대규모 사전학습과 목표 맞춤 미세조정을 통한 확산 모델 기반 뇌졸중 MRI 가속화
본 연구는 공개된 fastMRI 데이터(≈4000명)를 이용해 확산 확률 생성 모델(DPM)을 사전학습하고, 임상 뇌졸중 MRI에서 사용되는 FLAIR·SWI·MPRAGE·DWI 등 소수의 대상 데이터(20~25명)만으로 미세조정함으로써 2배~4배 가속된 스캔에서도 기존 전통적 병렬 영상법과 동등한 영상 품질을 달성한다는 것을 입증한다.
저자: Yamin Arefeen, Sidharth Kumar, Steven Warach
본 논문은 임상 뇌졸중 MRI에서 제한된 전산화된 데이터만으로도 고품질 가속 MRI 재구성을 가능하게 하는 새로운 학습 전략을 제시한다. 전체 흐름은 크게 네 부분으로 나뉜다.
1. **배경 및 동기**
뇌졸중 환자는 신속한 영상 진단이 필수적이며, CT가 널리 쓰이지만 MRI는 출혈성 뇌졸중 검출과 병변 위치 정확도에서 우수하다. 그러나 MRI는 스캔 시간이 길고 환자 움직임에 민감해 치료 지연 위험이 있다. 기존 딥러닝 기반 가속 MRI는 대규모 전산화된 데이터가 필요하지만, 뇌졸중 전용 데이터는 수집이 어렵다. 따라서 데이터 효율적인 방법이 요구된다.
2. **방법론**
- **사전학습**: fastMRI 공개 데이터(≈4,125명)에서 T1, T2, post‑contrast T1, FLAIR 등 네 가지 대비를 모두 사용해 확산 확률 생성 모델(DPM)을 사전학습한다. 모델은 score‑based diffusion 방식이며, U‑Net 구조에 대비별 원‑핫 인코딩을 결합해 다중 대비 학습을 가능하게 한다. 학습 손실은 EDM(denoising diffusion implicit models) 방식이며, 노이즈 스케줄링과 데이터 증강을 적용한다.
- **미세조정**: 목표 응용(뇌졸중 MRI)에서 FLAIR, SWI, MPRAGE, DWI 등 각 시퀀스별로 20명 정도의 전산화된 데이터를 사용한다. 학습률을 10⁻⁴ → 10⁻⁵ 수준으로 낮추고, 전체 에포크의 2 % 정도만 진행한다. 대비별 임베딩 네트워크도 함께 업데이트한다. 이는 사전학습된 일반 뇌 구조 지식을 유지하면서 목표 대비에 특화된 세부 정보를 학습하도록 돕는다.
- **재구성(Posterior Sampling)**: 사전학습·미세조정된 DPM을 이용해 under‑sampled k‑space 데이터를 posterior sampling으로 복원한다. 논문은 기존 ODE 기반 prior sampling과 diffusion posterior sampling을 결합한 알고리즘을 제시한다. 핵심 하이퍼파라미터는 데이터 일관성 가중치 ζ와 샘플링 스텝 N이며, ζ는 데이터 일관성 오차의 역노름에 비례하도록 설정한다.
