깊이 혼합 주의 메커니즘으로 LLM 성능 향상
초록
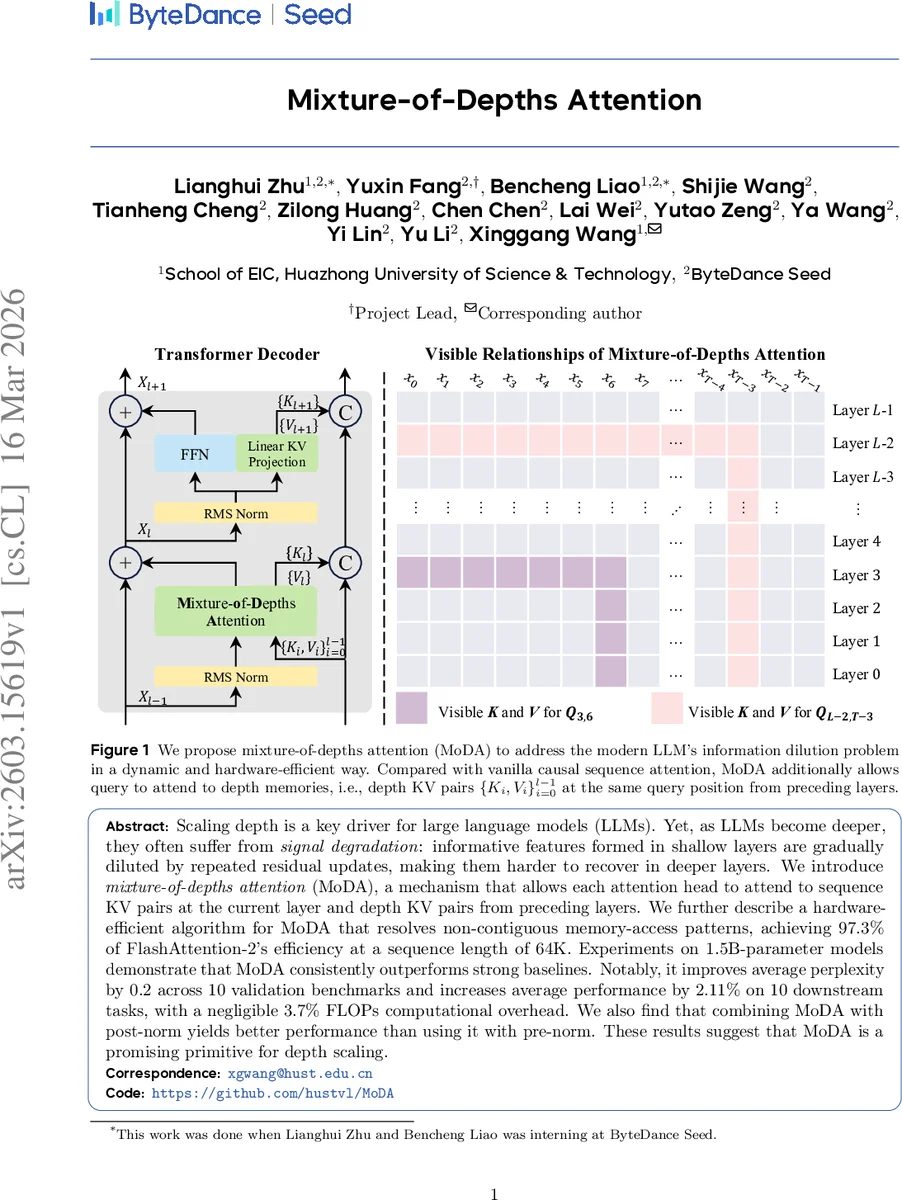
본 논문은 깊이 축적된 정보를 효율적으로 활용하기 위해 각 어텐션 헤드가 현재 레이어의 시퀀스 KV와 이전 레이어들의 깊이 KV를 동시에 참조하도록 설계한 Mixture‑of‑Depths Attention(MoDA)를 제안한다. 하드웨어 친화적인 구현을 통해 64K 토큰 길이에서 FlashAttention‑2 대비 97.3% 효율을 달성했으며, 1.5B 파라미터 모델에서 평균 퍼플렉시티를 0.2, 다운스트림 태스크 평균 성능을 2.11% 향상시켰다.
상세 분석
MoDA는 기존 Transformer의 깊이 축적 방식인 Residual(단순 덧셈)과 Dense(전체 연결) 사이의 절충점으로, “읽기‑연산‑쓰기” 흐름을 명시적으로 모델링한다. 읽기 단계에서 현재 레이어의 은닉 상태와 이전 레이어들의 KV 쌍을 모두 가져오며, 연산 단계에서는 이들을 하나의 소프트맥스에 통합해 시퀀스‑깊이 혼합 어텐션을 수행한다. 이렇게 함으로써 깊이‑별 정보가 고정된 차원으로 압축되는 과정을 최소화하고, 데이터‑의존적인 가중치를 통해 중요한 과거 특징을 선택적으로 재활용한다.
하드웨어 측면에서 MoDA는 비연속 메모리 접근을 완화하기 위해 KV를 “깊이‑블록”과 “그룹‑블록”으로 재배열한다. 알고리즘 1은 HBM→SRAM 전송을 최소화하고, 각 쿼리 블록이 동일한 그룹 크기 G에 맞춰 정렬되도록 설계해 온‑칩 연산에서 공유된 softmax 상태를 재사용한다. 결과적으로 64K 시퀀스 길이에서 FlashAttention‑2 대비 97.3%의 처리량을 유지하면서, FLOPs 증가율은 3.7%에 불과하다.
복잡도 분석(Table 1)에서는 Depth‑Dense가 O(L²D²) 파라미터와 메모리 비용을 요구하는 반면, Depth‑Attention는 O(LD²)로 크게 감소한다. MoDA는 Depth‑Attention와 동일한 O(LD²/G) 파라미터 규모를 유지하면서도, 쿼리 프로젝션을 재사용해 추가 비용을 거의 발생시키지 않는다. 따라서 파라미터 효율성과 연산 효율성 모두에서 최적점을 제공한다.
실험에서는 1.5B 파라미터 모델을 기준으로 OLMo2와 비교했을 때, C4 검증 손실이 평균 0.2 감소하고, HellaSwag, WinoGrande, ARC‑Challenge 등 10개 다운스트림 태스크에서 평균 2.11%의 정확도 향상을 기록했다. 특히 Post‑Norm과 결합했을 때 성능이 더 크게 상승했으며, 이는 깊이‑어텐션이 잔차 흐름을 안정화시키는 효과와 연관된다. 추가적인 스케일링 실험에서는 모델 크기와 레이어 수가 증가할수록 MoDA의 이점이 점진적으로 확대되는 모습을 확인했다.
한계점으로는 현재 구현이 Decoder‑only 구조에 최적화되어 있어 Encoder‑Decoder 혹은 비정형 토큰 처리에 대한 일반화가 미흡하다는 점이다. 또한 깊이‑KV 저장을 위한 메모리 오버헤드가 존재하지만, 실험 결과는 3~4% 수준으로 실용적 범위에 머문다. 향후 연구에서는 KV 압축 기법, 다중 모달 입력에 대한 확장, 그리고 더 큰 모델(수십억 파라미터)에서의 장기 안정성 검증이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기