다중소스 CT 이미지 분류를 위한 비전 언어 모델 기반 다전문가 융합
본 논문은 COVID‑19 진단을 위한 흉부 CT 영상을 네 개의 서로 다른 기관에서 수집한 데이터셋에 적용하는 3단계 소스 인식 멀티‑전문가 프레임워크를 제안한다. 3D 폐‑인식 전문가, 2D MedSigLIP 기반 슬라이스‑별 및 슬라이스 간 컨텍스트 모델링 전문가, 그리고 소스 분류기를 결합해 소스별 최적 전문가를 선택하고 투표·융합함으로써 전체 검증에서 macro‑F1 0.97, ACC 0.97, AUC 0.98을 달성하였다.
저자: Jianfa Bai, Kejin Lu, Runtian Yuan
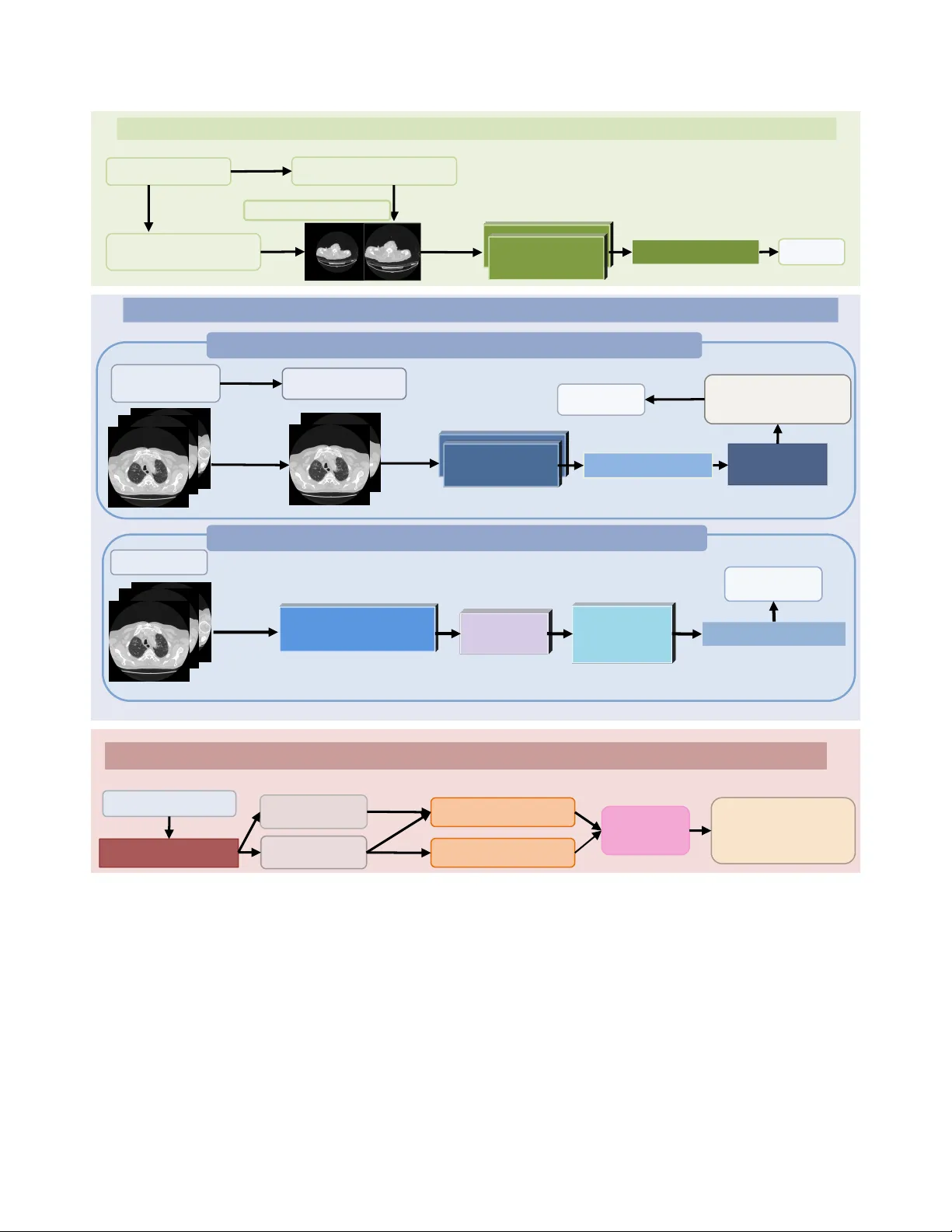
본 논문은 COVID‑19 감염 여부를 판별하기 위한 흉부 CT 이미지 분류 문제를 다중 기관에서 수집된 데이터의 도메인 편차와 클래스 불균형, 그리고 테스트 단계에서 소스 라벨이 숨겨진 상황이라는 세 가지 핵심 난점에 초점을 맞추어 해결하고자 한다. 이를 위해 저자들은 ‘소스‑인식 멀티‑전문가 프레임워크’를 3단계로 설계하였다.
