뇌 영감을 받은 그래프 다중 에이전트 시스템으로 LLM 추론 강화
본 논문은 글로벌 워크스페이스 이론을 차용해, 문제마다 동적으로 구성되는 그래프 형태의 전문화된 LLM 에이전트들을 중앙 공유 워크스페이스를 통해 협업하게 하는 BIGMAS 프레임워크를 제안한다. GraphDesigner가 문제에 맞는 에이전트 토폴로지를 설계하고, Orchestrator가 전체 워크스페이스 상태를 기반으로 라우팅을 수행한다. Game24, Six Fives, Tower of London 등 세 가지 복합 추론 벤치마크에서 6개…
저자: Guangfu Hao, Yuming Dai, Xianzhe Qin
1. 연구 배경 및 동기
대형 언어 모델(LLM)은 체인‑오브‑생각(Chain‑of‑Thought, CoT)과 자체 반성(self‑reflection) 등을 통해 복합 추론 능력을 크게 향상시켰다. 그러나 최근 연구는 복잡도가 일정 수준을 초과하면 정확도가 급격히 떨어지는 “추론 붕괴(accuracy collapse)” 현상을 보고하고 있다. 이는 모델 규모만으로는 논리적 실행 일관성을 유지하기 어려움을 의미한다. 동시에, 다중 에이전트 프레임워크는 문제를 분할하고 전문화된 역할을 부여함으로써 일부 개선을 보였지만, 대부분 고정된 토폴로지와 부분적인 상태 공유에 머물러 전역적인 협업을 구현하지 못했다.
2. BIGMAS 설계 원칙
뇌의 글로벌 워크스페이스 이론(Global Workspace Theory, GWT)을 차용해 세 가지 원칙을 정의한다. (i) 전문화된 프로세서(에이전트) 역할, (ii) 문제에 따라 동적으로 형성되는 연합(그래프), (iii) 전역 워크스페이스를 통한 모든 에이전트 간의 정보 공유. 이를 구현하기 위해 BIGMAS는 (a) GraphDesigner가 문제별 에이전트 그래프와 워크스페이스 계약을 자동 생성하고, (b) 중앙 공유 워크스페이스 B를 네 파티션(B_ctx, B_work, B_sys, B_ans)으로 구조화하며, (c) 전역 Orchestrator가 전체 워크스페이스 상태를 기반으로 라우팅을 수행한다.
3. 시스템 구성 요소 상세
- **GraphDesigner**: 입력 문제 P=(x, C, y*)를 분석해, 노드 V와 엣지 E, 소스·싱크 노드(v_src, v_snk)를 포함하는 유향 그래프 G와 워크스페이스 계약 κ를 반환한다. 각 노드는 역할 서술자 ρ_i(예: 식 생성기, 검증기, 전략 업데이트기)를 갖고, 계약에 따라 읽·쓰기 권한을 부여받는다.
- **공유 워크스페이스 B**: B_ctx는 읽기 전용 문제 설명과 제약을 보관, B_work은 중간 결과를 저장하는 가변 영역, B_sys은 실행 단계·히스토리·라우팅 메타데이터, B_ans은 최종 답안을 기록한다. 모든 에이전트는 B에만 접근하며, 직접적인 노드 간 메시지는 금지된다.
- **노드 실행 프로토콜**: 활성 노드 v_t는 현재 B(t), 역할 ρ_t, 계약 κ를 입력받아 구조화된 쓰기 명령 ω_t=(π_t, α_t, δ_t)를 생성한다. π_t는 B_work 내 경로, α_t는 append·update·replace 중 하나, δ_t는 출력 데이터이다. 출력은 자연어 형식으로 명시되며, 다중 파싱 전략이 이를 정확히 추출한다.
- **쓰기 검증 및 Self‑Correction Loop**: 워크스페이스 검증기가 ω_t를 스키마·타입·권한 관점에서 검사하고, 오류 시 LLM 호출을 재시도하거나 대체 전략을 적용한다. 이를 통해 일시적인 포맷 오류나 논리적 부정합을 자동 복구한다.
