LLM이 만든 오답 선택지, 학생 오개념을 얼마나 잘 모사할까
본 논문은 대형 언어모델(LLM)이 수학 객관식 문제의 오답 선택지(디스트랙터)를 생성할 때, 학생의 오개념을 어떻게 모델링하는지 분석한다. 저자들은 240개의 LLM 추론 과정을 체계적으로 코딩하고, 학습과학의 권고와 비교해 8가지 전략(문제 해석, 정답 도출, 오류 기술, 오류 시뮬레이션, 결과 구현, 타당성 평가, 최종 선택, 재고)으로 분류한다. 결과는 LLM이 먼저 정답을 구하고, 흔한 오류를 기술·시뮬레이션한 뒤, plausibili…
저자: Yanick Zengaffinen, Andreas Opedal, Donya Rooein
본 논문은 대형 언어 모델(LLM)이 학생의 오개념을 모델링하여 객관식 문제의 오답 선택지(distractor)를 생성하는 과정을 체계적으로 분석한다. 연구 배경으로는 AI 기반 교육에서 학생 모델링이 시험 설계, 오개념 진단, 맞춤형 교육 등 다양한 응용에 핵심적이라는 점을 들며, 특히 ‘잘못됐지만 그럴듯한’ 오답을 만드는 것이 어려운 과제로 제시된다.
먼저 저자들은 기존 학습과학 문헌을 검토해 효과적인 디스트랙터 설계 원칙을 정리한다. 좋은 디스트랙터는 (1) 학생이 흔히 저지르는 구체적 오류와 연결돼야 하고, (2) 정답과 의미·형식적으로 유사하지만 다른 선택지를 제공해야 하며, (3) 낮은 성취도 학생을 더 많이 끌어들이는 ‘음성 차별(negative discrimination)’ 특성을 가져야 한다. 이러한 원칙을 토대로 두 가지 설계 전략을 구분한다. 첫 번째는 정답의 표면적 특성을 변형하는 ‘유사도 기반(similarity‑based)’ 접근이며, 두 번째는 학생이 실제로 범할 수 있는 오류를 정답 과정에 적용해 ‘오개념 기반(misconception‑based)’ 디스트랙터를 만드는 방법이다.
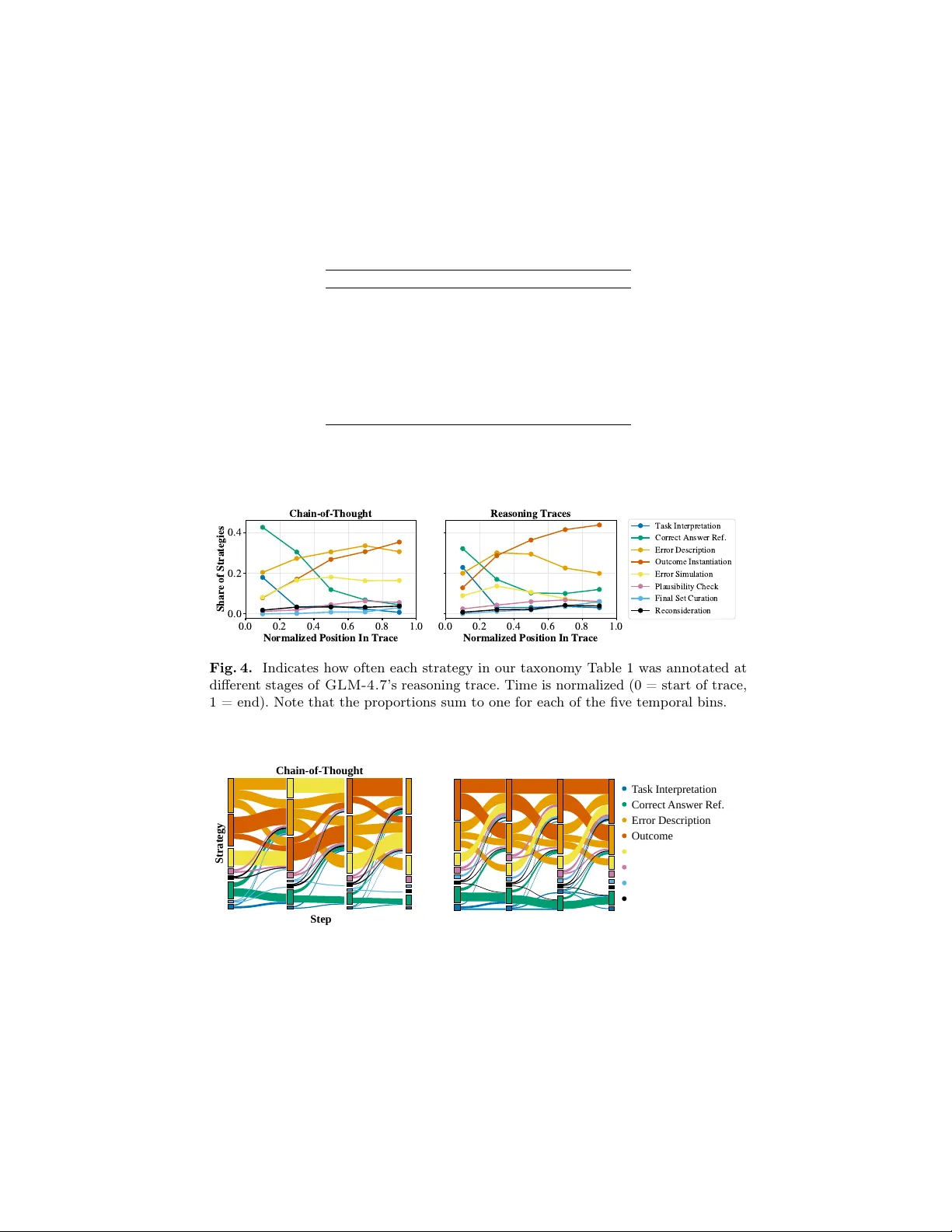
연구의 핵심 기여는 LLM이 디스트랙터를 생성할 때 어떤 사고 흐름을 따르는지를 파악하기 위한 ‘전략 분류 체계’를 제시한 것이다. 저자들은 8가지 전략을 정의했으며, 각각은 학습과학 이론과 LLM 실제 추론 로그를 결합해 도출되었다. 전략은 다음과 같다.
