정규화된 잠재 동역학 예측으로 행동 기반 모델의 제로샷 강화학습 성능 향상
본 논문은 복잡한 후속 측정( Successor Measure) 학습 대신, 잠재 공간에서 다음 상태를 예측하는 간단한 자기지도 학습 목표에 정규화(직교성) 항을 추가한 **RLDP**(Regularized Latent Dynamics Prediction)를 제안한다. 정규화는 특징 붕괴를 방지해 표현 다양성을 유지하고, 이를 기반으로 학습한 행동 기반 모델(BFM)은 기존 최첨단 방법과 동등하거나 더 높은 제로샷 RL 성능을 보이며, 특히 데…
저자: Pranaya Jajoo, Harshit Sikchi, Siddhant Agarwal
본 논문은 행동 기반 모델(Behavioral Foundation Models, BFMs)이 제로샷 강화학습(zero‑shot RL)에서 다양한 보상 함수에 대해 거의 최적에 가까운 정책을 제공하기 위해서는 **상태 표현 φ**의 품질이 핵심이라는 점을 강조한다. 기존 최첨단 BFMs는 후속 측정(successor measure) 혹은 후속 특징(successor features)을 학습하기 위해 복잡한 자기지도 목표와 Bellman 백업을 결합한다. 이러한 접근법은 (1) 정책‑의존적인 학습 과정, (2) 백업 과정에서 발생하는 편향·분산 및 불안정성, (3) 사전 정의된 정책·보상 집합에 대한 의존성으로 인해 데이터 커버리지가 낮을 때 성능이 급격히 저하되는 한계를 가진다.
이에 저자들은 **잠재 동역학 예측(latent dynamics prediction)** 을 기본 목표로 하는 새로운 방법을 제안한다. 구체적으로, 상태 인코더 ϕ: S→ℝᵈ와 행동‑조건부 전이 모델 g: ℝᵈ×A→ℝᵈ를 정의하고, 시퀀스 τ={s₀,a₀,…,s_H}에 대해 ϕ(s₀)를 초기 잠재 상태 h₀로 두고, h_{t+1}=g(h_t,a_t) 로 전이를 예측한다. 손실은 예측된 잠재 상태와 타깃 인코더 \bar{ϕ}(s_{t+1}) 사이의 L₂ 차이를 평균한 형태(L_d)이며, \bar{ϕ}는 지수 이동 평균을 이용해 천천히 업데이트한다.
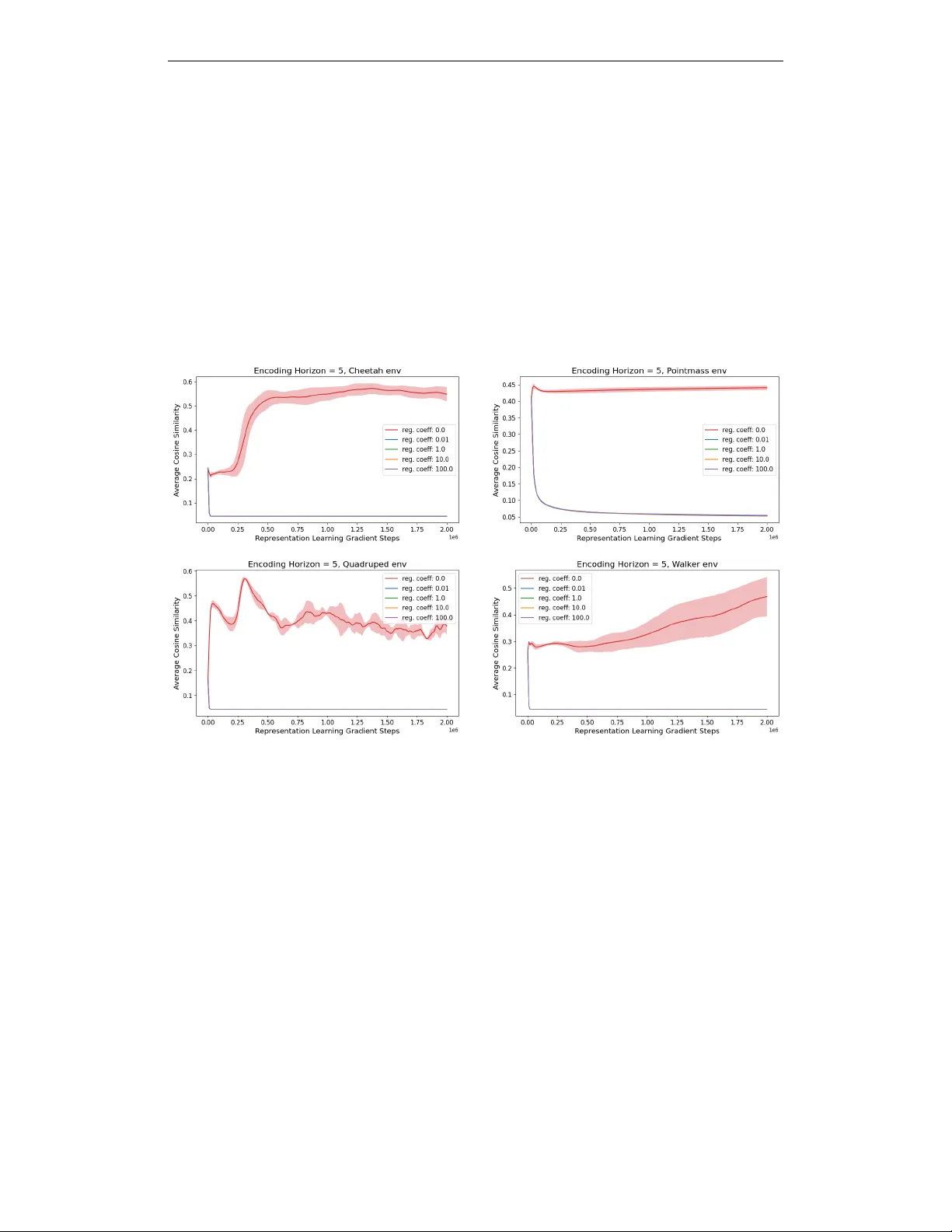
하지만 순수 L_d만 사용하면 **특징 붕괴(feature collapse)** 가 발생한다. 이는 모든 상태가 동일한 잠재 벡터(예: 영벡터)로 수렴해 표현 다양성이 사라지는 현상이다. 논문은 이를 정량적으로 확인하기 위해 훈련 중 무작위 상태 쌍의 평균 코사인 유사도를 측정했으며, 시간이 지날수록 유사도가 급격히 상승함을 보였다.
