PulmoVec 소아 호흡음 다중 과제 분류를 위한 두 단계 스태킹 메타러닝 모델
PulmoVec은 대규모 자기지도 학습 기반 오디오 파운데이션 모델인 HeAR를 백본으로 활용하고, 세 가지 별도 과제(정상/비정상 스크리닝, 소리 패턴 인식, 질병군 예측)를 위한 베이스 분류기와 인구통계 메타데이터를 결합한 LightGBM 스태킹 메타모델을 적용한 2단계 아키텍처이다. SPRSound 데이터베이스(1,652명, 24,808 이벤트)에서 이벤트 수준에서는 ROC‑AUC 0.96~0.94, 환자 수준에서는 질병군 정확도 0.74…
저자: Izzet Turkalp Akbasli, Oguzhan Serin
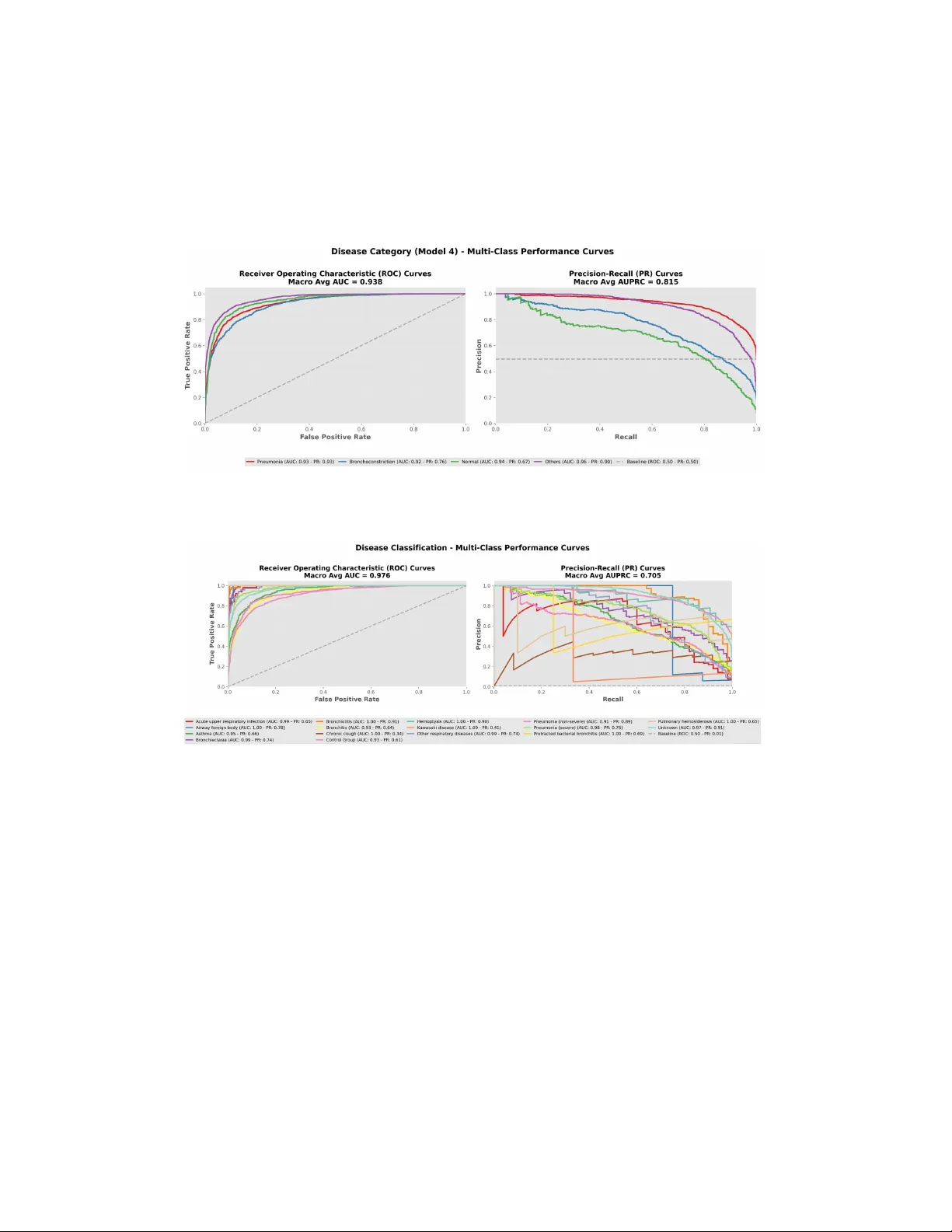
본 연구는 소아 호흡음의 객관적 분석을 목표로, 대규모 자기지도 학습 기반 오디오 파운데이션 모델인 Health Acoustic Representations(HeAR)를 백본으로 하는 다중 과제 스태킹 메타러닝 프레임워크 PulmoVec을 제안한다. 데이터는 공개된 SPRSound 데이터베이스에서 1,652명의 소아 환자(총 24,808개의 이벤트 레벨 세그먼트)를 추출했으며, 중복 제거·저품질 레코드 제외·이벤트 라벨 누락 제거 등 3단계 정제 과정을 거쳐 최종 분석용 데이터를 구축하였다.
