프로세스 마이닝을 위한 프라이버시 보호형 에이전트 프레임워크 PMAx
PMAx는 엔지니어와 애널리스트 두 에이전트가 협업하는 다중‑에이전트 구조를 통해 로컬에서 정확한 프로세스 마이닝을 수행한다. 메타데이터만 외부 LLM에 전달하고, 엔지니어 에이전트가 파이썬 스크립트를 자동 생성·검증·실행하며, 애널리스트 에이전트가 결과를 해석해 비전문가에게 자연어 보고서를 제공한다. 데이터는 로컬에 머무르며 정적 검증과 자체 교정 루프를 통해 보안·정확성을 보장한다.
저자: Anton Antonov, Humam Kourani, Aless
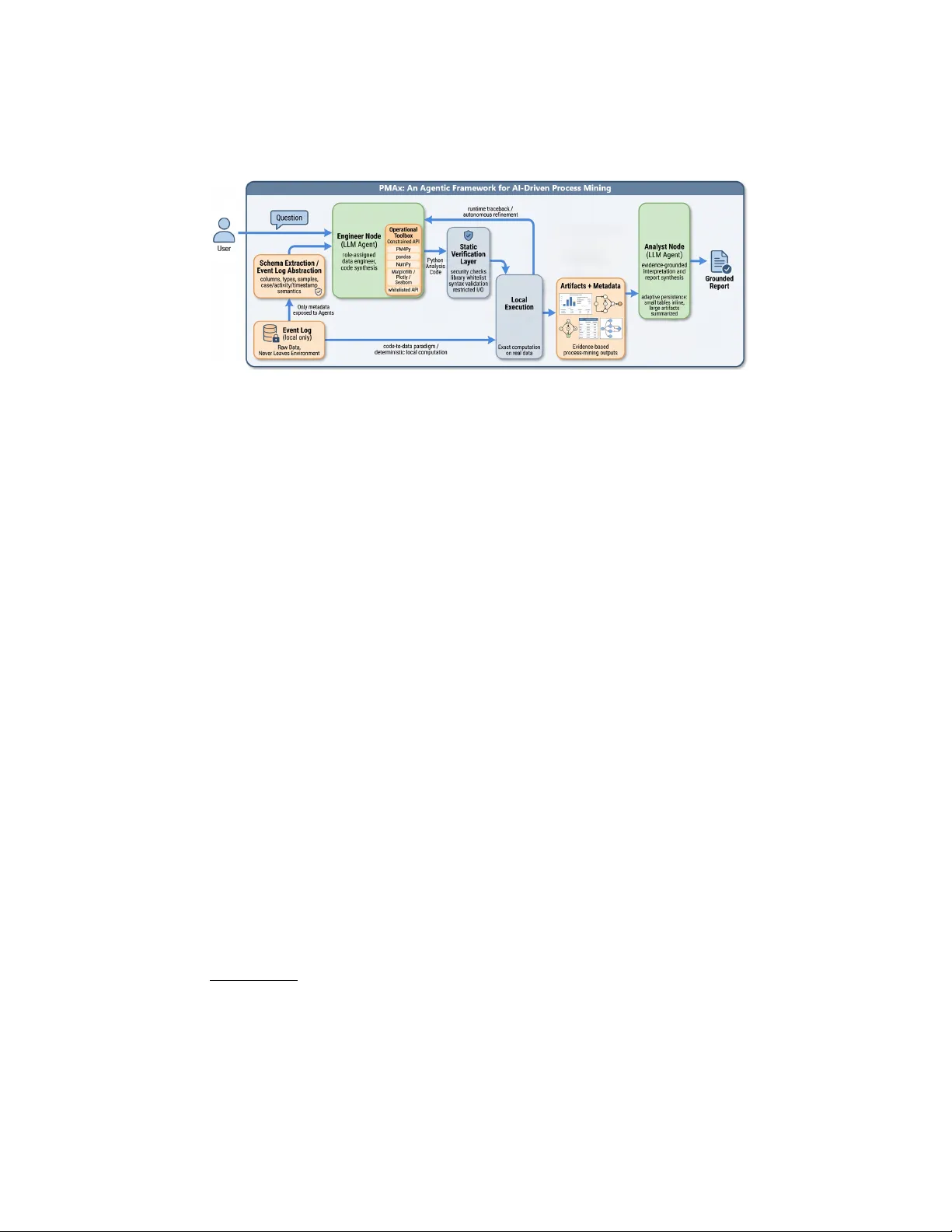
본 논문은 프로세스 마이닝 분야에서 대규모 언어 모델(LLM)의 활용이 가져올 수 있는 장점과 위험을 동시에 조명하고, 이를 보완하기 위한 새로운 시스템 아키텍처인 PMAx를 제안한다. 전통적인 프로세스 마이닝은 이벤트 로그에서 프로세스 모델을 추출하고, 통계·컨포먼스 지표를 계산하는 일련의 알고리즘을 필요로 한다. 이러한 작업은 PM4Py, PQL 등 전문 라이브러리를 통해 수행되지만, 비전문가가 직접 코드를 작성하거나 복잡한 쿼리를 구성하기는 어렵다. 최근 상용 솔루션(Celonis, SAP Signavio, Apromore 등)은 LLM 기반 코파일럿을 도입해 자연어 질의를 지원하지만, (1) LLM이 직접 계산을 수행할 경우 결과가 환각될 위험, (2) 민감한 로그 데이터를 외부 API에 전송해야 하는 프라이버시 문제, (3) 컨텍스트 윈도우 제한으로 대규모 로그를 다루기 어려운 점이 남아 있다.
