데이터 증강으로 강인한 발음장애 음성 심각도 추정
발음장애 음성 품질 평가(DSQA)는 임상 진단과 포괄적 음성 기술에 필수적이지만, 라벨링된 데이터가 부족해 객관적 모델 구축이 어렵다. 본 논문은 라벨이 없는 발음장애 음성과 대규모 정상 음성(LibriSpeech)을 활용해 세 단계 학습 프레임워크를 제안한다. 1) 제한된 라벨 데이터로 Whisper‑large 기반 교사 모델을 학습해 비라벨 데이터에 의사라벨을 부여하고, 2) 의사라벨과 정상 음성을 결합해 라벨 인식 대비형 대비학습(lab…
저자: Jaesung Bae, Xiuwen Zheng, Minje Kim
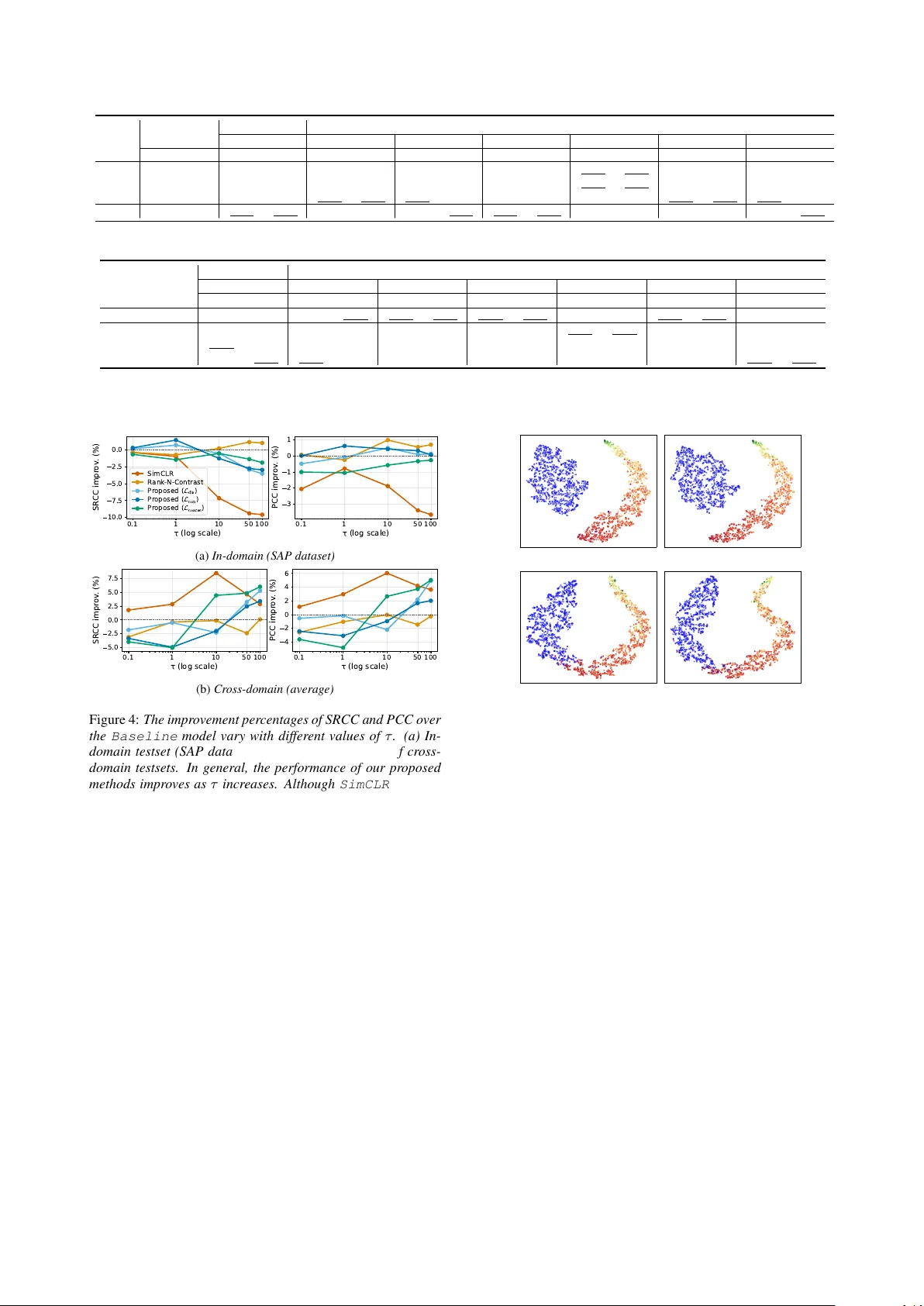
본 논문은 발음장애(dysarthria) 음성의 심각도 수준을 자동으로 추정하는 DSQA(Dysarthric Speech Quality Assessment) 시스템을 설계하고, 라벨이 부족한 현실적인 상황에서도 강인하게 동작하도록 데이터 증강과 약한 지도 학습을 결합한 새로운 프레임워크를 제안한다.
