신호 예측 확산 모델을 이용한 실시간 초기 반사 기반 실내 음향 응답 완성
본 논문은 이미지 소스 방법으로 얻은 직접 경로와 초기 반사를 조건으로 사용해, x‑prediction 기반 확산 모델로 전체 실내 음향 응답(RIR)을 완성한다. 고정된 입력 길이 제한이 없으며, 클래스프리 가이던스를 통해 물리적으로 현실적인 파동 효과를 학습한다. 실험 결과는 기존 Echo2Reverb 대비 초기 구간 에너지 비율, 전체 RMSE, 에너지 감소 곡선(EDC) 재현에서 우수함을 보여준다.
저자: Zeyu Xu, Andreas Brendel, Albert G. Prinn
본 논문은 실내 음향 응답(RIR) 생성·보완 분야에서 기존의 한계를 극복하기 위해 새로운 확산 모델 프레임워크를 제안한다. 전통적인 물리 기반 시뮬레이션은 기하학적 방법(이미지 소스 방법, 레이 트레이싱 등)과 수치 파동 방법(유한 차분·요소·경계·볼륨 등)으로 나뉘며, 전자는 초기 반사까지는 빠르게 계산되지만 파동 간섭·회절 효과가 부족하고, 후자는 정확하지만 계산 비용이 크다. 최근 딥러닝 기반 RIR 생성 연구가 진행되고 있으나, 초기 반사만을 입력으로 레이트 리버버레이션을 완성하는 ‘RIR completion’ 작업은 아직 제한적이다. 특히 기존 방법은 완전한 초기 반사(예: 50 ms~80 ms 구간)를 전제로 하며, 입력 길이가 고정돼야 한다는 제약이 있다.
이에 저자들은 (1) x‑prediction 기반 확산 모델, (2) 이미지 소스 방법(ISM)으로 얻은 직접 경로와 초기 반사(조건자 c)를 활용한 조건부 학습, (3) 클래스프리 가이던스(CFG)를 통한 물리적 현실감 강화라는 세 축을 결합한다. 확산 과정은 코사인 스케줄에 따라 노이즈를 단계적으로 추가하고, 역전파 단계에서 네트워크 X_θ가 현재 노이즈가 섞인 샘플 x_t와 조건 c, 시간 단계 t를 입력받아 목표 RIR x_0를 직접 예측한다(x‑prediction). 이는 기존의 노이즈 예측 방식보다 파형 자체를 복원하도록 학습되므로, 입력이 불완전하거나 길이가 가변적이어도 연속적인 출력이 가능하다.
네트워크는 1‑D U‑Net 구조에 7번의 스트라이드‑2 다운샘플링을 적용해 최대 32 768 샘플(≈2 s)까지 처리할 수 있다. 병목부에서는 6층 팽창 컨볼루션(다이레이트 1~32)으로 장시간 의존성을 포착한다. 조건자 c와 노이즈 샘플 x_t는 채널 차원으로 결합해 입력한다. 학습 시에는 확률 p_CFG=0.2로 조건을 0으로 대체해 무조건부와 조건부 두 모드를 동시에 학습한다. 추론 단계에서는 무조건부 예측 ˆx_uc와 조건부 예측 ˆx_c를 각각 얻고, 가이드 스케일 s를 곱해 ˆx_CFG = ˆx_uc + s(ˆx_c‑ˆx_uc) 로 결합한다. s≥1이면 조건에 더 강하게 따르지만 다양성은 감소한다.
손실 함수는 기본 MSE와 에너지 감소 곡선(EDC) 손실을 가중합(L_total = L_MSE + λ L_EDC)으로 구성한다. EDC는 Schroeder 역통합을 통해 계산되며, -60 dB 이하를 클램프한다. λ는 10⁻⁵ 로 설정해 EDC 재현성을 크게 향상시켰다.
실험은 두 개의 페어링된 데이터셋을 사용한다. 첫 번째는 pyroomacoustics 기반 ISM 시뮬레이션, 두 번째는 Treble SDK의 수치 파동 시뮬레이션이다. 두 데이터셋은 동일한 방 크기·재료·소스·리시버 배치를 공유하지만, Treble 데이터는 가구에 의한 파동 간섭·회절을 포함한다. 각각 10 000개의 RIR을 생성하고, 8:1:1 비율로 훈련·검증·테스트 셋을 나눈다. 모든 RIR은 16 kHz에서 48 kHz로 업샘플링 후 24 576 샘플(≈1.5 s)로 정규화한다.
