스파이킹 신경망 가속을 위한 데이터 의존적 시간 집계 전략: Collapse vs Preserve
본 논문은 GPU에서 스파이킹 신경망(SNN)의 스파이크 희소성을 활용하려는 기존 시도가 실제로는 속도 향상을 가져오지 못함을 실증한다. 대신 시간 차원에서 K개의 프레임을 선형적으로 합쳐 한 번의 컨볼루션만 수행하는 Temporal Aggregated Convolution(TAC)을 제안한다. 정적(rate‑coded) 데이터에서는 잡음 감소 효과로 정확도가 상승하고 최대 13.8배의 가속을 달성한다. 반면 이벤트 기반 데이터에서는 시간 정보…
저자: Jiahao Qin
본 논문은 스파이킹 신경망(SNN)의 GPU 가속 가능성을 재검토하고, 기존에 널리 주장되어 온 “스파이크 희소성 → 연산량 감소”라는 가정이 현대 SIMD 기반 GPU에서는 실현되지 않음을 체계적으로 입증한다. 저자들은 Apple M3 Max GPU에서 5가지 희소성 활용 기법을 구현했으며, 각각은 Temporal Delta Convolution, Weight‑Gather Sparse Convolution, Graph Compilation, Sparse GEMM, Custom Metal SIMD Kernel이다. 실험 결과, 이들 모두 dense Conv2d보다 속도가 떨어졌고, 그 원인은 SIMD 유닛이 lane 별로 독립적인 분기를 지원하지 못해 전체 연산을 스킵할 수 있는 비율이 극히 낮기 때문이다. 구체적으로, 스파이크 발생률 ρ=0.1, SIMD 폭 W=32일 때 전체 lane이 0이 되는 확률은 (1‑ρ)^W≈3.5%에 불과해, 분기 검사 비용보다 이득을 얻지 못한다는 Proposition 1을 제시한다.
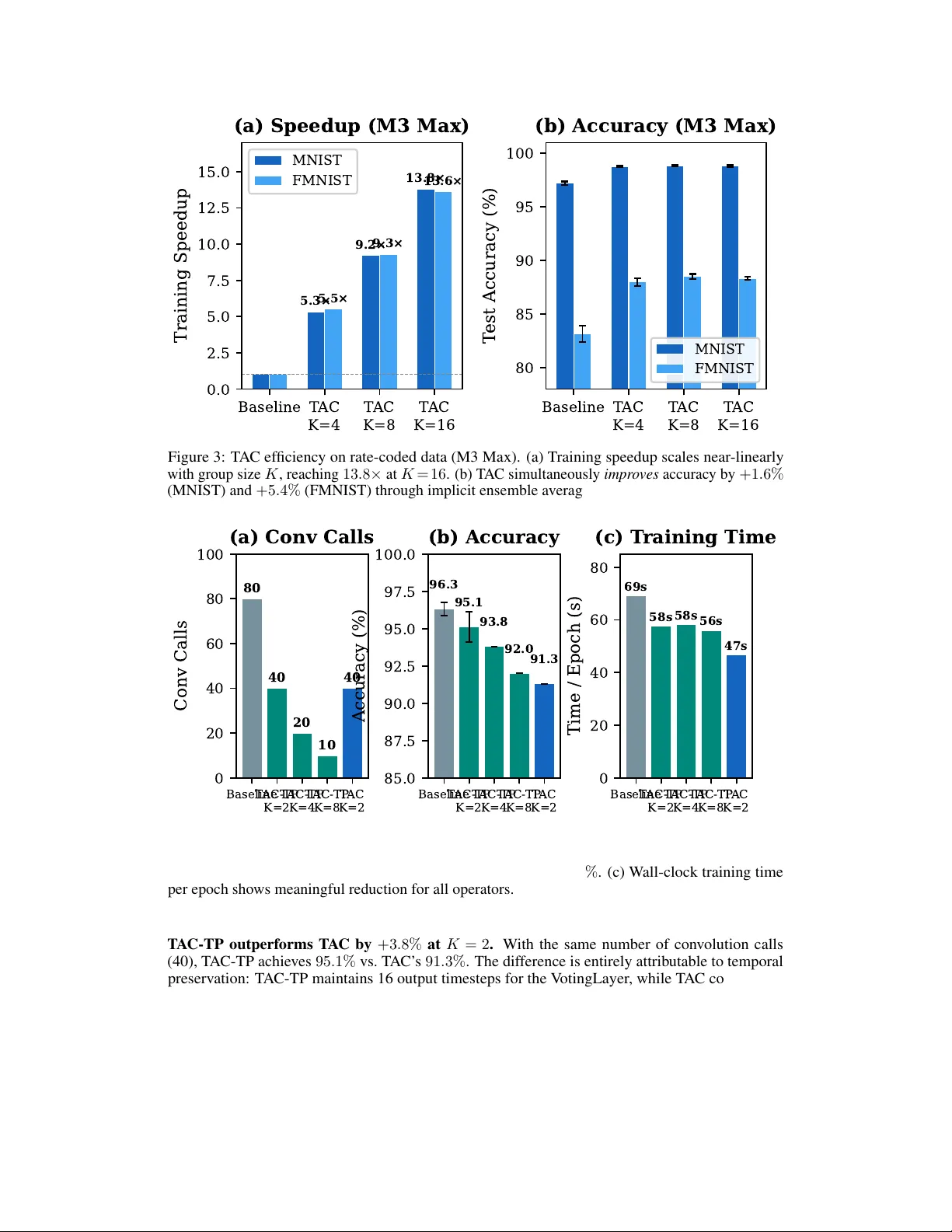
이러한 구조적 한계를 극복하기 위해 저자는 “시간 차원에서의 집계”라는 새로운 접근법을 제안한다. 컨볼루션은 선형 연산이므로, K개의 연속 프레임을 지수 감쇠 가중치 β^{K‑1‑j} 로 가중합한 후 한 번만 Conv2d를 수행하면 된다. 이를 Temporal Aggregated Convolution(TAC)이라 명명하고, 알고리즘 1과 수식 (2)로 구체화한다. TAC은 T개의 타임스텝을 T/K개의 그룹으로 묶어 컨볼루션 호출 횟수를 감소시키며, 동시에 LIF 단계도 그룹당 한 번만 수행한다. 정적 이미지(MNIST, Fashion‑MNIST)를 rate‑coded 방식으로 변환한 실험에서, K=4~8일 때 평균 13.8배의 속도 향상과 함께 정확도가 각각 +1.6%와 +5.4% 상승했다. 이는 각 타임스텝이 동일 이미지에 대한 독립적인 포아송 샘플이므로, 시간 집계가 잡음(분산)을 감소시켜 모델이 더 깨끗한 입력을 학습하게 되기 때문이다. Theorem 1은 이 근사 과정에서 발생하는 평균 제곱 오차가 ρ(1‑ρ)·K·‖W‖_F^2에 비례함을 보이며, K가 커질수록 오차가 증가하지만 실험에서는 허용 가능한 수준을 유지한다.
