뇌신경 어셈블리로 구현하는 딥러닝 대체 음성 세분화와 음소 분류
본 논문은 연속 음성 신호를 이산 스파스 어셈블리로 변환하고, Hebbian 학습과 winner‑take‑all 억제를 이용한 Assembly Calculus(AC) 프레임워크를 통해 경계 검출과 음소·명령어 인식을 수행한다. 멜 스펙트로그램의 확률적 이진화와 MFCC 기반 인구 코딩을 입력 인코딩으로 사용하고, 다계층 리프랙터리와 클래스별 재귀 영역을 설계해 무학습(가중치 고정) 상태에서 전화(F1 = 0.69)와 단어(F1 = 0.61) 경…
저자: Trevor Adelson, Vidhyasaharan Sethu, Ting Dang
본 논문은 현재 음성 처리 분야를 지배하고 있는 딥러닝이 대규모 데이터와 전역적인 역전파 기반 가중치 업데이트에 의존하며, 희소성·구성가능성·지속학습 측면에서 인간 뇌와 차이가 있다는 점을 지적한다. 이러한 한계를 극복하기 위해 Assembly Calculus(AC)라는 스파스 어셈블리 기반 계산 모델을 음성 신호에 적용하는 새로운 프레임워크를 제안한다.
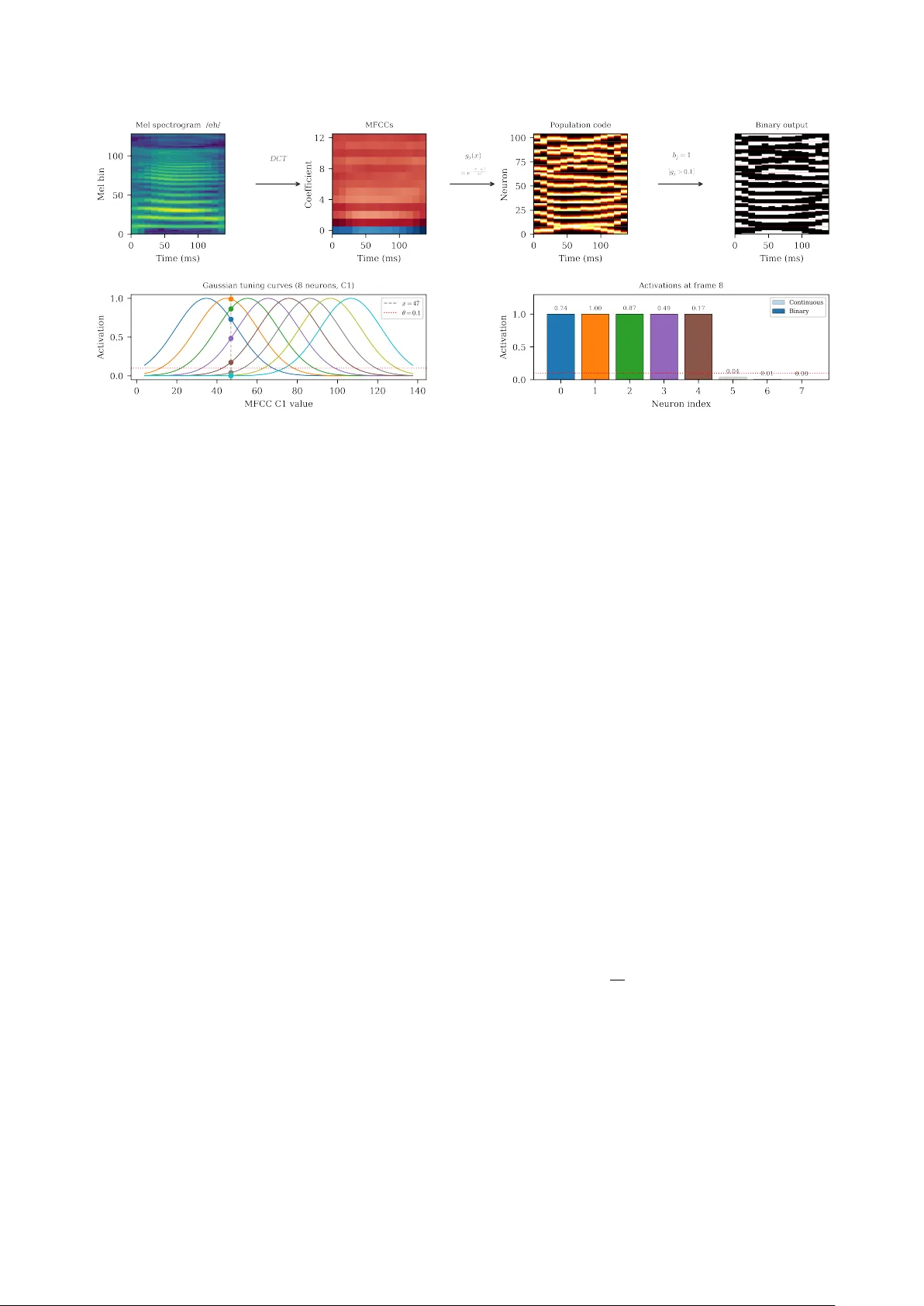
첫 번째 핵심 기여는 연속 음성을 AC가 요구하는 이산 스파스 입력으로 변환하는 ‘신경 인코딩’이다. 저자는 두 가지 인코딩 방식을 설계한다. (i) 확률적 멜 인코딩은 멜 스펙트로그램의 각 bin 값을 Bernoulli 확률로 해석해 이진 스파이크 패턴을 생성한다. 파워‑law 변환(γ ≤ 1)을 통해 동적 범위를 압축하고, 높은 에너지 구간이 더 많이 발화하도록 함으로써 시간적 변화를 그대로 반영한다. (ii) 인구 코딩 MFCC 인코딩은 MFCC 값을 Gaussian 튜닝 커브를 가진 N개의 뉴런 풀에 매핑하고, 일정 임계값을 초과하는 뉴런만을 활성화해 스파스 이진 벡터를 만든다. 이 방식은 화자·피치 변동에 강인하면서도 음소와 같은 안정된 음향 카테고리를 효과적으로 표현한다.
두 번째 기여는 ‘다계층 어셈블리 아키텍처’이다. 경계 검출을 위해서는 가중치가 고정된 리프랙터리 어셈블리 계층을 사용한다. 각 계층은 입력 스파이크를 받아 k‑cap 연산으로 상위 k개의 뉴런을 선택하고, 이전에 활성화된 뉴런에 대해 입력 비례적 부정적 바이어스를 누적시켜 재발을 억제한다. 이러한 리프랙터리 적응은 동일 음소가 다른 위치에 나타날 때 서로 다른 어셈블리 전이를 가능하게 하며, 시간적 변화 신호 c(t)를 추출해 전화와 단어 경계를 탐지한다.
