텍스트‑비디오 확산 모델의 조기 실패 탐지와 실시간 개입
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
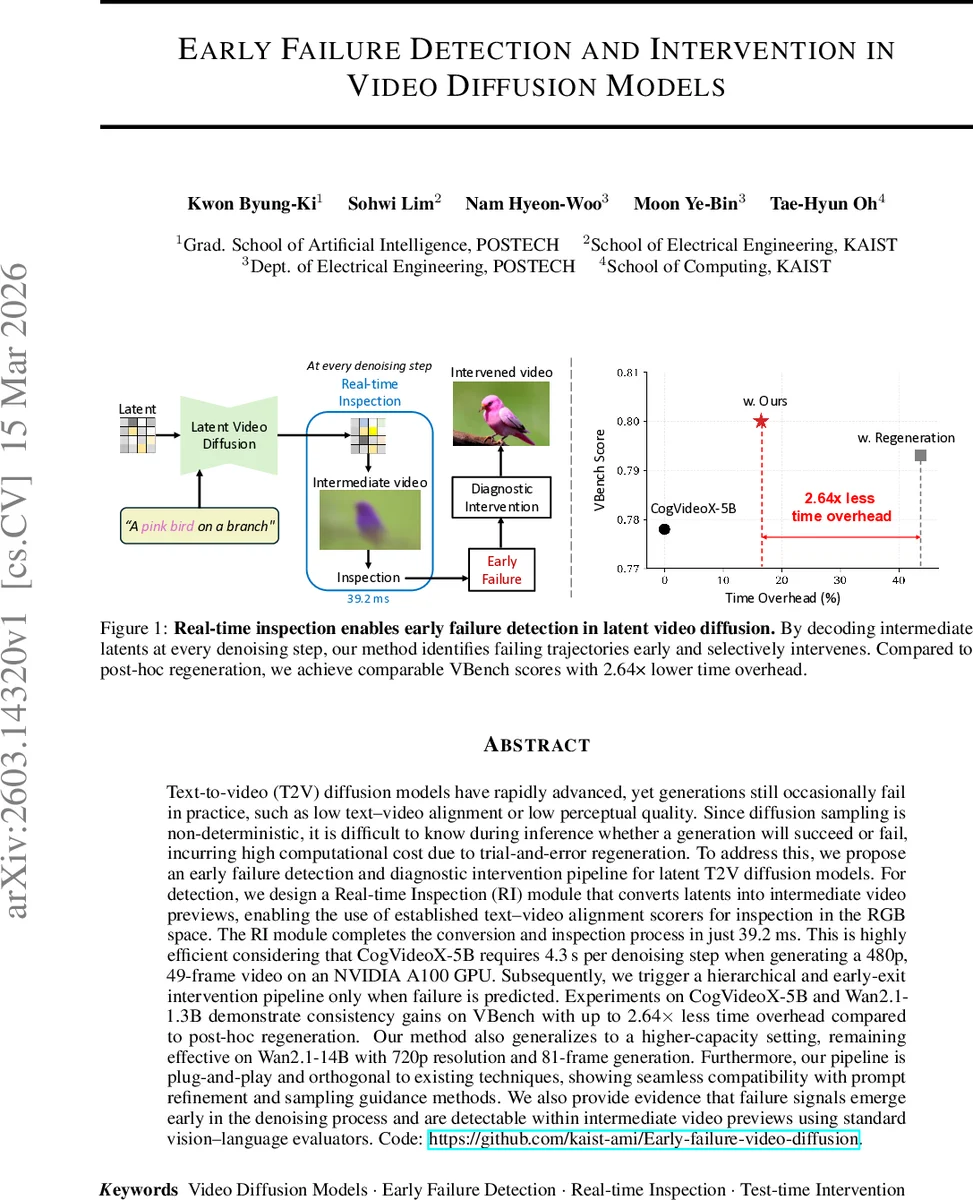
본 논문은 잠재 공간에서 진행되는 텍스트‑투‑비디오 확산 모델의 샘플링 과정을 실시간으로 감시하고, 실패가 예측될 경우 단계별 경량 개입을 수행하는 파이프라인을 제안한다. 핵심은 39.2 ms 만에 중간 잠재를 RGB 영상으로 복원하는 Real‑time Inspection(RI) 모듈과, 정렬 점수 기반 동적 실패 탐지기를 결합한 것이다. 실패가 감지되면 저비용의 단일 프레임 의미 주입, 프롬프트 재구성 등 세 단계의 계층적 개입을 순차적으로 적용해 전체 재생성 비용을 2.64배 절감하면서 VBench 지표를 향상시킨다.
