음성 모델이 발견한 음운 벡터 연산
자기지도 학습 음성 모델(S3M)이 음소의 음운 특징을 선형 벡터로 인코딩한다는 증거를 96개 언어에 걸쳐 제시한다.
저자: Kwanghee Choi, Eunjung Yeo, Cheol Jun Cho
**배경 및 동기**
자기지도 학습 음성 모델(S3M)은 대규모 비라벨 음성 데이터만으로 강력한 표현을 학습해 음성 인식·합성·언어 이해 등 다양한 다운스트림 작업에서 뛰어난 성능을 보인다. 기존 연구들은 S3M이 음소 단위의 클러스터링이나 음향적 유사도 반영을 확인했지만, 그 내부 구조가 어떻게 음운학적 원리와 연결되는지는 충분히 탐구되지 않았다.
**연구 질문**
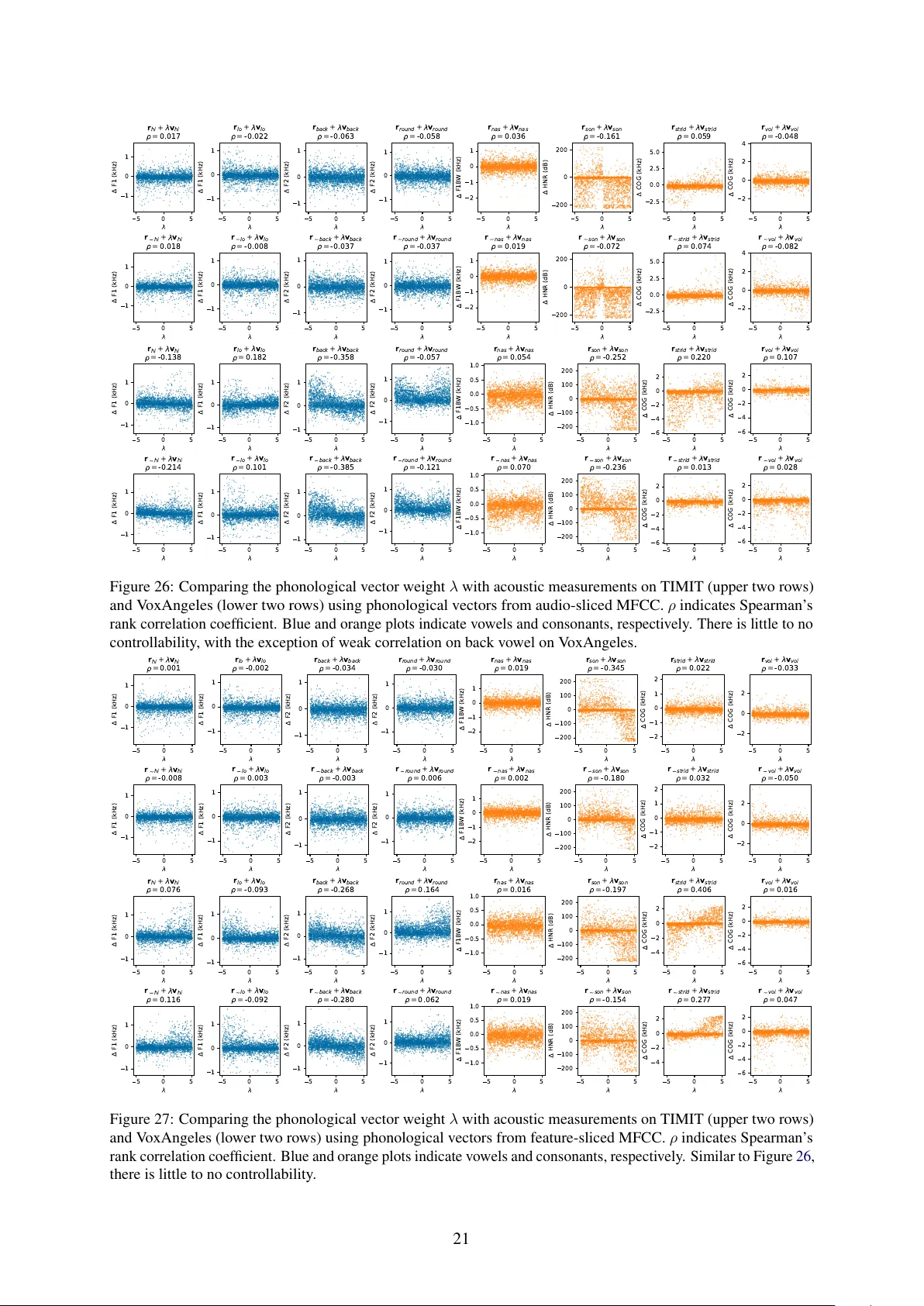
1. S3M의 표현 공간에 음운 특징을 나타내는 선형 방향(벡터)이 존재하는가?
2. 해당 벡터의 스케일 λ이 실제 발화에서 특징의 강도(예: 유성 정도)와 연관되는가?
**데이터**
- **TIMIT**: 영어 630명, 라벨링된 음소와 정확한 경계 제공.
- **VoxAngeles**: 95개 언어·21계통, 468개의 음소 quadruplet을 포함해 영어에 없는 음소까지 평가 가능.
**실험 1 – 방향성 검증**
- PanPhon을 이용해 19개의 음운 특징(예: voicing, POA, nasality 등)을 0/1/‑1 형태로 추출하고, 각 특징에 해당하는 네 음소(p₁,p₂,p₃,p₄)를 “quadruplet”으로 구성.
- 각 quadruplet에 대해 r
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기