1. **배경 및 문제점**
- 발음장애는 신경학적 손상으로 인한 음성 운동 장애이며, 임상 진단·재활·포괄적 음성 기술에 있어 정확한 음성 품질 평가가 필수적이다.
- 기존 DSQA는 전문가(SLP)의 주관적 평가에 의존해 비용이 높고 확장성이 낮다. 라벨이 있는 데이터는 극히 제한적이며, 특히 다양한 언어·병리학을 포괄하는 데이터는 거의 없다.
- 최근 비침입형 음성 품질 평가(NI‑SQA) 모델(DNSMOS, UTMOS 등)과 대규모 음성 기반 대비학습(SimCLR, wav2vec2.0, HuBERT) 기술이 발전했지만, 이들은 주로 정상 음성에 최적화돼 발음장애 특성을 충분히 포착하지 못한다.
2. **데이터 구성**
- **SAP( Speech Accessibility Project )**: 라벨이 있는 10.8시간(약 4.6%)과 라벨이 없는 232.9시간을 포함하는 대규모 발음장애 음성 코퍼스. 라벨은 ‘자연스러움’과 ‘이해도’ 두 가지 7점 척도이며, 평균값을 최종 심각도 점수로 사용한다.
- **LibriSpeech**: 921.7시간 규모의 정상 영어 음성 데이터로, 스피커·채널 다양성을 제공한다.
- **Cross‑Domain 테스트셋**: UASpeech(영어, 뇌성마비), DysArinVox(중국어, 다중 병리), EasyCall(이탈리아어, 파킨슨·헌팅턴 등), EW‑ADB(체코·슬로바키아어, 알츠하이머·파킨슨·경도인지장애), NeuroVoz(스페인어, 파킨슨 H‑Y 단계) 등 5개 데이터셋을 사용해 언어·병리학 전이 성능을 평가한다.
3. **제안 프레임워크**
- **Stage 1 – Pseudo‑labeling**: 제한된 라벨 SAP 데이터를 이용해 Whisper‑large(대규모 트랜스포머 기반 음성 인코더)를 회귀 교사 모델로 학습한다. 교사 모델은 라벨이 없는 SAP 샘플에 대해 ‘자연스러움·이해도’ 예측값을 생성해 의사라벨로 활용한다.
- **Stage 2 – Weakly‑supervised Pretraining**: 의사라벨이 부여된 SAP 샘플과 LibriSpeech를 결합해 라벨 인식 대비학습(label‑aware contrastive learning)을 수행한다. 구체적으로, SimCLR 구조에 두 개의 선형 변환·시간 풀링 레이어를 추가하고, 각 샘플에 두 개의 변형(시간 마스크·주파수 마스크 등)을 만든다.
