지식 없이 추론을 증류한다: 신뢰할 수 있는 대형 언어 모델 프레임워크
본 논문은 추론과 사실 획득을 명시적으로 분리한 모듈형 파이프라인을 제안한다. 교사‑학생 방식으로 경량 플래너를 학습시켜 질문을 추상적 단계와 검색 가능한 사실 요청으로 분해하고, 외부 검색·추출·집계 모듈이 실제 근거를 제공한다. SEAL‑0 벤치마크에서 정확도와 지연 시간 모두 기존 단일 모델 방식보다 우수함을 입증한다.
저자: Auksarapak Kietkajornrit, Jad Tarifi, Nima Asgharbeygi
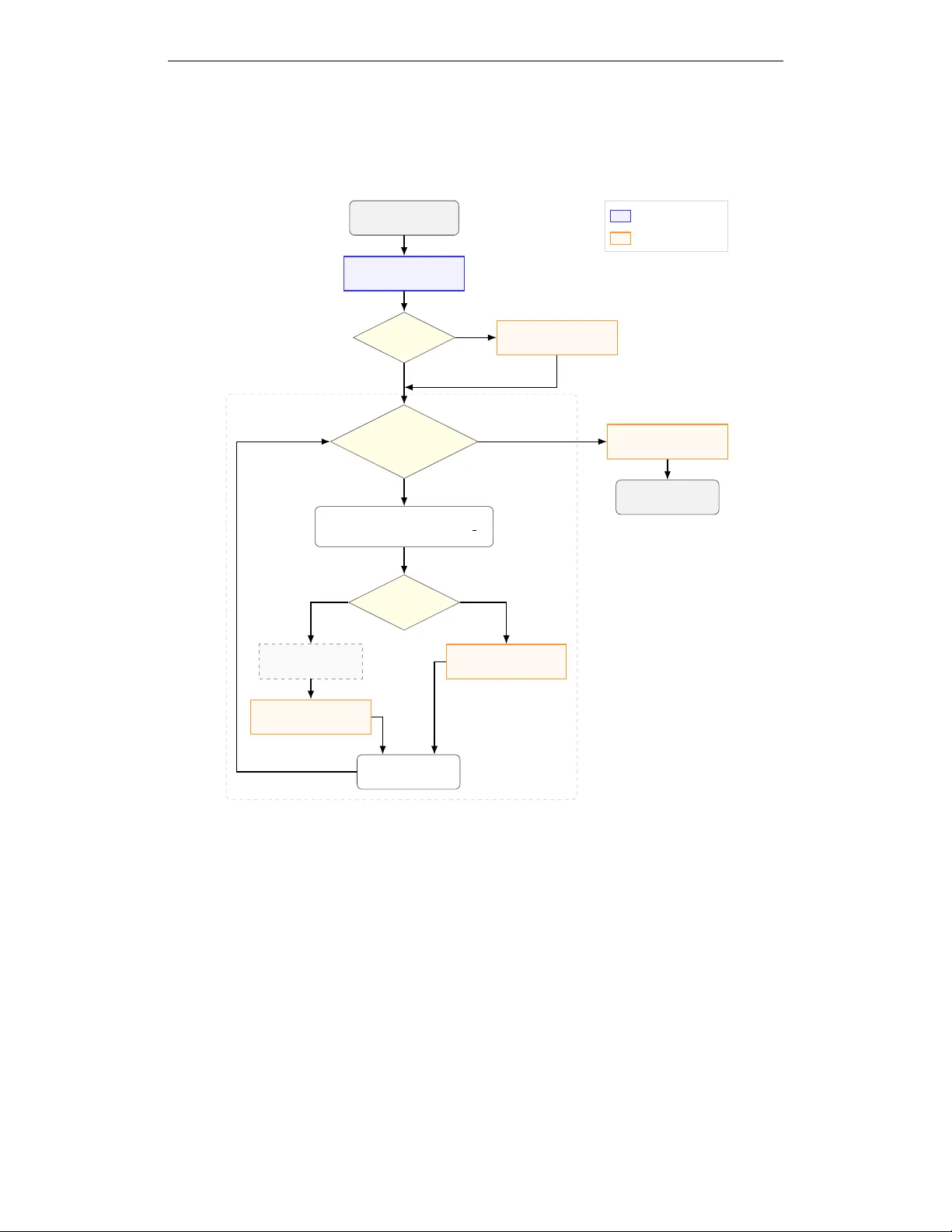
본 논문은 대형 언어 모델(LLM)이 최신성이나 충돌이 잦은 사실을 요구받을 때 흔히 발생하는 ‘환각’ 문제를 해결하기 위해, 추론 과정과 사실 획득 과정을 명시적으로 분리하는 모듈형 프레임워크를 제안한다. 기존의 검색‑증강(RAG) 혹은 툴‑사용 LLM은 하나의 모델이 질문을 이해하고, 필요한 정보를 판단하며, 검색을 수행하고, 그 결과를 다시 내부적으로 통합하는 복합적인 과정을 동시에 수행한다. 이러한 구조는 오류 원인을 단계별로 파악하기 어렵게 만들고, 불필요한 검색 호출이나 중복 연산을 야기한다.
