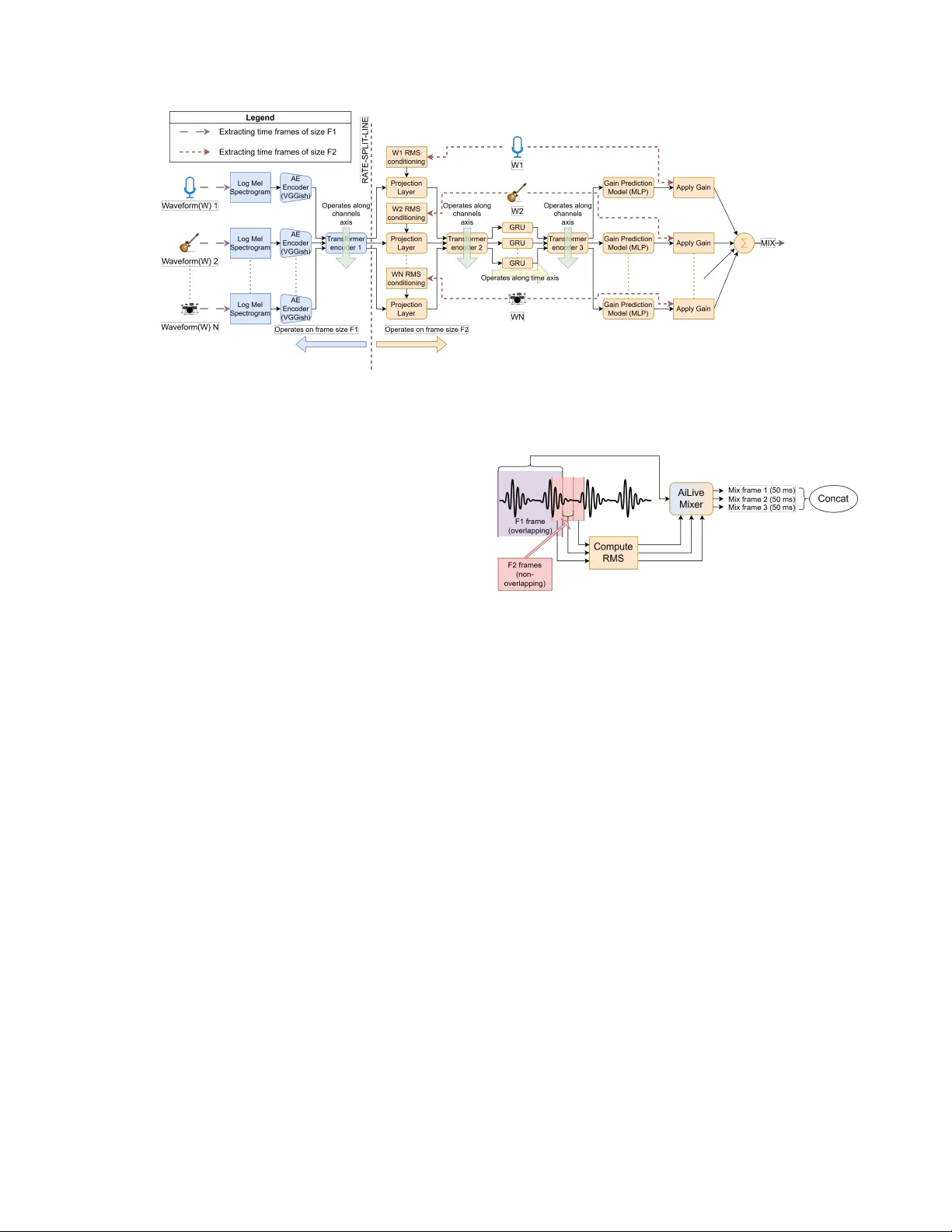
**2. 시스템 개요 – AiLive Mixer (ALM)**
ALM은 기존 Differentiable Mixing Console(DMC) 구조를 기반으로 하면서, 다음과 같은 주요 개선점을 도입한다.
- **멀티‑Rate 처리**: 입력 채널당 두 종류의 프레임을 사용한다. 긴 프레임(F₁ = 975 ms)은 VGGish 기반 오디오 임베딩과 첫 번째 트랜스포머‑인코더에 투입돼 악기 종류와 전반적인 스펙트럼 정보를 추출한다. 짧은 프레임(F₂ = 50 ms)은 RMS 레벨, GRU, 두 번째·세 번째 트랜스포머‑인코더, 그리고 최종 MLP에 전달돼 실시간 이득(gain) 예측을 수행한다. F₁ 프레임은 300 ms마다 새로 추출해 계산량을 제어한다.
- **제로 레이턴시 학습**: 모델은 현재 F₂ 프레임을 입력받아 다음 F₂ 프레임에 적용될 이득값을 미리 예측하도록 훈련한다. 추론 시에는 이미 예측된 이득을 즉시 적용하므로, 입력이 들어오는 순간 바로 믹스가 생성돼 실질적인 ‘제로’ 지연을 달성한다.
- **채널·시간 컨텍스트 학습**:
* **RMS 조건화**: 각 채널의 RMS 값을 선형 변환·PReLU 활성화 후 임베딩에 결합해 레벨 정보를 보강한다.
