연속학습을 위한 동적 임계값 스파이킹 트랜스포머 CATFormer
** CATFormer는 스파이킹 비전 트랜스포머에 동적 임계값을 적용한 DTLIF 뉴런과 G‑DHS 헤드 선택 메커니즘을 도입해, 가중치를 고정한 채 작업별 임계값만 학습함으로써 데이터 재현 없이도 100개 이상의 클래스 증가 작업에서 기억 상실을 방지하고, 정적·신경형 데이터셋 모두에서 기존 방법들을 크게 앞선 성능을 달성한다. **
저자: Vaishnavi Nagabhushana, Kartikay Agrawal, Ayon Borthakur
**
본 논문은 연속학습(Continual Learning, CL) 환경에서 데이터 재현(rehearsal) 없이도 스파이킹 비전 트랜스포머(Spiking Vision Transformer)를 효과적으로 학습할 수 있는 새로운 프레임워크 **CATFormer**(Context Adaptive Threshold Transformer)를 제안한다. 기존 딥러닝 모델은 한 번에 모든 데이터를 학습하도록 설계돼 실시간 데이터 흐름이나 분포 변화가 있는 실제 로봇·엣지 디바이스에 적용하기 어렵다. 특히, 새로운 작업이 추가될 때 이전 작업에서 학습한 지식이 소멸되는 **catastrophic forgetting** 문제가 심각하다. 뇌는 신경 가소성(plasticity)과 흥분성(excitability) 조절을 통해 이러한 현상을 방지한다는 사실에 착안해, 저자는 두 가지 생물학적 영감을 받은 메커니즘을 스파이킹 트랜스포머에 도입한다.
첫 번째 메커니즘은 **Dynamic Threshold Leaky Integrate‑and‑Fire(DTLIF)** 뉴런이다. 기존 LIF 뉴런은 고정된 발화 임계값을 사용하지만, DTLIF는 작업(task)마다 학습 가능한 임계값 ϕ(k)를 갖는다. 임계값은 역전파를 통해 손실 함수에 대한 기울기로 직접 업데이트되며, 뉴런의 전압 V(t)와 입력 전류 I(t)를 이용한 표준 LIF 동역학에 소프트 리셋을 적용한다. 이렇게 하면 시냅스 가중치 θ는 최초 작업 이후 고정하고, 새로운 작업이 들어올 때마다 해당 작업 전용 임계값만 조정함으로써 **신경 흥분성**을 동적으로 변화시킨다. 결과적으로 동일한 가중치를 공유하면서도 작업별 특성을 반영한 스파스 발화 패턴을 만들 수 있다.
두 번째 메커니즘은 **Gated Dynamic Head Selection(G‑DHS)**이다. 각 작업마다 별도의 출력 헤드 W_k를 두고, 입력 특징 f(x)를 추출한 뒤 두‑계층 MLP(Linear‑ReLU‑Linear)로 구성된 게이팅 네트워크 G가 현재 입력이 어느 작업에 속하는지를 예측한다. 테스트 단계에서는 먼저 기본 임계값(ϕ_init)으로 전체 특징을 추출하고, G가 예측한 작업 ID k*에 해당하는 임계값 ϕ(k*)와 헤드 W_k*를 활성화한다. 이 과정은 **task‑agnostic inference**를 가능하게 하며, 별도의 작업 식별자 없이도 정확한 클래스 예측을 수행한다.
학습 절차는 **두 단계 프로토콜**로 설계된다. ① 첫 번째 작업에서는 백본 θ와 초기 임계값 ϕ(0), 그리고 헤드 W_0를 공동 최적화한다. ② 이후 작업에서는 기존 파라미터를 모두 고정하고, 새로운 헤드 W_k와 해당 작업 전용 임계값 ϕ(k)만을 학습한다. 이때 손실은 교차 엔트로피(CE)이며, 임계값은 경사 하강법으로 업데이트된다. 또한, 각 작업이 끝난 뒤에는 현재 작업의 특징을 로컬 버퍼에 저장하고, 이를 이용해 게이팅 MLP G를 추가 학습한다. 이렇게 하면 메모리 사용량이 작업 수에 비례하지 않으며, 재현 없이도 각 작업의 특징을 효과적으로 기억한다.
**실험**에서는 정적 이미지 데이터셋(CIFAR‑10, CIFAR‑100, Tiny‑ImageNet)과 신경형 데이터셋(CIFAR10‑DVS, SHD)을 사용해 10~100개의 작업 시퀀스를 구성하였다. 모든 비교 모델(EWC, SI, MAS, iCaRL, DER++, RDER 등)은 동일한 SpikFormer 백본 위에서 구현되었으며, 동일한 하이퍼파라미터와 평가 프로토콜을 적용했다. 결과는 다음과 같다.