1. INTER(문제 해석) – 문제와 요구사항을 명확히 파악한다.
2. CORR(정답 도출) – 정답을 정확히 계산하거나 참조한다.
3. ERR_DESC(오류 기술) – 흔히 발생하는 학생 오류를 추상적으로 설명한다.
4. ERR_SIM(오류 시뮬레이션) – 오류를 실제 연산 단계에 적용해 본다.
5. INST(오답 구현) – 오류 적용 결과를 구체적인 오답 형태로 만든다.
6. PLAUS(타당성 평가) – 해당 오답이 학생에게 선택될 가능성을 판단한다.
7. CURATE(최종 선택) – 중복 제거·형식 일관성·집합적 품질을 검토해 최종 디스트랙터를 선정한다.
8. RECON(재고) – 필요 시 이전 단계로 돌아가 대안을 탐색한다.
이 체계를 검증하기 위해 저자들은 Eedi Math MCQ 데이터셋(429문제)에서 두 최신 LLM인 DeepSeek‑V3.2와 GLM‑4.7을 사용해 실험을 진행했다. 각 모델에 대해 ‘Chain‑of‑Thought(Cot)’ 프롬프트와 ‘Reasoning’ 프롬프트 두 가지 방식으로 디스트랙터를 생성하도록 했으며, 총 240개의 추론·생성 로그를 확보했다. 로그는 인간 연구자가 ‘오픈 코딩’ 기법으로 의미 단위로 분할하고, 전략 라벨을 부착했으며, 이후 모델‑보조 코딩을 통해 대규모 라벨링을 확장했다.
분석 결과, 대부분의 LLM은 다음과 같은 흐름을 보였다. 먼저 INTER 단계에서 문제를 이해하고, CORR 단계에서 정답을 정확히 도출한다. 그 뒤 ERR_DESC와 ERR_SIM 단계에서 학생이 흔히 저지를 오류를 구체화·시뮬레이션하고, INST 단계에서 오류 적용 결과를 오답으로 만든다. PLAUS 단계에서 자체적으로 “학생이 이 오답을 선택할 확률”을 평가하고, CURATE 단계에서 중복·형식·난이도 등을 고려해 최종 두세 개의 디스트랙터를 선택한다. RECON 단계는 비교적 드물게 나타났으며, 주로 모델이 초기 선택에 확신이 없을 때만 사용되었다.
실패 사례는 주로 CORR 단계에서 정답을 놓치거나, PLAUS·CURATE 단계에서 오답의 타당성을 과소평가할 때 발생했다. 특히 정답을 정확히 파악하지 못하면 이후 오류 시뮬레이션 자체가 의미를 잃어 디스트랙터 품질이 급격히 떨어진다. 반면 ERR_DESC·ERR_SIM 단계는 비교적 일관되게 수행돼, LLM이 학생 오류를 모델링하는 능력은 충분히 확보된 것으로 보인다.
흥미로운 실험적 발견은 ‘정답을 프롬프트에 명시’했을 때 전체 디스트랙터 품질이 평균 8% 향상된다는 점이다. 이는 LLM이 정답을 ‘앵커’로 삼아 오류 시뮬레이션을 진행할 때, 정답이 정확히 제공되면 오류 적용 단계가 보다 정확히 이루어짐을 의미한다. 따라서 교육 현장에서 LLM을 활용한 디스트랙터 자동 생성 시스템을 설계할 때, 정답을 사전에 제공하거나 별도의 정답 검증 모듈을 두는 것이 실용적이다.
결론적으로, LLM은 인간 전문가가 따르는 ‘오개념 기반 디스트랙터 설계’ 절차를 자연스럽게 모방한다는 것이 확인되었다. 특히 오류 기술·시뮬레이션 단계는 교육학적 기대와 일치하며, 이는 LLM이 학생의 잘못된 사고 과정을 충분히 내재하고 있음을 시사한다. 다만 정답 도출과 최종 선택 단계에서의 불안정성을 보완하기 위해, 정답 제공, 다중 모델 앙상블, 외부 타당성 검증 등 보조 메커니즘을 도입하는 것이 향후 연구 과제로 남는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기