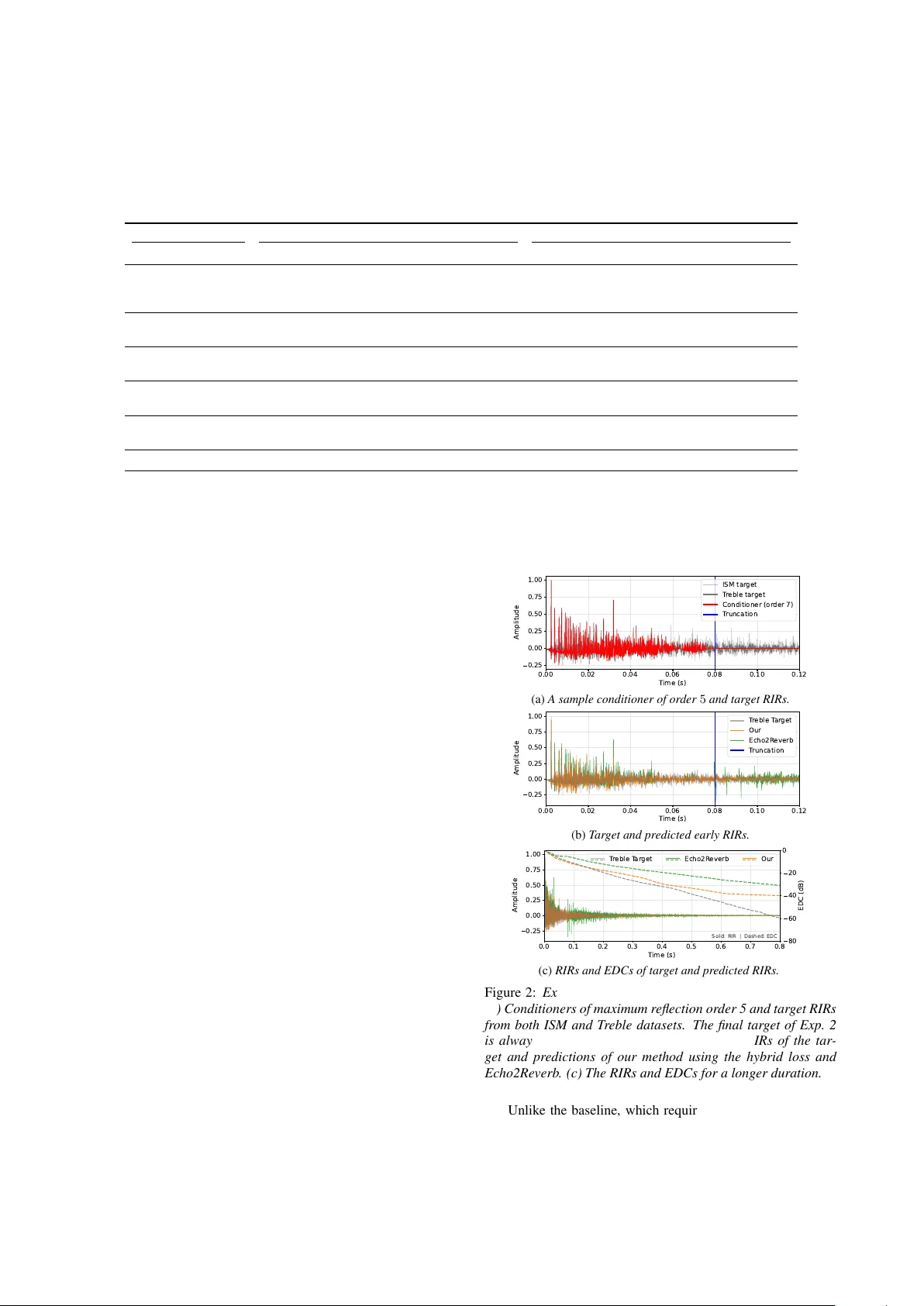
조건자는 ISM으로부터 최대 반사 차수 1,3,5,7을 지정해 80 ms 길이로 만든다. 차수 7조차도 80 ms를 완전히 채우지 못한다는 점을 강조한다. Baseline인 Echo2Reverb은 80 ms 전체를 트렁케이션한 RIR을 입력으로 사용한다.
평가 지표는 (i) 초기 80 ms 구간에서 조건자를 제외한 잔여 에너지 비율(RER), (ii) 80 ms 이후 RMSE, (iii) -60 dB 이하를 제외한 EDC MAE이다. 실험 1에서는 동일한 ISM 데이터셋을 사용해 제안 모델과 Echo2Reverb을 비교했으며, 제안 모델은 입력 차수에 크게 영향을 받지 않으며, EDC 손실을 포함한 학습(M+E) 시 EDC MAE가 현저히 낮았다. 실험 2에서는 ISM와 Treble 데이터셋을 혼합해 CFG 훈련을 수행했으며, 대부분의 설정에서 제안 모델이 Echo2Reverb보다 RER·RMSE·EDC 모두에서 우수한 성능을 보였다. 특히 차수 1~5에서 초기 RER이 크게 개선되었으며, 차수 7에서는 레이트 리버버레이션까지 연속적인 파형을 생성했다.
결론적으로, x‑prediction 기반 확산 모델은 RIR와 같은 연속 신호 복원에 적합하고, ISM으로부터 얻은 불완전한 초기 반사만으로도 물리적으로 일관된 전체 RIR을 생성할 수 있음을 입증했다. 클래스프리 가이던스를 통해 파동 효과가 포함된 데이터와 단순 기하학적 데이터 사이의 도메인 격차를 효과적으로 메우며, 실제 측정 RIR에 가까운 품질을 달성했다. 향후 연구에서는 실제 측정 RIR을 포함한 대규모 데이터로 확장하고, 실시간 인퍼런스 최적화 및 다채널(스테레오·서라운드) 확산 모델 적용을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기