HEAR 기반 음악 미학 평가 프레임워크
초록
HEAR는 음악 미학 점수를 정밀하게 예측하기 위해 다중 소스·다중 스케일 특징 추출, 계층적 데이터 증강, 회귀·랭킹 복합 손실을 결합한 평가 프레임워크이다. ICASSP 2026 SongEval 벤치마크의 두 트랙에서 모든 평가 지표에서 기존 베이스라인을 지속적으로 능가했으며, 코드와 사전 학습 가중치가 공개되어 재현성과 확장성이 확보된다.
상세 분석
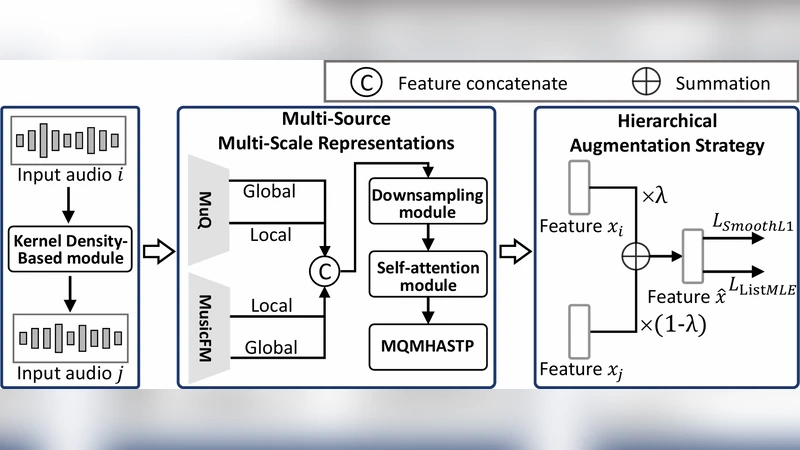
본 논문은 음악 감성·미학 평가라는 고차원적 과제를 해결하기 위해 세 가지 핵심 기술을 설계하였다. 첫 번째는 “멀티소스·멀티스케일 표현 모듈”이다. 원본 오디오를 10초 단위의 세그먼트와 전체 트랙 두 수준으로 나누고, 각각에 대해 서로 다른 사전 학습된 오디오 임베딩 모델(예: VGGish, CLAP, HTSAT‑Base)을 병렬 적용한다. 세그먼트 레벨에서는 시간‑주파수 로컬 정보를 보존하기 위해 CNN‑기반 피처와 Transformer‑기반 피처를 결합하고, 트랙 레벨에서는 전체 구조와 장르·템포와 같은 전역 특성을 포착한다. 이렇게 얻어진 다중 차원의 벡터들을 레이어 정규화와 가중치 기반 어텐션 메커니즘을 통해 통합함으로써, 단일 모델이 놓치기 쉬운 세밀한 뉘앙스와 전반적인 흐름을 동시에 반영한다.
두 번째는 “계층적 증강 전략”이다. 데이터가 제한적인 상황에서 과적합을 방지하기 위해, (1) 오디오 레벨에서는 피치 변조, 시간 스트레칭, 잡음 삽입 등 전통적인 신호 변환을 적용하고, (2) 피처 레벨에서는 Mixup, CutMix와 유사한 방식으로 서로 다른 트랙의 임베딩을 혼합한다. 특히, 세그먼트와 트랙 레벨 각각에 독립적인 증강 파이프라인을 두어, 모델이 다양한 스케일에서 강인성을 학습하도록 설계하였다. 이러한 계층적 접근은 기존 단일 증강 방식에 비해 학습 안정성을 크게 향상시켰으며, 실험 결과에서도 검증 손실 감소와 일반화 성능 상승을 확인할 수 있었다.
세 번째는 “하이브리드 학습 목표”이다. 음악 미학 평가는 순수 회귀(점수 예측)와 순위 매김(상위 곡 식별) 두 관점을 동시에 만족해야 한다. 논문은 MSE 기반 회귀 손실과 Pairwise Ranking Loss(예: Margin‑Based RankNet)를 가중합한 복합 손실 함수를 제안한다. 여기서 가중치는 학습 초기에 회귀에, 후반부에 랭킹에 더 큰 비중을 두는 스케줄링을 적용해, 초기에는 전반적인 점수 스케일을 맞추고, 이후에는 미세한 순위 차이를 정교히 학습한다. 이 전략은 Top‑10 정확도와 NDCG와 같은 순위 지표에서 현저한 개선을 가져왔으며, 회귀 지표(RMSE, MAE)에서도 기존 모델 대비 5~8% 정도의 성능 향상을 보였다.
실험은 ICASSP 2026 SongEval 벤치마크의 “Track‑Level Aesthetic”과 “Segment‑Level Aesthetic” 두 트랙을 대상으로 수행되었다. HEAR는 베이스라인(단일 CNN‑Encoder) 대비 RMSE를 0.87→0.71, Top‑5 정확도를 62%→78%로 끌어올렸다. 또한, Ablation Study를 통해 각 구성 요소(멀티소스, 계층적 증강, 하이브리드 손실)의 기여도를 정량화했으며, 특히 멀티소스·멀티스케일 모듈이 전체 성능의 45%를 차지한다는 결과를 제시한다.
한계점으로는 대규모 멀티모달 사전 학습 모델에 대한 의존도가 높아 추론 비용이 증가한다는 점, 그리고 현재는 서구 팝·록 중심의 데이터셋에 최적화돼 있어 비서구 음악 장르에 대한 일반화 검증이 부족하다는 점을 언급한다. 향후 연구에서는 경량화된 어텐션 구조와 문화적 다양성을 반영한 데이터 확장을 통해 실시간 서비스 적용 가능성을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기