분산 환경에서 교차 에이전트 잡음 없이 협력 학습을 가능하게 하는 하강 안내 정책 그래디언트
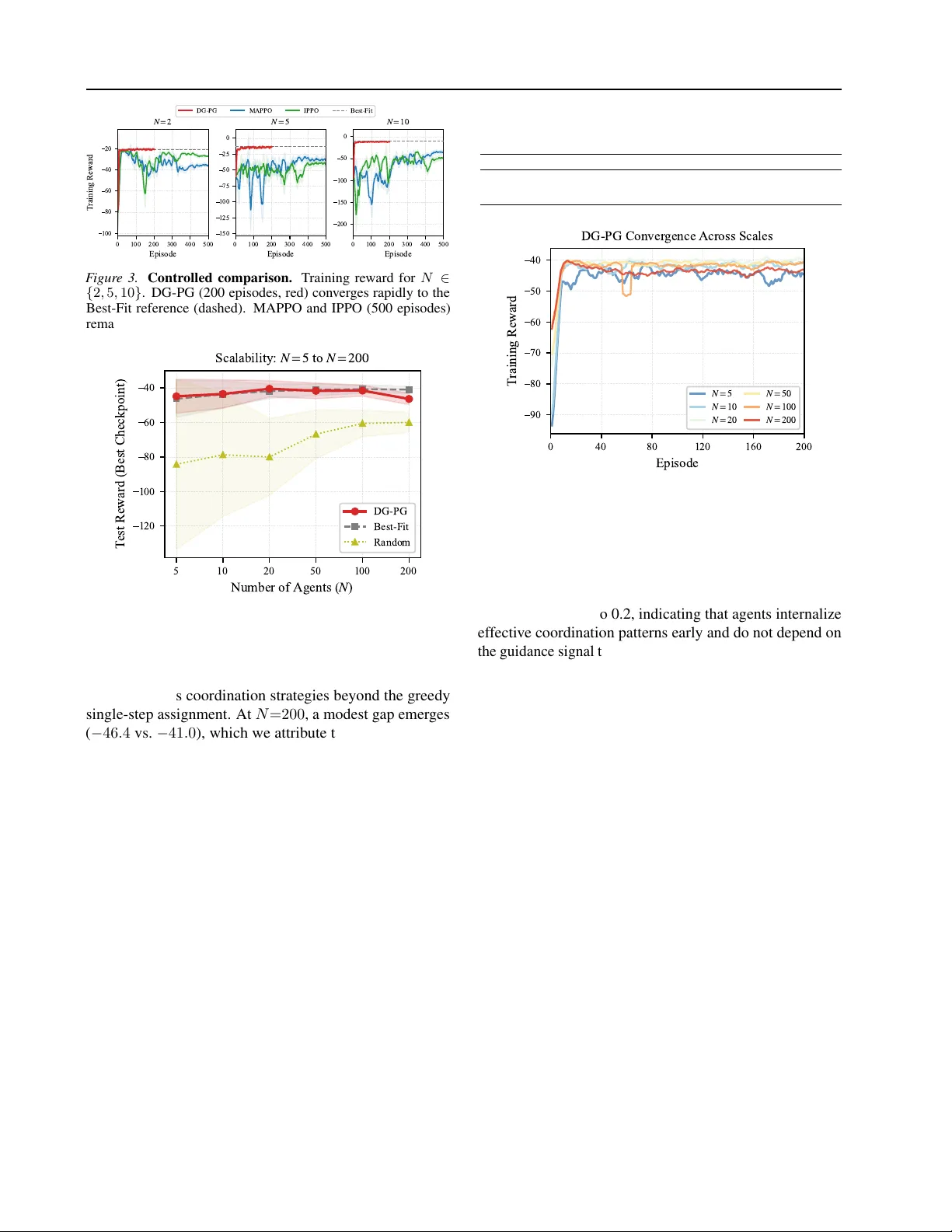
본 논문은 협력형 다중 에이전트 강화학습에서 에이전트 수가 증가함에 따라 발생하는 교차‑에이전트 잡음을 분석하고, 기존 정책 그래디언트의 분산이 Θ(N)에서 O(1)로 감소하도록 하는 ‘하강 안내 정책 그래디언트(DG‑PG)’ 프레임워크를 제안한다. 도메인별 미분 가능한 분석 모델을 활용해 각 에이전트에 잡음‑없는 개별 그래디언트를 제공함으로써 샘플 복잡도를 O(1/ε)로 만들고, Nash 균형을 보존한다. 클라우드 스케줄링 실험에서 N=5~2…
저자: Shan Yang, Yang Liu
**1. 연구 배경 및 문제 정의**
협력형 다중 에이전트 강화학습(Cooperative MARL)에서는 모든 에이전트가 동일한 전역 보상을 공유한다. 이때 각 에이전트의 정책 파라미터에 대한 정책 그래디언트는 전역 보상의 샘플링된 반환 Rₜ에 의존한다. 반환은 모든 에이전트의 행동 aₜ=(a₁ₜ,…,a_Nₜ)에 의해 결정되므로, 개별 에이전트의 그래디언트 추정기에 교차‑에이전트 잡음이 포함된다. Kuba et al.(2021)는 이 잡음이 에이전트 수 N에 대해 선형적으로 증가함을 수학적으로 증명했으며, 결과적으로 분산이 Θ(N), 샘플 복잡도가 O(N/ε)로 스케일링한다. 이는 실제 시스템(수십~수백 에이전트)에서 학습이 비효율적으로 되는 주요 원인이다.
**2. 기존 접근법의 한계**
- *Credit decomposition*: COMA, Counterfactual baselines 등은 각 에이전트의 기여도를 추정하려 하지만, 여전히 전역 반환에 기반하므로 교차 잡음을 완전히 제거하지 못한다.