오디오 전처리는 16 kHz 모노로 재샘플링하고 2 초 윈도우(패딩·크롭)로 정규화했으며, 이벤트 경계 주변에 10% 오버랩을 적용해 경계 손실을 최소화했다. HeAR 모델을 통해 각 세그먼트당 512차원 임베딩을 추출한 뒤, 동일한 구조(512→256→출력)와 dropout(0.3)을 가진 세 개의 베이스 분류기를 학습시켰다. 첫 번째 베이스 모델은 Normal/Abnormal을 구분하는 스크리닝 과제, 두 번째는 Normal, Crackles, Rhonchi의 3가지 소리 패턴 인식, 세 번째는 16가지 원본 질병 라벨을 임상적으로 의미 있는 4가지 그룹(폐렴, 기관지 질환, 정상, 기타)으로 매핑한 질병군 예측 과제에 사용되었다.
학습은 두 단계로 진행되었다. 1단계에서는 HeAR 인코더를 고정하고 10 epoch, 학습률 1e‑4로 헤드만 최적화했으며, 2단계에서는 전체 모델을 해제해 40 epoch, 학습률 5e‑7로 미세조정했다. 클래스 불균형은 손실 함수에 역비율 가중치를 부여해 보정했으며, 검증 ROC‑AUC를 기준으로 조기 종료를 적용했다.
베이스 모델 훈련이 완료된 후, 각 모델의 out‑of‑fold 확률 예측을 수집해 9개의 확률 피처를 만든 뒤, 연령, 성별, 녹음 위치(4개 위치) 등 3개의 인구통계 변수를 추가해 11차원 메타 피처를 구성했다. 이 메타 피처를 입력으로 LightGBM 메타모델을 학습했으며, Optuna 기반 베이지안 최적화를 통해 트리 개수, 최대 깊이, 학습률, 정규화 파라미터 등을 과제별로 최적화했다.
환자‑레벨 예측을 위해서는 이벤트‑레벨 결과를 세 가지 투표 전략으로 결합했다. 소프트 투표(30%)는 각 클래스의 평균 확률을 사용하고, 신뢰도 가중 투표(40%)는 확률이 0.7 이상인 이벤트에 가중치를 부여했으며, 다수결 투표(30%)는 최소 60% 이벤트가 동일 클래스에 동의하고 50% 이상이 높은 신뢰도를 보일 때만 적용했다. 최종 환자‑레벨 예측은 세 전략의 가중 선형 결합으로 산출되었다.
성능 평가는 이벤트‑레벨와 환자‑레벨 모두에서 다중 지표를 사용했다. 이벤트‑레벨에서는 스크리닝 모델이 정확도 0.92, 가중‑F1 0.92, ROC‑AUC 0.96을 기록했으며, 소리 패턴 모델은 정확도 0.91, 가중‑F1 0.91, 매크로 ROC‑AUC 0.96을 달성했다. 질병군 모델은 정확도 0.80, 가중‑F1 0.79, 매크로 ROC‑AUC 0.94를 보였다. 베이스 모델 대비 메타 모델은 모든 과제에서 9~12%p의 성능 향상을 나타냈다. 환자‑레벨에서는 질병군 분류에서 정확도 0.74, 가중‑F1 0.73, 매크로 ROC‑AUC 0.91을 기록했으며, 95% 부트스트랩 신뢰구간도 제시했다.
논문은 다음과 같은 의의를 가진다. 첫째, 대규모 일반 오디오에 사전 학습된 파운데이션 모델을 소아 호흡음에 성공적으로 전이시켜, 데이터 부족 문제를 완화했다. 둘째, 다중 과제 스태킹 구조가 개별 과제의 한계를 보완하고, 인구통계 정보를 통합함으로써 임상적 해석 가능성을 높였다. 셋째, 이벤트‑레벨에서 환자‑레벨로의 체계적인 앙상블 전환이 실제 임상 의사결정 흐름에 부합한다는 점을 보여준다.
하지만 한계도 명확하다. 데이터가 단일 기관(상하이 어린이 의료센터)에서 수집된 SPRSound에 국한돼 있어, 장치 다양성·인구학적 차이에 대한 외부 검증이 부족하다. 또한 HeAR가 유튜브 기반 일반 음성에 최적화돼 있어, 소아 호흡음 특유의 저주파·노이즈 특성을 완전히 포착했는지는 추가 실험이 필요하다. 향후 연구에서는 다기관·다장치 데이터셋을 활용한 외부 검증, 실시간 스트리밍 환경에서의 적용, 그리고 SHAP·Grad‑CAM 등 모델 설명성 기법을 도입해 임상의 신뢰를 높이는 것이 요구된다.
결론적으로 PulmoVec은 파운데이션 오디오 모델과 메타러닝을 결합한 최초의 소아 호흡음 다중 과제 분류 시스템으로, 이벤트‑레벨 음향 페노타이핑과 환자‑레벨 임상 분류를 효과적으로 연결한다. 향후 다중 센터 검증과 실시간 임상 적용을 통해 디지털 청진의 실용성을 크게 확대할 잠재력을 지닌다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기