이를 해결하기 위해 **직교성 정규화(orthogonality regularization)** 를 도입한다. 정규화 항은 서로 다른 상태 임베딩 간의 내적을 최소화하는 형태 L_ortho = Σ_{i≠j} (ϕ(s_i)ᵀϕ(s_j))² 로 정의되며, 전체 손실은 L = L_d + λ·L_ortho 로 구성된다. λ는 하이퍼파라미터이며, 실험에서는 λ=1이 가장 안정적인 결과를 제공한다. 직교성 정규화는 임베딩이 서로 직교하도록 압력을 가해, 표현 스팬을 유지하고 특징 붕괴를 방지한다.
표현 학습이 완료된 뒤, 저자들은 기존 BFMs와 동일한 **후속 특징 ψ** 와 **정책 π_z** 를 학습한다. ψ는 ϕ와 선형 결합된 형태로, ψ(s,a,z)=ψ(s,a)ᵀz 로 표현된다. 정책은 ψ와 보상 임베딩 z의 내적을 최대화하는 argmax 형태로 정의되며, 실제 구현에서는 정책 네트워크 π_z를 사용해 근사한다. 이렇게 하면, 학습된 ϕ가 충분히 풍부하면 ψ 역시 다양한 정책에 대해 정확한 후속 측정을 제공하고, 제로샷 상황에서 r_test(s)≈ϕ(s)ᵀz_test 로 보상 함수를 선형 결합해 새로운 정책을 즉시 추출할 수 있다.
실험은 세 가지 주요 축으로 진행된다. 첫째, **표현 품질**을 평가하기 위해 후속 측정 예측 오차를 측정했으며, RLDP는 기존 후속 측정 기반 방법보다 낮은 오류를 기록했다. 둘째, **제로샷 RL 성능**을 검증하기 위해 DeepMind Control Suite, Meta‑World, 그리고 고차원 Humanoid 환경에서 다양한 보상 함수를 테스트했다. RLDP는 대부분의 환경에서 기존 최첨단 방법과 동등하거나 더 높은 평균 성공률을 보였으며, 특히 복잡한 Humanoid 작업에서 큰 차이를 보였다. 셋째, **데이터 커버리지가 낮은 상황**을 시뮬레이션하기 위해 학습 데이터의 10 %만 사용했을 때, 후속 측정 기반 방법은 급격히 성능이 저하되는 반면, RLDP는 비교적 안정적인 제로샷 정책을 유지했다. 이는 정책‑독립적인 동역학 예측이 데이터 효율성 측면에서 큰 장점을 가짐을 의미한다.
추가 분석에서는 직교성 정규화가 없을 때와 있을 때의 임베딩 코사인 유사도 변화를 시각화했으며, 정규화가 적용된 경우 평균 유사도가 0.2 이하로 유지돼 표현 다양성이 크게 향상됨을 확인했다. 또한, 정규화 비용은 전체 학습 시간에 5 % 미만만 추가되며, 메모리 사용량도 크게 증가하지 않는다.
결론적으로, 논문은 **“복잡한 후속 측정 학습 대신, 간단한 잠재 동역학 예측에 정규화만 추가하면 충분히 강력한 베이스라인이 된다”**는 메시지를 전달한다. RLDP는 구현이 간단하고, 기존 BFMs 파이프라인에 바로 삽입 가능하며, 특히 데이터가 제한된 현실 세계 로봇 응용에서 유용하게 쓰일 수 있다. 향후 연구는 (1) 정규화 형태를 다양화해 더 높은 차원의 표현에서도 안정성을 확보, (2) 멀티모달 센서(이미지, 라이다 등)와 결합해 일반화 범위를 확대, (3) 온라인 데이터 수집과 결합해 지속적인 표현 업데이트를 탐색하는 방향으로 진행될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기