3. **실험**
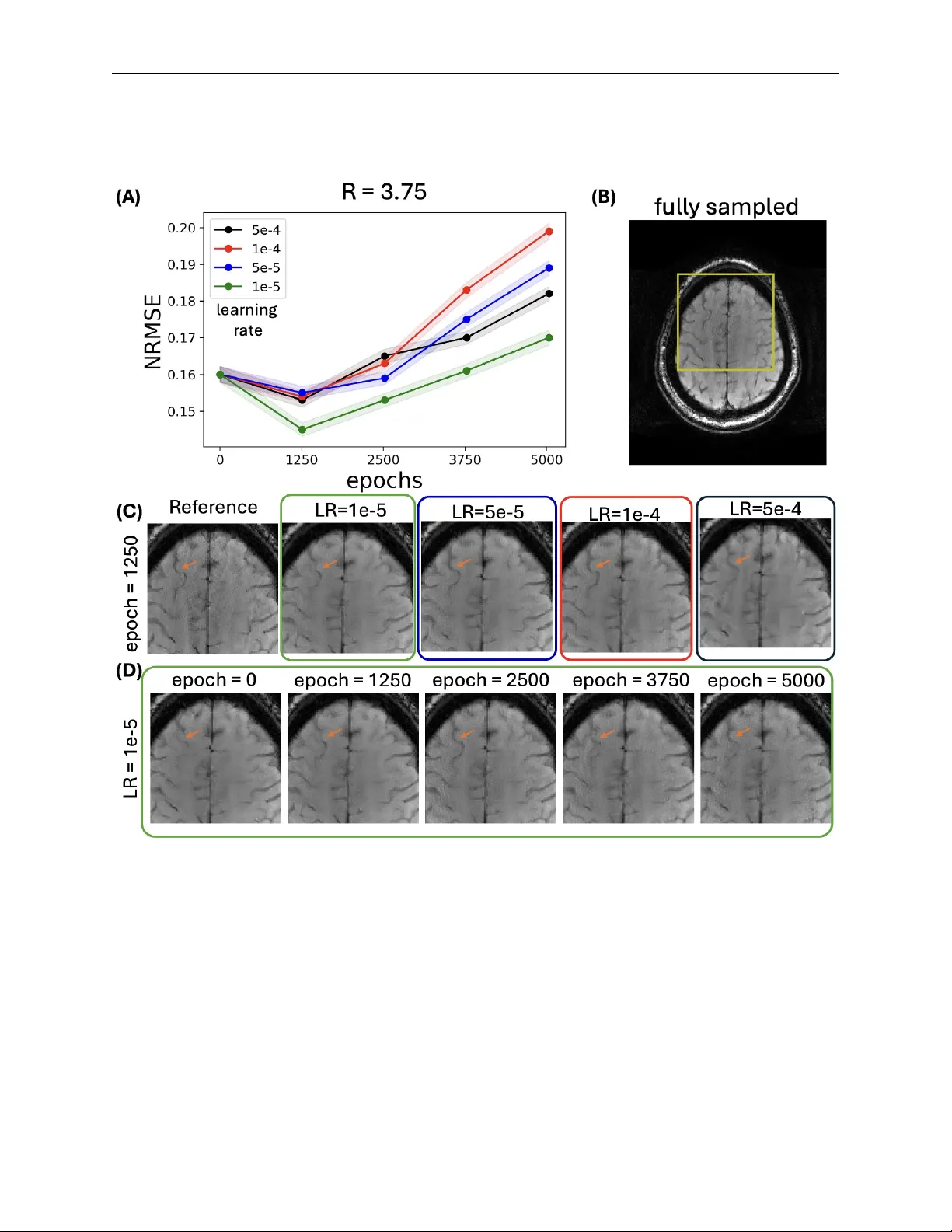
- **fastMRI 제어 실험**: FLAIR 대비를 목표로 20명(≈0.5 % 데이터)만 미세조정했을 때, 전체 344명 FLAIR 데이터로 학습한 모델과 PSNR/SSIM 차이가 미미했다. 학습률·에포크 수를 변형한 실험에서 적절히 낮은 학습률(5×10⁻⁵)과 짧은 미세조정(≈1,250 epoch) 조합이 최적 성능을 보였다.
- **임상 뇌졸중 데이터**: 30명 환자의 표준 프로토콜(T2‑FLAIR, MPRAGE, SWI, DWI)을 수집하고, 20명으로 미세조정 후 나머지 5명에 대해 R≈4 가속(2× 추가 언샘플링)된 데이터를 재구성했다. 모든 시퀀스에서 PSNR·SSIM이 기존 SENSE 재구성과 비슷하거나 약간 우수했다.
- **블라인드 독자 연구**: 추가로 80명 환자를 대상으로 R≈2 표준 재구성과 R≈4 가속 후 DPM 재구성을 비교했다. 두 명의 신경방사선과 전문의가 이미지 품질, 병변 경계, 구조적 선명도를 평가했으며, 통계적으로 비열등하지 않음(non‑inferior) 판정을 받았다.
4. **논의 및 한계**
- **강점**: (①) 사전학습된 DPM이 다양한 대비와 해부학적 변이를 포괄적으로 학습해, 소량의 도메인‑특정 데이터만으로도 높은 재구성 품질을 유지한다. (②) DPM은 acquisition 모델(P, F, S 등)에 독립적이므로, 사전학습 데이터와 목표 데이터가 서로 다른 코일 배열·샘플링 패턴을 가져도 적용 가능하다. (③) 데이터 일관성 항과 사전 점수를 명시적으로 결합해 전통적인 정규화 기반 방법보다 유연한 재구성을 제공한다.
- **제한점**: (①) diffusion 기반 샘플링은 수백 번의 반복 연산이 필요해 추론 시간이 길다. 임상 현장에서 실시간 적용을 위해서는 가속 기법(예: 프루닝, 빠른 디퓨전) 도입이 필요하다. (②) ζ와 N 같은 하이퍼파라미터는 현재 경험적으로 설정하고 있어 자동 최적화가 요구된다. (③) 현재는 단일 3 T Siemens Vida 스캐너에서만 검증했으며, 다기관·다기기 일반화 검증이 필요하다.
5. **결론**
대규모 공개 MRI 데이터로 사전학습한 확산 확률 생성 모델을 목표 응용에 맞게 최소한의 데이터와 낮은 학습률로 미세조정하면, 임상 뇌졸중 MRI에서 2배~4배 가속된 스캔에서도 기존 병렬 영상법과 동등한 영상 품질을 달성한다. 이는 “foundation model” 패러다임을 의료 영상 재구성에 성공적으로 적용한 사례이며, 데이터가 제한된 특수 임상 분야에서 딥러닝 기반 가속 MRI의 실용화를 크게 앞당길 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기