제안된 시스템은 크게 네 단계로 구성된다. 첫 번째는 ‘플래너’ 단계로, 경량 플래너가 질문을 받아 (i) 추상적인 추론 단계 시퀀스 R과 (ii) 외부에서 반드시 획득해야 할 원자적 사실 요청 집합 F를 생성한다. 두 번째는 ‘검색’ 단계로, 각 사실 요청 f∈F는 지정된 소스(웹 또는 계산)와 의존 플래그에 따라 SerpAPI를 통한 실시간 웹 검색 혹은 내부 LLM을 이용한 계산 작업으로 실행된다. 세 번째는 ‘추출’ 단계로, 웹 검색 결과는 JSON 형태로 반환되며, 별도 프롬프트‑엔지니어링된 추출 모듈이 이를 읽어 간결하고 정확한 원자 사실 ˆx 로 압축한다. 네 번째는 ‘집계’ 단계로, 최종 집계 모듈은 원 질문, 플래너가 제공한 추론 단계, 그리고 모든 추출된 사실을 근거로 최종 답변을 생성한다. 집계 프롬프트는 근거가 부족할 경우 “알 수 없음”을 명시하도록 설계돼, 모델이 근거 없는 주장을 하는 것을 방지한다.
플래너 학습은 교사‑학생 프레임워크를 이용한다. 교사 모델은 GPT‑5.2이며, 질문당 (R, F) 형태의 구조화된 플랜을 생성하도록 강제한다. 교사는 절대 정답이나 검색 결과를 제공하지 않으며, 오직 “어떤 정보를 찾아야 하는가”만을 명시한다. 이렇게 만든 1,596개의 (질문, 플랜) 쌍을 기반으로, 경량 오픈소스 모델 Qwen‑3‑8B를 QLoRA 방식으로 미세조정한다. 중요한 점은 학생 플래너가 내부 지식을 학습하도록 유도하지 않으며, 오직 플랜 구조와 검색‑가능한 쿼리 형식만을 모방한다는 것이다.
실험은 최신 검색‑증강 QA 벤치마크인 SEAL‑0을 사용했다. SEAL‑0은 최신성, 모순, 잡음이 섞인 웹 증거를 포함해 기존 모델이 거의 0% 정확도를 보이는 난이도가 높은 데이터셋이다. 제안된 프레임워크는 기존 단일 LLM 기반 체인(예: 직접 답변, 프롬프트 기반 도구 호출)보다 정확도와 응답 지연 모두에서 우수한 결과를 기록했다. 특히 플래너가 명시적으로 의존 관계를 관리함으로써 불필요한 검색을 줄이고, 경량 플래너가 8B 파라미터 규모임에도 불구하고 대형 모델 대비 2‑3배 빠른 추론 속도를 달성했다.
핵심 통찰은 “지식 증류가 아니라 추론 증류”라는 패러다임 전환이다. 모델이 사실 자체를 기억하도록 강요하기보다, 언제 외부 정보를 요청해야 하는지를 학습시키는 것이 더 효율적이며, 시스템 전반의 투명성과 디버깅 가능성을 크게 향상시킨다. 또한 플래너와 도구 모듈을 독립적으로 개선할 수 있어, 검색 엔진 교체, 추출기 강화, 집계 프롬프트 튜닝 등 모듈별 최적화가 용이하다. 향후 연구에서는 플래너의 자동 오류 복구, 다중 도구(데이터베이스, API) 연동, 그리고 플래너 자체에 대한 메타‑학습을 통해 더욱 복잡한 에이전트 시스템으로 확장할 여지가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기