경량화된 음성 인터페이스로 비전‑언어 모델 확장
초록
Speech‑Omni‑Lite는 사전 학습된 비전‑언어(VL) 백본을 고정한 채, 가벼운 두 개의 모듈(음성 프로젝터와 음성 토큰 생성기)만 학습시켜 음성 이해와 생성 능력을 부여한다. 기존 ASR 텍스트‑음성 쌍을 활용해 질문‑텍스트‑답변‑텍스트‑음성(QTATS) 데이터를 자동 생성함으로써 대규모 음성‑QA 데이터 없이도 높은 성능을 달성한다.
상세 분석
본 논문은 대규모 멀티모달 ‘옴니모델’이 요구하는 방대한 데이터와 연산 비용을 크게 낮추는 새로운 패러다임을 제시한다. 핵심 아이디어는 ‘백본 고정 + 경량 어댑터’ 구조이다. 먼저 사전 학습된 이산 음성 토크나이저(HuBERT‑LARGE + FSQ)를 이용해 입력 음성을 12.5 Hz 토큰 스트림으로 변환한다. 이 토큰은 MLP와 몇 개의 LLaMA 디코더 레이어를 거쳐 VL 백본(LLaVA, Qwen2‑VL 등)의 입력 임베딩 공간으로 매핑되는 음성 프로젝터에 전달된다. 백본은 완전히 동결되어 있기 때문에 기존 이미지‑텍스트 이해·추론 능력이 그대로 유지된다.
출력 측면에서는 백본의 마지막 히든 상태를 선형 변환 후 인코더‑디코더 구조의 음성 토큰 생성기가 받아, 다중 토큰 예측(MTP) 메커니즘을 통해 연속적인 음성 토큰 시퀀스를 생성한다. 최종적으로 사전 학습된 디토크나이저가 토큰을 파형으로 복원한다. 이 설계는 ‘Thinker‑Talker’ 방식과 유사하지만, 전체 LLM을 재학습하지 않아도 된다는 점에서 효율성이 크게 향상된다.
데이터 부족 문제를 해결하기 위해 저자들은 기존 ASR 말‑텍스트 쌍을 활용, LLM을 이용해 역질문 생성(reverse question generation)으로 질문 텍스트를 만든다. 이렇게 만든 QTATS(Question‑Text‑Answer‑Text‑Speech) 데이터는 음성 토큰 생성기의 텍스트‑조건부 학습에 사용된다. 즉, 텍스트 입력을 VL 백본에 투입해 얻은 히든 상태와 대응되는 음성 토큰을 학습함으로써, 실제 음성‑QA 상황에서의 조건 불일치를 최소화한다.
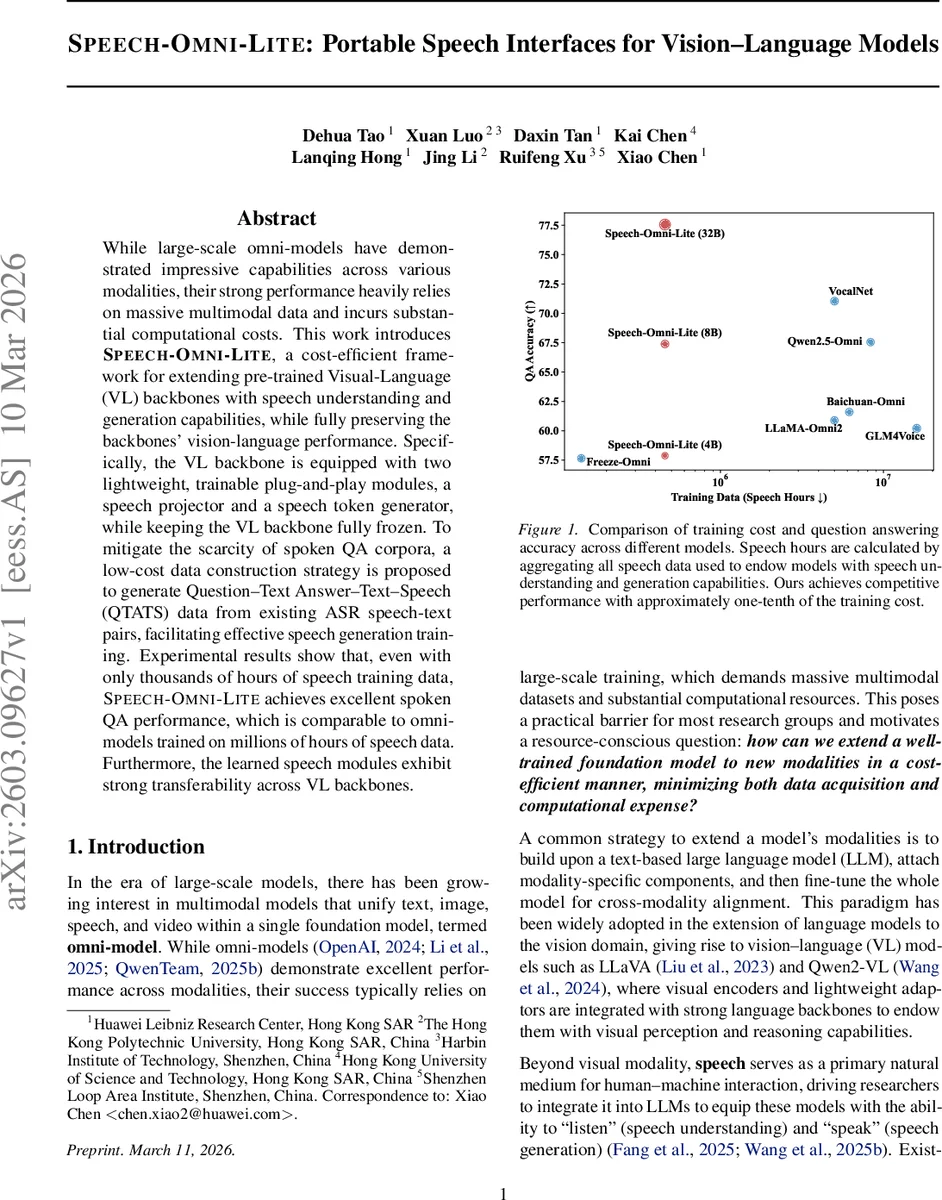
실험 결과는 두드러진데, 수천 시간 수준의 음성 데이터만으로도 수백만 시간 규모의 옴니모델에 필적하는 spoken‑QA 정확도를 기록한다. 또한, 동일한 음성 모듈을 다양한 VL 백본에 그대로 적용했을 때 성능 저하가 거의 없으며, 이는 모듈의 높은 전이성을 입증한다. 학습 비용 대비 성능 비율을 그래프로 제시한 바와 같이, 기존 옴니모델 대비 약 10배 적은 연산·데이터 비용으로 비슷한 QA 정확도를 달성한다.
이러한 설계는 (1) 백본 파라미터를 동결함으로써 기존 비전‑언어 능력 보존, (2) 경량 모듈만 학습해 데이터·연산 효율 극대화, (3) ASR 데이터만으로 저비용 고품질 음성‑QA 학습이 가능하다는 세 가지 핵심 장점을 제공한다. 향후 멀티모달 연구에서 대규모 데이터와 연산 자원이 제한된 상황에서도 음성 모달리티를 손쉽게 추가할 수 있는 실용적인 청사진을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기