세 번째 기여는 ‘교차 영역 업데이트 및 읽기 메커니즘’이다. 분류 작업을 위해 클래스당 하나씩 할당된 재귀 영역을 도입한다. 각 영역은 동일한 입력을 받지만, 자체적인 재귀 연결과 Hebbian(β > 0) 학습을 통해 클래스 특유의 시공간 궤적을 형성한다. 학습 시 동시 활성화된 전·후 시냅스는 강화되고, 비활성 전시냅스는 ABS 규칙에 따라 약화된다. 입력 시퀀스와 각 영역의 궤적 간 공명 점수 R_c를 계산해 가장 높은 점수를 얻은 영역이 최종 클래스 라벨을 제공한다.
실험에서는 두 가지 핵심 과제, 즉 경계 검출과 세그먼트 분류에 대해 평가한다. 경계 검출에서는 사전 학습 없이도 전화 경계에서 F1 = 0.69, 단어 경계에서 F1 = 0.61을 달성했으며, 이는 기존 무지도 경계 검출 모델과 비교해 경쟁력 있는 성능이다. 분류에서는 전화 인식 정확도 47.5%와 명령어 인식 정확도 45.1%를 기록했는데, 이는 대규모 파라미터와 백프로파게이션을 필요로 하는 최신 딥러닝 모델에 비해 낮지만, 전혀 가중치 업데이트 없이도 동작한다는 점에서 의미가 크다.
논문의 의의는 다음과 같다. (1) AC가 연속, 고차원 음성 신호를 처리할 수 있는 입력 인터페이스를 제공한다. (2) 리프랙터리 어셈블리와 클래스별 재귀 영역을 결합해 시간적 세분화와 카테고리 인식을 동시에 수행한다. (3) 전역 손실 함수 없이도 로컬 Hebbian 학습과 winner‑take‑all 억제로 어셈블리 간의 연관성을 형성하고, 이를 통해 지속적·점진적 학습이 가능함을 실증한다.
향후 연구 방향으로는 어셈블리 규모와 k‑cap 파라미터 최적화, 다중 모달(시각·청각) 통합, 그리고 실제 대규모 음성 코퍼스에서의 지속적 학습 시나리오를 통한 어셈블리 재구성 및 전이 학습을 탐구할 필요가 있다. 이러한 연구가 진행되면 인간 뇌가 수행하는 고효율·저전력·구성가능한 음성 인식 메커니즘을 인공 시스템에 구현하는 데 큰 진전을 이룰 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기