프로그래머블 캐시 엔진의 한계와 향후 과제
CacheLib은 높은 성능과 이식성을 제공하지만, 동적·다중 테넌트 환경에서는 고정된 설정과 제한된 런타임 적응성 때문에 메모리 비효율·테넌트 기아가 발생한다. 본 논문은 다양한 워크로드와 메모리 파티셔닝을 실험적으로 분석하고, 적응형 재조정·QoS·인스턴스 간 협조가 필요함을 제시한다.
저자: José Peixoto, Alexis Gonzalez, Janki Bhimani
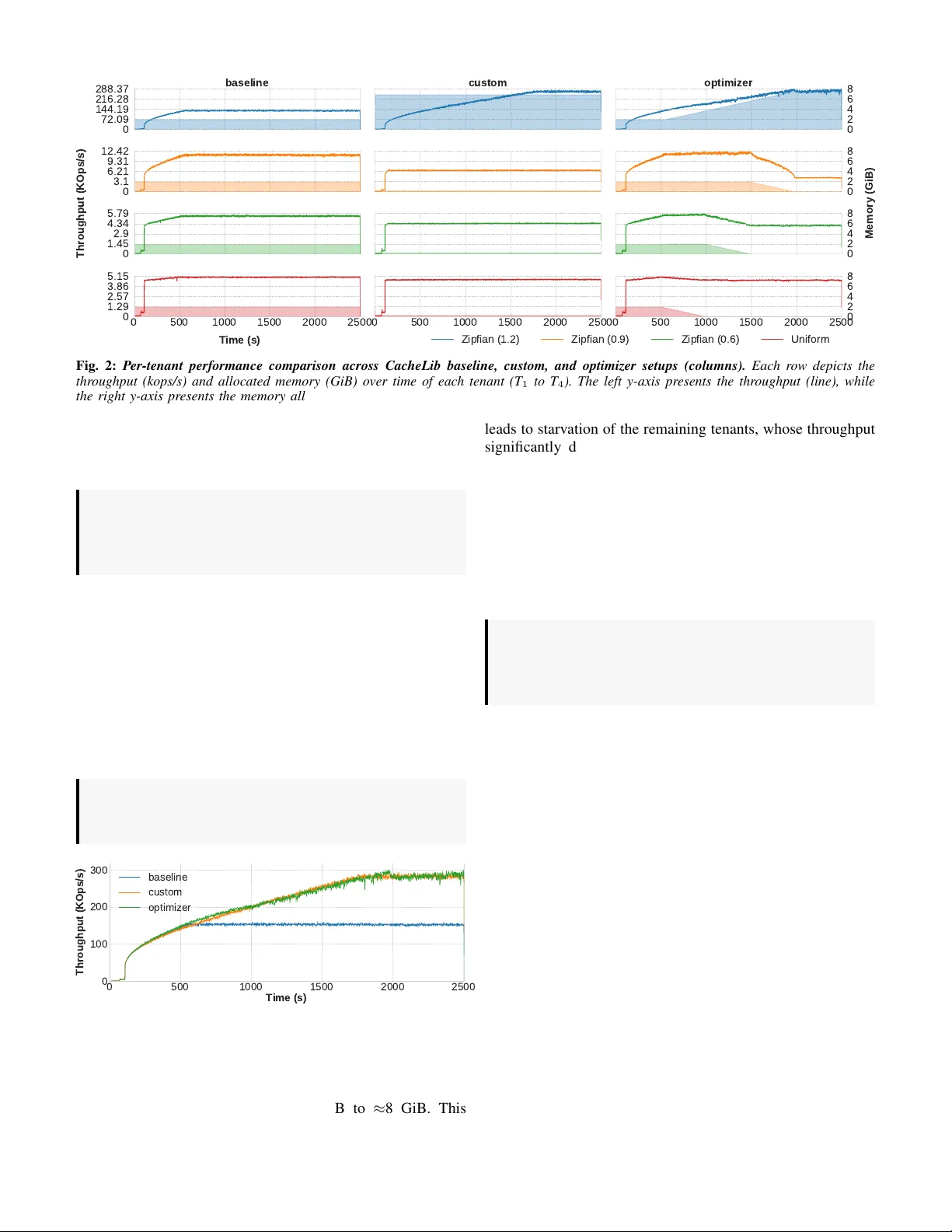
본 논문은 Meta에서 개발한 범용 프로그래머블 캐시 엔진인 CacheLib을 다중 테넌트·동적 워크로드 환경에서 평가하고, 현재 설계가 갖는 구조적 한계를 규명한다. 먼저 CacheLib의 아키텍처를 소개한다. CacheLib은 메모리 풀, 슬랩 기반 할당, 풀 리밸런서·리사이저·옵티마이저 등 세 개의 백그라운드 워커를 통해 메모리 파편화 감소와 자동 메모리 재조정을 목표로 한다. 각 테넌트는 독립된 메모리 풀을 할당받아 격리되지만, 풀의 메모리 한계는 초기 설정 시 고정되며 런타임에 즉시 반영되지 않는다. 실험은 4개의 테넌트를 대상으로 수행했으며, T1·T2·T3은 각각 Zipfian 스키드 1.2, 0.9, 0.6을, T4는 균등 분포를 갖는 읽기 전용 워크로드를 2500 초 동안 실행했다. 전체 데이터는 80 GiB이며, CacheLib 캐시 용량은 8 GiB(전체의 10 %)로 제한했다. 세 가지 설정을 비교했다. (1) Baseline: 기본 설정으로 풀 리밸런서만 활성화, 메모리를 균등 배분. (2) Custom: 사용자가 정의한 비율로 메모리를 재분배, 풀 리사이저와 결합. (3) Optimizer: 풀 리사이저와 자동 옵티마이저를 1 초 간격으로 실행, 초기에는 균등 배분 후 실시간 히트 비율 기반 재조정. 