- *Value factorization*: QMIX, QTRAN 등은 전역 Q값을 분해하지만, 학습 과정에서 여전히 전역 보상을 사용한다.
- *Pre‑designed controllers*: 기존 제어기나 규칙 기반 정책을 베이스라인으로 사용하면 잡음이 감소하지만, 정책이 해당 베이스라인에 과도하게 얽히게 되어 최적 해에 도달하기 어렵다.
**3. 핵심 아이디어: 분석 모델 기반 ‘참조 상태’**
다수의 실제 도메인(클라우드 스케줄링, 교통 흐름, 전력 배분)에서는 수십 년간 연구된 미분 가능한 분석 모델이 존재한다. 이러한 모델은 시스템이 최적에 가까운 상태(예: 최소 평균 대기시간, 최소 전력 손실)를 예측한다. 논문은 이 모델을 ‘참조 상태’ ˜xₜ로 정의하고, 현재 시스템 상태 xₜ와의 차이를 편차 함수 d(xₜ,˜xₜ)=½‖xₜ−˜xₜ‖²로 측정한다.
**4. 가정**
- *Exogeneity (Assumption 3.1)*: ˜xₜ는 정책 파라미터 θ에 의존하지 않는다(∇θ˜xₜ=0). 즉, 분석 모델은 외부 입력(예: 작업 도착률)만을 사용한다.
- *Descent‑aligned reference (Assumption 3.2)*: ˜xₜ가 실제 목표 함수 J를 증가시키는 방향에 있다. 즉, ⟨∇ₓJ(xₜ),˜xₜ−xₜ⟩>0.
이 두 가정은 대부분의 물리·경제 기반 시스템에서 자연스럽게 만족한다.
**5. DG‑PG 프레임워크**
1) *편차 측정*: d(xₜ,˜xₜ)를 정의한다.
2) *로컬 영향 벡터*: 각 에이전트 i가 시스템 상태에 미치는 영향 zᵢₜ=∂xₜ/∂aᵢₜ를 계산한다. 이는 도메인별 모델링을 통해 얻을 수 있다(예: 작업 할당 시 특정 서버의 CPU 사용량 변화).
3) *가이드 그래디언트*: ∇θᵢG = E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기