상세 분석
이 연구는 현재 텍스트‑비디오(T2V) 확산 모델이 비정형적인 텍스트‑비디오 정렬 오류와 저품질 프레임을 포함한 실패를 사전에 식별하기 어려운 문제를 해결한다. 기존 방법들은 모델 자체를 미세조정하거나 샘플링 가이던스를 추가하는 방식으로 품질을 향상시켰지만, 샘플 진행 상황을 모니터링하지 않아 불필요한 전체 재생성 비용이 발생한다. 논문은 두 가지 핵심 구성요소를 도입한다.
-
Real‑time Inspection(RI) 모듈
- 잠재(z) → RGB 영상 변환을 담당하는 L2R(Latent‑to‑RGB) 컨버터는 0.059 M 파라미터만을 사용해 19.7 ms에 480p, 49프레임 영상을 복원한다. 이는 기존 CogVideoX 디코더(≈4 s) 대비 200배 이상 빠른 속도다.
- 변환된 영상은 ViCLIP 기반 정렬 스코어러에 입력되어 텍스트와의 의미 일치도를 실시간으로 측정한다. 텍스트 인코더 출력은 캐시해 CPU 병목을 최소화하고, 영상‑텍스트 정렬 점수(sₜ)를 19.5 ms 안에 산출한다.
- 전체 RI 파이프라인은 39.2 ms라는 낮은 레이턴시로 매 샘플링 단계마다 “성공/실패” 신호를 제공한다.
-
동적 실패 탐지기와 계층적 개입
- 중간 정렬 점수들의 시퀀스 {sₖ}를 입력으로 최종 정렬 점수 Ŝ₀를 예측하는 경량 모델을 사용한다. 임계값 τ(=0.22) 이상이면 성공, 이하이면 실패로 판단한다.
- 실패가 감지되면 세 단계의 개입을 순차적으로 적용한다.
- Trial 1 – 단일 프레임 의미 주입: 동일 프롬프트로 단일 이미지 프리뷰를 생성하고, 그 정렬 점수 Ŝ_img가 현재 비디오 점수보다 δ(=0.05) 이상 높으면 해당 이미지의 잠재를 영상 생성 초기(1~2 스텝)에서 재주입한다. 이는 시간 비용이 매우 낮으며, 의미 일관성을 회복한다.
- Trial 2 – 관찰 기반 프롬프트 재구성: 이미지 주입으로도 개선되지 않을 경우, VLM(Visual Language Model)을 이용해 현재 프리뷰와 원본 프롬프트를 비교, 시각적 결함을 보완한 새로운 프롬프트를 생성한다. 재시작된 샘플링은 기존 파이프라인을 그대로 사용한다.
- Trial 0 – 기본 생성: 초기 정렬 점수가 충분히 높으면 개입 없이 그대로 진행한다.
- 최악 상황에서도 세 단계 전체 비용은 전체 재생성 비용의 56 %에 불과해, 기존 “생성‑검사‑재시도” 루프 대비 2.64배 효율성을 달성한다.
실험 결과
- CogVideoX‑5B와 Wan2.1‑1.3B 모델에 적용했을 때 VBench 전반적인 점수가 향상되었으며, 특히 텍스트‑비디오 정렬과 시간 일관성 지표에서 큰 개선을 보였다.
- 높은 용량 모델인 Wan2.1‑14B(720p, 81프레임)에서도 동일 파이프라인이 유효함을 입증, 스케일에 대한 강인성을 확인했다.
- 다양한 기존 가이드(프롬프트 리파인먼트, CFG 등)와 병행 사용했을 때도 성능 저하 없이 호환 가능함을 보이며, 플러그‑인 형태의 설계가 강조된다.
의의와 한계
- 영상 디퓨전의 중간 상태를 RGB로 빠르게 시각화함으로써 인간이 직관적으로 판단할 수 있는 “시각적 피드백 루프”를 제공한다는 점에서 큰 혁신이다.
- 현재는 ViCLIP 기반 정렬 점수에 의존하므로, 텍스트‑비디오 정렬 평가가 약한 경우 탐지 정확도가 떨어질 수 있다. 또한 L2R 컨버터는 저해상도 복원에 최적화돼 있어, 고해상도(4K) 영상에서는 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기