- **전역 Orchestrator**: B_sys에 기록된 히스토리와 현재 B_work 상태를 종합해 다음에 활성화할 노드를 선택한다. 라우팅 정책은 (1) 목표 노드가 아직 수행되지 않았는가, (2) 현재 워크스페이스에 충분한 입력이 존재하는가, (3) 이전 실행 결과와의 의존 관계를 고려한다. 라우팅은 전역 정보를 활용하므로, 로컬 컨텍스트에만 의존하는 기존 ReAct·Tree of Thoughts와 달리 최적의 흐름을 도출한다.
4. 실험 설정
- **벤치마크**: Game24(네 숫자를 이용해 24 만들기), Six Fives(여섯 개의 5를 이용해 목표값 만들기), Tower of London(세 개의 peg를 이용한 최소 이동 계획) 세 가지 과제. 각 과제는 문제 복잡도 조절이 가능하고, 중간 단계 검증이 가능하도록 설계돼 모델 수준의 CoT가 한계에 도달하기 쉬운 환경을 제공한다.
- **모델**: DeepSeek, Claude, GPT‑4, Gemini 등 6개의 최신 LLM과 이들의 LRM 변형(o1, o3 등)을 사용했다.
- **비교 대상**: ReAct, Tree of Thoughts, Graph of Thoughts, DyLAN, GPTSwarm 등 기존 다중 에이전트·그래프 기반 프레임워크와, 단일 모델 CoT 및 self‑consistency을 적용한 베이스라인을 포함했다.
- **평가 지표**: 최종 정답 정확도, 단계당 성공률, 평균 실행 단계 수, 그리고 복잡도 구간별 성능 변화를 측정했다.
5. 주요 결과
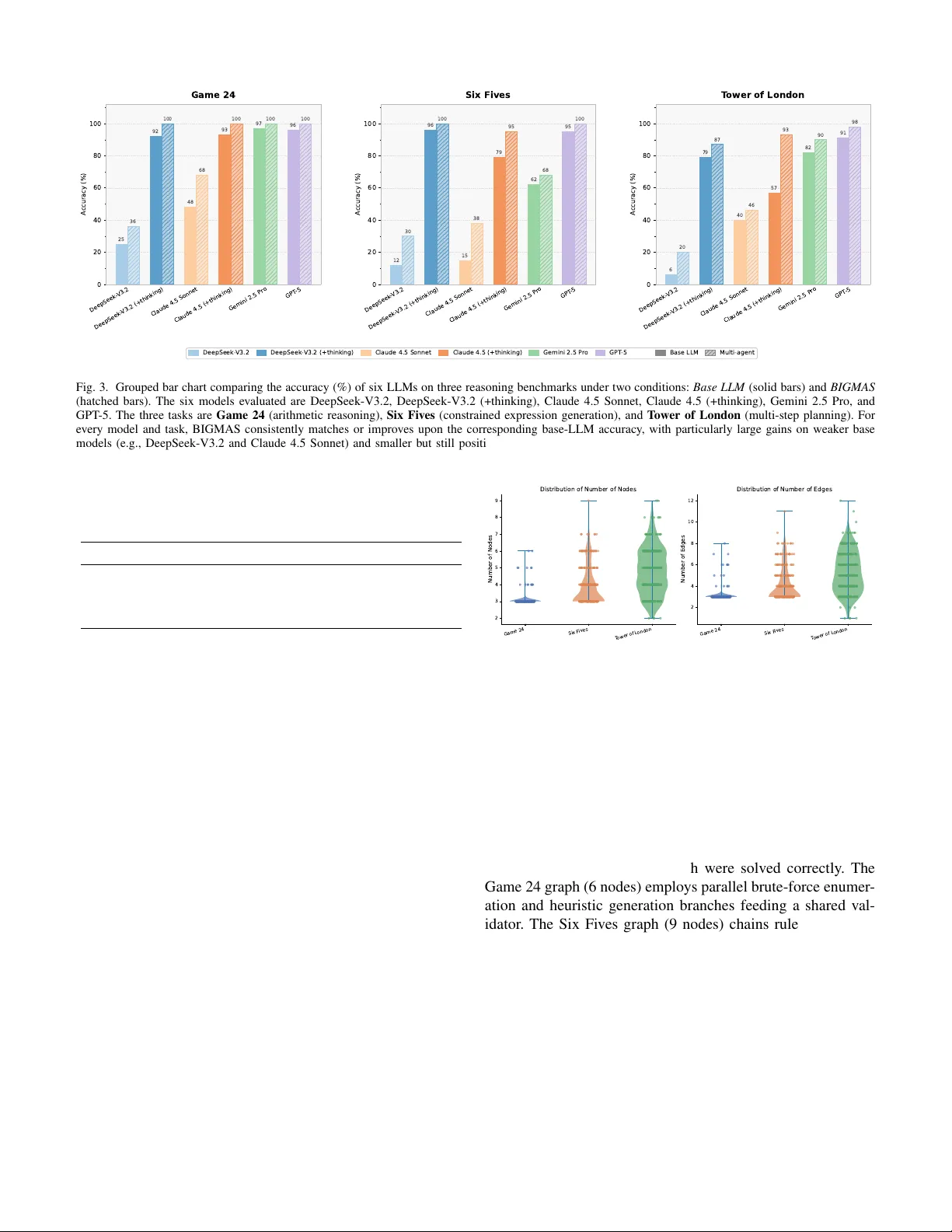
- **전반적 성능 향상**: BIGMAS는 모든 모델·과제 조합에서 평균 4~12%p 이상의 정확도 상승을 기록했다. 특히 복잡도 상한을 초과하는 문제(예: 24점에 근접한 식 찾기)에서는 15%p 이상 차이가 나타났다.