첫 번째 단계(Stage 1)에서는 3D 볼륨 기반 분류기를 구축한다. 원본 CT와 폐 영역만을 추출한 CT 두 종류의 볼륨을 동일한 3D ResNet‑style 백본에 입력하고, 이들을 혼합 학습함으로써 배경 잡음과 기관별 스캔 차이를 최소화한다. 데이터 전처리 단계에서 폐 영역을 자동 추출하고, 슬라이스 수가 150을 초과할 경우 앞뒤 15%를 제거해 불필요한 주변 정보를 배제한다. 3D 모델은 표준 교차 엔트로피 손실을 사용해 이진 분류를 학습하며, 학습 시에는 전체 슬라이스에 동일한 랜덤 회전·크롭·리사이징을 적용해 일관된 변형을 제공한다. 검증 결과, 원본과 폐‑추출 영상을 결합한 입력이 가장 높은 ACC 0.9712와 macro‑F1 0.9711을 기록했으며, 특히 소스0에 대해서는 100% 정확도를 달성해 이후 단계에서 소스‑특화 라우팅의 근거가 된다.
두 번째 단계는 2D 기반의 두 개의 보조 전문가를 도입한다. 먼저 MedSigLIP이라는 대규모 비전‑언어 사전학습 모델을 기반으로 슬라이스‑별 확률 학습을 수행한다(Stage 2a). 각 CT 스캔을 24개의 슬라이스(448 × 448)로 정규화하고, 학습 시에는 연속된 12개의 슬라이스를 무작위로 추출해 각각 MedSigLIP 이미지 인코더에 통과시킨 뒤, 슬라이스별 확률을 평균해 스캔‑레벨 예측을 만든다. 이 방식은 메모리 사용량을 크게 줄이면서도 스캔‑레벨 라벨을 효과적으로 전파한다.
Stage 2b에서는 2a에서 얻은 슬라이스 임베딩을 활용해 슬라이스 간 연속성을 모델링한다. 기존 MedSigLIP 인코더의 마지막 두 레이어와 새롭게 추가된 두 개의 Transformer 인코더 블록만을 미세조정하고, 나머지 레이어는 고정한다. 이렇게 얻어진 컨텍스트화된 슬라이스 특징을 다시 평균해 최종 스캔‑레벨 표현을 만든 뒤, 새로운 이진 분류 헤드를 통해 예측한다. 2b는 2a에 비해 슬라이스 간 상호작용을 명시적으로 학습함으로써 macro‑F1 0.9582와 AUC 0.9854라는 향상된 성능을 보였다.
세 번째 단계(Stage 3)는 소스 분류기이다. 1단계에서 학습된 3D 백본을 그대로 사용하고, 이진 분류 헤드를 4‑클래스(소스0~3) 소스 분류 헤드로 교체한다. 백본은 고정하고 헤드만 학습함으로써 소스 식별에 필요한 특징을 효율적으로 추출한다. 검증에서 소스 분류기의 정확도는 0.9107, F1은 0.9114로 충분히 높은 수준을 보였으며, 이를 기반으로 테스트 시 각 스캔의 소스를 예측한다. 예측된 소스가 0이면 Stage 1 3D 전문가만 사용하고, 1·2·3이면 Stage 1, 2a, 2b 세 전문가의 예측을 투표·가중 평균해 최종 라벨을 결정한다. 각 단계마다 여러 모델 변형을 학습하고, 동일 단계 내에서는 앙상블 투표를 적용해 안정성을 높였다.
데이터셋은 ‘Multi‑Source COVID‑19 Detection Challenge’에서 제공한 네 개의 기관별 CT 스캔을 사용했으며, 공식 검증 셋에 소스2의 양성 케이스가 없다는 문제를 해결하기 위해 해당 소스의 39개 양성 샘플을 검증에 포함시켰다. 또한, 소스0의 비정상적인 폴더 구조를 교정하고, 테스트 셋의 소스 라벨이 없으므로 Stage 3 소스 분류기로 추정한 후 라우팅에 활용하였다.
전체 실험 결과는 다음과 같다. Stage 1은 macro‑F1 0.9711, ACC 0.9712, AUC 0.9791을 기록했고, Stage 2a는 macro‑F1 0.9450, AUC 0.9864, ACC 0.9481을, Stage 2b는 macro‑F1 0.9582, AUC 0.9854, ACC 0.9597을 달성했다. 최종 소스‑인식 융합 모델은 모든 소스에 걸쳐 높은 일관성을 보이며, 특히 소스0에 대해 완벽한 정확도를 유지함으로써 실제 임상 현장에서 기관별 맞춤형 진단 시스템으로 활용 가능성을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기