변형 임베딩을 활용한 트랜스포머 기억 용량 분석
본 논문은 무작위(비직교) 임베딩을 사용한 단층 트랜스포머가 제한된 샘플로 토큰 회수 작업을 학습할 때, 샘플 수 N, 임베딩 차원 d, 시퀀스 길이 L이 곱셈적으로 결합된 저장 용량 한계를 갖는다는 이론적 결과를 제시한다. 초기 몇 단계의 경사 하강법을 분석해 신호‑노이즈 비율을 명시하고, 실험을 통해 제시된 스케일링이 실제 학습에서도 나타남을 확인한다. 또한, 그라디언트 기반 추정기에 대한 하한을 증명해 비직교 임베딩 상황에서 곱셈적 트레이…
저자: Nuri Mert Vural, Alberto Bietti, Mahdi Soltanolkotabi
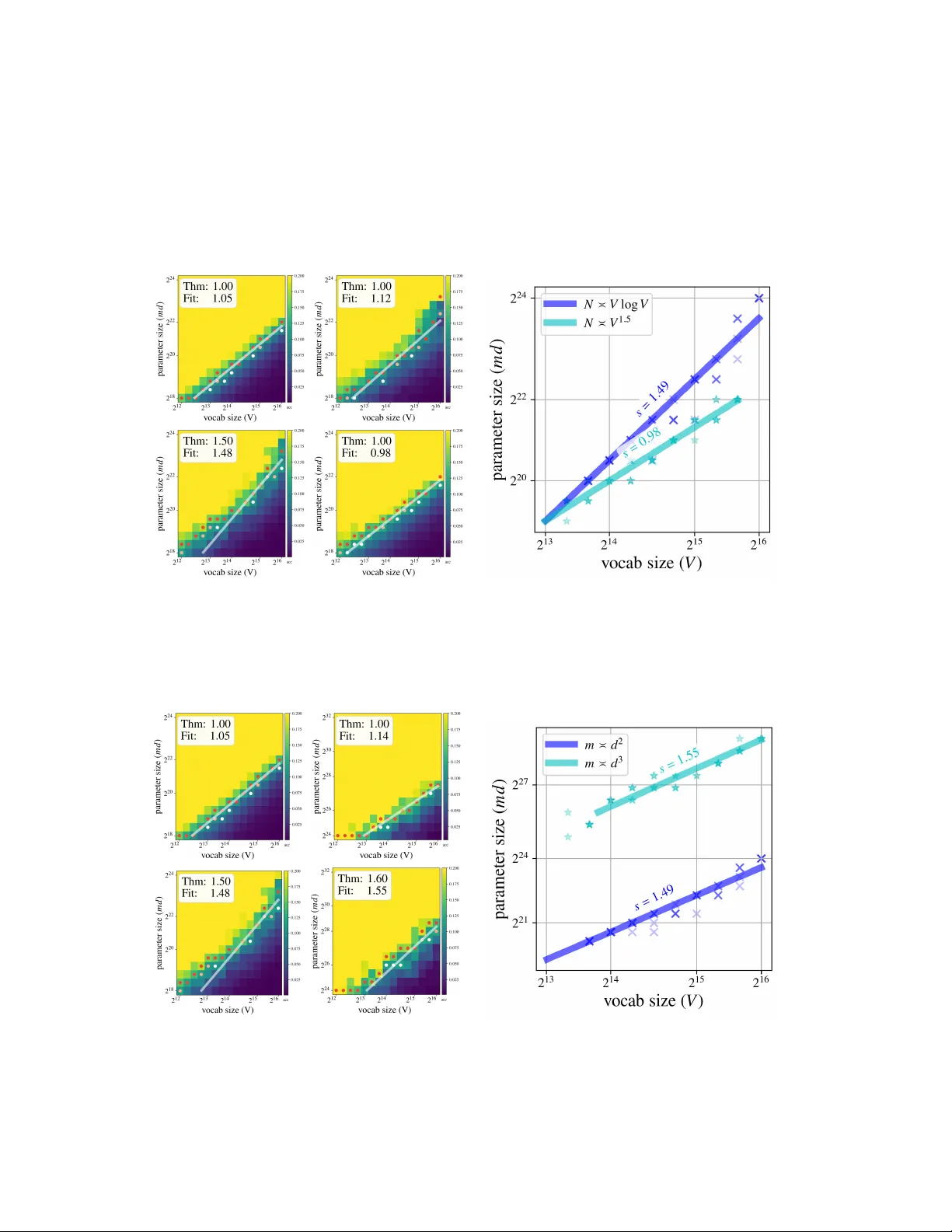
본 논문은 현대 대형 언어 모델(LLM)이 사실 기억과 질문 응답과 같은 작업에서 보여주는 뛰어난 저장·검색 능력을 이론적으로 설명하고자 한다. 기존 연구들은 주로 무한 데이터 가정이나 토큰 임베딩을 정규 직교(또는 원-핫) 벡터로 가정해 분석을 단순화했지만, 실제 모델은 유한 데이터와 무작위(비직교) 임베딩을 사용한다는 점에서 큰 차이가 있다. 저자들은 이러한 현실적 상황을 반영하기 위해, 단층 트랜스포머(어텐션+MLP) 구조에 무작위 가우시안 임베딩을 적용하고, 간단한 토큰 회수(task)에서의 학습 과정을 분석한다.
### 문제 설정
- 어휘 크기 V, 시퀀스 길이 L, 임베딩 차원 d, MLP 폭 m을 파라미터로 둔다.
- 입력 시퀀스 X∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기