- **추론 붕괴 완화**: 기존 LLM·LRM이 정확도가 급락하던 구간에서 BIGMAS는 상대적으로 완만한 감소 곡선을 보이며, 전역 워크스페이스와 동적 그래프가 논리적 일관성을 유지하는 데 기여함을 확인했다.
- **시너지 효과**: CoT 프롬프트와 BIGMAS를 병행했을 때, 단순 CoT 대비 추가 6%p 이상의 향상이 관찰돼 두 접근법이 서로 보완적임을 입증했다.
- **비용·효율성**: 그래프 설계와 검증 단계에서 약간의 연산 오버헤드가 발생했지만, 전체 실행 단계 수는 오히려 감소하는 경향을 보여, 효율성 측면에서도 경쟁력을 유지했다.
6. 논의 및 한계
- **계약 κ의 품질 의존성**: GraphDesigner가 생성하는 계약이 부정확하면 검증 단계에서 반복 재시도가 발생해 비용이 증가한다. 향후 형식화된 DSL이나 자동 검증 메커니즘이 필요하다.
- **스케일링**: 현재 실험은 상대적으로 작은 문제(수십 단계)에서 수행했으며, 대규모 계획(수백 단계)에서는 라우팅 정책과 메모리 관리가 추가 연구 대상이다.
- **다양한 도메인 적용**: 현재는 수학·퍼즐·계획에 초점을 맞췄지만, 코드 생성, 자연어 요약 등 다른 도메인에 적용하려면 워크스페이스 스키마와 역할 정의를 재설계해야 한다.
7. 결론
BIGMAS는 인간 뇌의 글로벌 워크스페이스 이론을 인공 지능에 성공적으로 이식한 최초의 프레임워크로, 문제별 동적 그래프와 전역 공유 워크스페이스를 통해 LLM의 추론 붕괴를 구조적으로 완화한다. 실험 결과는 모델‑레벨 체인‑오브‑생각 기법과 독립적인 보완 효과를 보여, 향후 멀티‑에이전트·멀티‑모달 협업 시스템 설계에 중요한 방향성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기