* **GRU**: 단일 레이어(숨김 크기 128)로 시간적 흐름을 모델링한다. 특히 제로 레이턴시 상황에서 미래 프레임을 예측하는 데 필수적이다.
* **트랜스포머‑인코더**: 3곳에 배치(임베딩 직후, RMS 후, GRU 후)해 채널 축을 따라 self‑attention을 수행한다. 각 인코더는 1 레이어, 2 헤드로 구성돼 채널 간 상호작용을 효율적으로 학습한다.
- **Gain Prediction MLP**: 3개의 은닉층(128‑64‑32)과 ReLU 출력으로 각 채널당 단일 스칼라 이득을 예측한다.
**3. 데이터 및 누설 시뮬레이션**
훈련에는 MedleyDB의 격리 트랙을 사용한다. 실제 라이브 환경에서 발생하는 누설은 방 크기, 리버브, 마이크·악기 거리 등 복합 요인에 의해 달라지므로, pyroomacoustics 기반 파라메트릭 시뮬레이터를 구축해 실시간으로 누설 파라미터를 무작위화한다. 이렇게 생성된 ‘bleed‑augmented’ 트랙은 원본 믹스(ground truth)와 동일한 믹스 레퍼런스로 사용한다. 입력 레벨도 누설 전·후 모두 랜덤하게 조정해 다양한 스테이징 상황에 대비한다.
**4. 학습 설정**
- **데이터 분할**: 43곡(≤8채널) 중 35곡을 훈련, 8곡을 검증에 사용.
- **옵티마이저**: AdamW, 초기 학습률 0.001, 100, 1000, 2500 epoch에서 10배 감소.
- **손실 함수**: 멀티‑해상도 STFT 손실(윈도우 440, 884, 3528 샘플)과 25% hop, FFT 크기 512/1024/4196을 결합해 주파수·시간 정확도를 동시에 최적화.
- **VGGish 파인튜닝**: 처음 100 epoch은 고정, 이후 전체 모델과 동일 학습률로 해제해 특화된 누설 정보를 학습한다.
**5. 실험 및 평가**
네 가지 모델을 비교했다.
1) **ALM‑MR**: 멀티‑Rate + 제로 레이턴시 (제안 모델)
2) **ALM‑SR**: 단일‑Rate + 제로 레이턴시
3) **DMC‑B‑0L**: DMC 구조에 누설 시뮬레이션·제로 레이턴시 적용
4) **DMC‑OG**: 원본 DMC (오프라인, 누설 없음)
모든 모델은 mono gain만 예측하도록 통일했다. 평가에는 15명의 오디오 전문가·뮤지션을 대상으로 8곡·20‑30초 구간을 5가지 믹스(ALM‑MR, ALM‑SR, DMC‑B‑0L, DMC‑OG, RAW)로 청취하게 했다. 평가 방식은 APE 테스트 설계에 기반한 절대 평점(0‑1)이며, 각 참가자는 곡당 모든 모델을 무작위 순서로 들었다.
**결과**
- **ALM‑MR** 평균 평점 ≈ 0.75, 가장 높은 군집을 형성.
- **ALM‑SR**는 평균 ≈ 0.68, 다소 퍼진 분포지만 DMC·RAW보다 우수.
- **DMC‑B‑0L**와 **DMC‑OG**는 각각 ≈ 0.48, 0.42 수준.
- **RAW**는 ≈ 0.35, 가장 낮음.
통계적 검증: Kruskal‑Wallis H = 156.485, p = 8.29 × 10⁻³³ (유의미). 사후 검정(Conover)에서 ALM‑MR과 ALM‑SR은 모든 다른 모델과 p < 0.01로 차이가 뚜렷했다.
**6. 논의 및 향후 과제**
ALM‑MR이 멀티‑Rate와 제로 레이턴시를 결합함으로써, 실제 라이브 상황에서의 누설 처리와 즉각적인 믹스 제공에 성공했다는 점이 핵심이다. 트랜스포머‑인코더를 채널 축에 여러 번 배치한 설계가 누설된 신호 간 상관관계를 효과적으로 학습했으며, GRU 기반 시간 컨텍스트가 미래 프레임 예측을 가능하게 했다. 현재는 mono gain만을 예측하지만, DMC와 동일한 구조를 유지하고 있어 panning, EQ, 컴프레서 등 추가 파라미터를 확장하기 용이하다. 또한, 실제 공연에서의 마이크 배치·방향성 마이크·다중 스피커 환경 등 더 복잡한 상황을 데이터에 포함시키면 모델의 일반화 능력이 더욱 강화될 것이다.
**7. 결론**
본 논문은 라이브 공연용 자동 믹싱 시스템을 최초로 제안하고, 멀티‑Rate 처리와 제로 레이턴시 학습을 통해 50 ms 이하의 실시간 지연으로 누설이 포함된 멀티트랙을 효과적으로 믹싱한다는 것을 입증했다. 청취 테스트 결과는 제안 모델이 기존 DMC 기반 시스템 및 원시 믹스보다 현저히 우수함을 보여준다. 향후 연구는 현재의 mono gain 예측을 넘어 다중 이펙트 파라미터를 동시에 제어하고, 실제 공연 현장에서의 실시간 피드백 루프를 구축하는 방향으로 진행될 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기