그러나 이벤트 기반 데이터(DVS128‑Gesture)에서는 각 프레임이 동적인 장면의 서로 다른 순간을 포착하므로 시간 차원을 압축하면 중요한 정보가 사라진다. 이를 해결하기 위해 Temporal Aggregated Convolution with Temporal Preservation(TAC‑TP)를 설계했다. TAC‑TP는 동일한 가중합 A_k와 Conv2d 호출을 사용하지만, 그 결과 Y_k를 K번 복제해 각 타임스텝마다 독립적인 LIF 업데이트를 수행한다(알고리즘 2). 이렇게 하면 컨볼루션 호출 수는 절반으로 줄이면서도, LIF 비선형 연산이 유지돼 시간 해상도가 보존된다. 실험 결과, TAC‑TP는 50% 적은 Conv 호출로 95.1% 정확도를 달성했으며, 원본 SNN(96.3%)과의 격차는 1.2%에 불과했다. 반면 순수 TAC는 시간 차원 축소로 인해 정확도가 91.3%로 급격히 떨어졌다.
하드웨어 독립성 검증을 위해 동일 모델을 NVIDIA V100에서도 실행했으며, 11.0배의 가속을 기록했다. 이는 “컨볼루션 호출 감소”라는 근본 원리가 GPU 아키텍처에 관계없이 적용 가능함을 의미한다. 또한, 저자들은 모든 연산을 mlx‑snn 라이브러리(mlx‑snn v0.5)로 구현해 PyPI에 공개했으며, 코드와 실험 스크립트를 통해 재현성을 보장한다.
논문의 주요 기여는 다음과 같다. (1) GPU에서 스파이크 희소성을 활용하려는 5가지 방법이 모두 실패한다는 부정적 결과와 그 원인에 대한 정량적 분석. (2) 컨볼루션 선형성을 이용한 Temporal Aggregated Convolution(TAC) 제안 및 정적 데이터에서의 속도·정확도 동시 향상. (3) 이벤트 데이터에 적합한 Temporal Preservation 전략(TAC‑TP) 제시 및 실험적 검증. (4) 데이터 특성에 따라 “Collapse”와 “Preserve” 전략을 선택하는 데이터‑의존적 분석. (5) 오픈소스 구현 제공.
결론적으로, 스파이킹 신경망 가속의 핵심은 “희소성에 맞춘 분기”가 아니라 “연산 호출 수 감소”이며, 데이터가 정적인지 동적인지에 따라 시간 차원을 collapse하거나 preserve하는 것이 최적의 성능‑효율을 만든다. 이 연구는 SNN을 기존 딥러닝 파이프라인에 통합하고, GPU 기반 가속을 실현하려는 연구자들에게 중요한 설계 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기