PMAx는 이러한 문제를 해결하기 위해 ‘엔지니어(Engineer) 에이전트’와 ‘애널리스트(Analyst) 에이전트’라는 두 개의 전문화된 LLM 에이전트를 도입한다. 시스템 흐름은 다음과 같다. 사용자는 로컬에 이벤트 로그 파일을 업로드하고, 자연어 형태의 분석 질문을 입력한다. 시스템은 먼저 스키마 추출 모듈을 통해 로그의 컬럼명, 데이터 타입, 샘플 값을 메타데이터 형태로 요약한다. 이 메타데이터는 LLM에게 전달되는 유일한 데이터이며, 원시 로그는 절대로 외부에 노출되지 않는다.
엔지니어 에이전트는 ‘데이터 엔지니어’ 역할을 수행하도록 프롬프트에 명시되고, 사전 정의된 운영 규칙과 API 화이트리스트를 기반으로 파이썬 스크립트를 자동 생성한다. 주요 규칙은 (1) 허용된 라이브러리(pm4py, pandas, numpy, plotly 등)만 사용, (2) 파일 입출력은 금지되고 모든 결과는 API를 통해 저장, (3) 코드에는 반드시 필요한 import 문을 포함, (4) 시각화는 최소화하여 연산 비용 절감 등이다. 생성된 코드는 정적 분석 단계에서 구문 오류, 보안 위반, 라이브러리 사용 규칙 위반 여부를 검사한다. 검증을 통과하면 로컬 파이썬 인터프리터에서 실행되며, 실행 중 발생하는 예외는 트레이스백 형태로 엔지니어 에이전트에게 반환된다. 엔지니어는 이 피드백을 활용해 코드를 자동 교정하고, 재시도한다. 이 자체 교정 루프는 인간 개입 없이도 코드의 정확성을 보장한다.
실행 결과(프로세스 모델, DFG, 통계 테이블, 시각화 파일 등)는 API를 통해 공유 메모리(state)에 저장된다. 애널리스트 에이전트는 이 메타 정보를 받아, 사전 정의된 출력 스키마(텍스트와 아티팩트 딕셔너리 리스트)를 사용해 자연어 보고서를 작성한다. 보고서 작성 시, 대용량 데이터프레임은 요약 통계만 포함하고, 시각화는 이미지 대신 메타데이터(예: 차트 유형, 축 레이블) 형태로 전달해 토큰 사용량을 최적화한다. 또한, 보고서에 포함된 아티팩트 참조가 실제 결과와 불일치하면 자동 오류 처리 루프가 작동해 애널리스트 에이전트가 보고서를 재작성하도록 한다.
PMAx는 완전 오픈소스 설계이며, ProMoAI 툴킷에 플러그인 형태로 구현돼 Python 환경에서 손쉽게 설치·실행할 수 있다. 시스템은 확장성을 고려해 API 레이어에 새로운 마이닝 알고리즘이나 커스텀 전처리 함수를 추가하면 에이전트가 자동 활용하도록 설계되었다.
논문에서는 BPI Challenge 2017 대출 신청 로그를 대상으로 실증 실험을 수행했다. 다섯 개의 비즈니스 질문(Q1~Q5)을 제시했으며, 각각에 대해 엔지니어 에이전트는 (i) 프로세스 모델 자동 발견, (ii) 처리 시간 분포 계산, (iii) 대기 시간·병목 식별, (iv) 정보 요청이 오퍼 수락에 미치는 영향 분석, (v) 단일·다중 오퍼 성공률 비교 등 필요한 코드를 정확히 생성했다. 연구진이 수동으로 검증한 결과, 모든 코드가 정상 실행되었고, 애널리스트 에이전트가 제공한 보고서는 질문에 대한 데이터 기반 통찰을 충분히 전달했다. 특히 Q5와 같은 복합 비교 분석도 자동으로 수행돼, 고수준 비즈니스 요구를 저수준 데이터 과학 작업으로 매핑하는 전체 파이프라인이 검증되었다.
결론적으로, PMAx는 LLM의 자연어 이해와 전통적인 프로세스 마이닝 알고리즘의 정확성을 결합한 프라이버시 보호형, 자동화된 분석 프레임워크를 제공한다. 데이터는 로컬에 머무르며, 정적 검증·자체 교정 메커니즘을 통해 코드와 결과의 신뢰성을 확보한다. 향후 연구에서는 에이전트 간 협업 전략 고도화, 더 복잡한 멀티‑모달 로그 지원, 그리고 기업 환경에서의 배포 및 운영 관리 방안을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기