- **Positive Pair 정의**: 동일 샘플의 두 변형은 기본적인 긍정 쌍이며, 라벨이 동일하거나 라벨 순서가 비슷한(연속적/이산적) 샘플도 추가 긍정 쌍으로 설정한다. 이는 SupCon 아이디어를 확장한 것으로, 라벨이 없는 데이터에서도 라벨 정보를 활용해 태스크‑특화된 표현을 학습한다.
- **Negative Pair**: 나머지 배치 샘플은 모두 부정 쌍으로 처리한다. 온도 파라미터 τ와 라벨 기반 가중치를 조절해 라벨 노이즈에 대한 민감도를 낮춘다.
- **Stage 3 – Fine‑tuning**: 사전학습된 인코더와 두 개의 선형 헤드(대조 헤드와 회귀 헤드)를 SAP 라벨 데이터에 대해 미세조정한다. 회귀 손실(MSE)과 대조 손실을 가중합해 최적화한다.
4. **실험 및 결과**
- **베이스라인**: Whisper‑large 기반 단일 회귀 모델(라벨만 사용) – SAP 테스트 SRCC 0.719, 교차 도메인 평균 SRCC 0.732.
- **제안 프레임워크**: 전체 3단계 적용 후 교차 도메인 평균 SRCC 0.761, SAP 테스트에서도 0.724 수준을 유지. 이는 기존 SOTA인 SpICE(≈0.68)보다 12%p 이상 향상된 수치이다.
- **Ablation**: (1) 약한 지도 사전학습 없이 단순 사전학습(only SimCLR) → SRCC 0.735, (2) LibriSpeech 없이 SAP만 사용 → SRCC 0.743, (3) 라벨 인식 대비학습 없이 순수 SimCLR → SRCC 0.728. 결과는 약한 지도와 정상 음성 데이터가 각각 성능 향상에 크게 기여함을 보여준다.
- **다국어·다병리학 일반화**: 모든 5개 외부 데이터셋에서 평균적으로 0.75 이상의 SRCC를 기록, 특히 언어가 다른 DysArinVox(중국어)와 EW‑ADB(체코·슬로바키아어)에서도 견고한 성능을 보였다.
5. **기술적 의의 및 한계**
- **의의**: 라벨이 부족한 의료 음성 분야에 대규모 비라벨 데이터와 일반 음성 코퍼스를 효과적으로 결합한 첫 사례 중 하나이며, 라벨 인식 대비학습을 통해 라벨 노이즈를 완화하면서도 태스크‑특화된 표현을 학습한다. Whisper‑large를 교사 모델로 활용한 의사라벨 생성은 기존의 단순 클러스터링 기반 라벨 추정보다 정밀도가 높다.
- **한계**: 교사 모델의 편향이 의사라벨에 전이될 위험이 존재한다. 현재는 Whisper‑large를 고정된 인코더로 사용했으며, 전체 파이프라인을 엔드투엔드로 학습하면 추가적인 성능 향상이 기대된다. 또한, 라벨이 연속형이지만 실제 임상에서는 7점 척도 외에 다양한 평가 항목이 존재하므로, 멀티태스크 학습이 필요할 수 있다.
6. **향후 연구 방향**
- 다중 교사 앙상블 및 라벨 불확실성 모델링(예: 베이지안 라벨링)으로 의사라벨 품질을 향상.
- 전체 모델을 엔드투엔드로 학습해 Whisper‑large와 대조 헤드 사이의 공동 최적화.
- 비음성 데이터(영상, 생체신호)와 멀티모달 통합을 통해 임상적 해석력을 강화.
- 라벨이 전혀 없는 새로운 언어·병리학 코퍼스에 대한 제로샷 전이 성능 평가.
**결론**: 라벨이 극히 제한된 발음장애 음성 데이터에서도, 교사 모델 기반 의사라벨링, 라벨 인식 대비학습, 그리고 대규모 정상 음성 데이터의 결합을 통해 강인하고 일반화 가능한 DSQA 모델을 구축할 수 있음을 입증하였다. 이는 향후 임상 현장에서 지속적인 음성 모니터링 및 맞춤형 재활 시스템 구축에 중요한 기반이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기