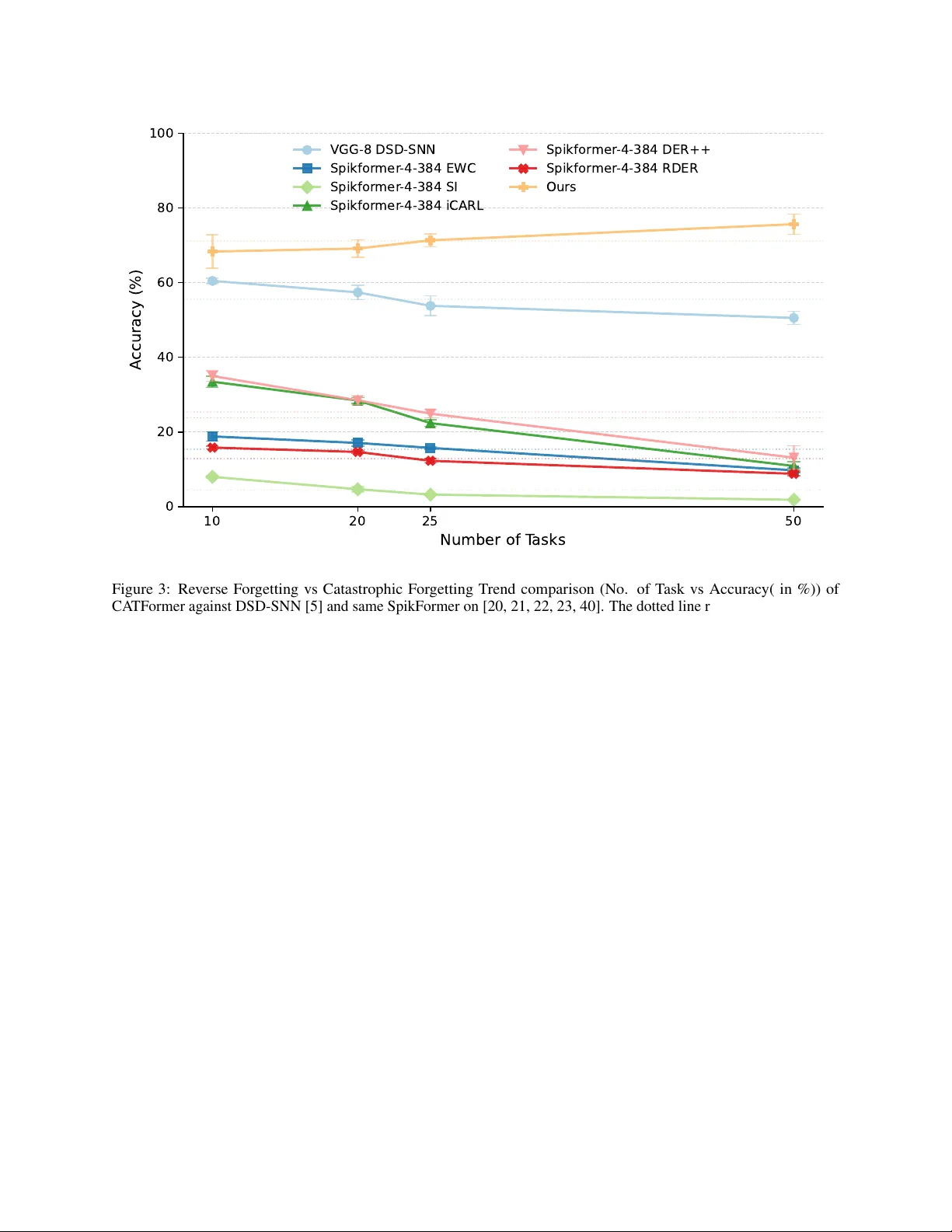
- **정확도**: CATFormer는 CIFAR‑100 50‑task 시나리오에서 평균 정확도가 68%에 달했으며, 이는 기존 최첨단 방법보다 7~12%p 상승한 수치이다. Tiny‑ImageNet 100‑task에서도 평균 정확도가 55%를 유지, 다른 방법은 30% 이하로 급격히 하락했다.
- **역전망(reverse forgetting)**: 작업 수가 증가할수록 평균 정확도가 오히려 상승하는 현상이 관찰되었다. 이는 새로운 작업이 임계값을 재조정하면서 전체 네트워크의 스파스성을 유지하고, 이전 작업의 특징이 손실되지 않기 때문이다.
- **에너지 효율**: 스파이킹 연산 특성상 전통적인 CNN 기반 CL보다 3.3배 적은 연산량을 기록했으며, 메모리 사용량도 작업당 헤드와 임계값만 저장해 선형 증가 수준에 머물렀다.
- **재현 불필요**: 모든 실험은 데이터 재현 없이 진행되었으며, 이는 프라이버시·저전력 엣지 디바이스에 매우 중요한 특성이다.
**한계 및 향후 연구**로는 (1) 작업별 임계값을 저장해야 하는 메모리 오버헤드, (2) 게이팅 네트워크의 초기 오분류가 전체 성능에 미치는 영향, (3) 임계값 학습이 과도해질 경우 뉴런 발화가 지나치게 억제되는 위험을 들었다. 저자는 임계값 압축, 메타‑학습 기반 초기화, 다중 작업 간 임계값 공유 메커니즘 등을 통해 이러한 문제를 해결하고, 멀티‑태스크 동시 학습 및 비동기식 데이터 스트림에 대한 확장성을 탐구할 계획이다.
결론적으로, CATFormer는 **동적 임계값 기반 신경 흥분성 조절**과 **가벼운 헤드 라우팅**을 결합해, 스파이킹 트랜스포머를 장기 연속학습에 적용할 수 있는 실용적인 솔루션을 제공한다. 이는 물리적 AI, 로보틱스, 저전력 엣지 컴퓨팅 분야에서 데이터 재현이 불가능하거나 비용이 높은 상황에서도 지속적인 학습과 높은 정확도를 동시에 달성할 수 있음을 입증한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기