결과는 다음과 같다. Baseline에서는 T1이 140 kops/s로 다른 테넌트보다 14~28배 높은 처리량을 보이며, 메모리 할당이 균등함에도 불구하고 히트 비율 차이로 성능 격차가 크게 나타났다. Custom 설정은 T1에 91 % 메모리를 할당함으로써 전체 스루풋을 1.8배 향상시켰지만, 이는 편향된 자원 배분이며 공정성 측면에서 문제가 있다. Optimizer 설정은 초기 500 초 동안 통계 수집에 머무르지만, 이후 메모리를 동적으로 재배분해 전체 스루풋을 1.85배까지 끌어올렸다. 그러나 급격한 워크로드 변동 시 재조정 지연이 발생하고, 최적화 목표가 전역 히트 비율에만 초점돼 특정 테넌트가 지속적으로 자원을 독점한다. 또한, 동일 노드에 다중 CacheLib 인스턴스가 존재할 경우 인스턴스 간 메모리 공유나 협조가 전혀 이루어지지 않아, 전체 시스템 차원에서 비효율이 가중된다. 논문은 이러한 관찰을 바탕으로 네 가지 주요 제한점을 제시한다. 첫째, 설정이 고정적이라 동적 워크로드에 즉각 대응하지 못한다. 둘째, 풀 옵티마이저와 리사이저가 실제 워크로드 변화에 충분히 빠르게 적응하지 못한다. 셋째, QoS·우선순위·공정성 메커니즘이 부재해 테넌트 기아 현상이 발생한다. 넷째, 인스턴스 간 협조·전역 메모리 재배분 체계가 없어 전체 자원 활용도가 낮다. 마지막으로, 이러한 한계를 극복하기 위해 향후 연구에서는 (1) 런타임에 설정을 동적으로 조정할 수 있는 정책 프레임워크, (2) 테넌트별 QoS SLA를 지원하는 다중 레벨 캐시 관리, (3) 인스턴스 간 메모리 공유와 협조를 위한 중앙 조정자, (4) 머신러닝 기반 워크로드 예측 및 사전 재조정 기법 등을 제안한다. 결론적으로, CacheLib은 프로그래머블 캐시 엔진으로서 강력한 빌딩 블록을 제공하지만, 현대 데이터 집약형 서비스가 요구하는 동적·다중 테넌트 환경에서는 적응성, 공정성, 협조 메커니즘이 크게 부족함을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기