YOLO‑NAS‑Bench: YOLO 탐색을 위한 자체 진화 서프라이즈 벤치마크
초록
YOLO‑NAS‑Bench은 YOLO 계열 객체 탐지기의 구조적 탐색을 위한 최초의 서프라이즈 벤치마크이다. 백본·넥스의 채널, 깊이, 연산자 3가지 차원을 포함하는 수백만 규모의 검색 공간을 정의하고, COCO‑mini에서 1,000개의 아키텍처를 무작위·계층·라틴 하이퍼큐브 방식으로 샘플링·완전 학습한다. 24‑차원 특성 벡터를 입력으로 LightGBM 회귀 모델을 훈련하고, 고성능 영역에 집중하도록 자체 진화(Self‑Evolving) 메커니즘을 10라운드 반복해 학습 데이터셋을 1,500개로 확대한다. 최종 앙상블 예측기의 R²는 0.815, Sparse Kendall‑Tau는 0.752에 도달했으며, 이를 피트니스 함수로 사용한 진화적 탐색으로 기존 YOLOv8‑v12 대비 동일 지연 시간에서 더 높은 mAP을 달성한 새로운 모델들을 발견했다.
상세 분석
본 논문은 객체 탐지 NAS의 가장 큰 병목인 ‘고비용 평가’를 근본적으로 완화하기 위해 서프라이즈 기반 벤치마크를 설계하였다. 첫째, 검색 공간은 백본 4단계(P2‑P5)와 넥스 4단계(N1‑N4) 각각에 대해 채널 폭, 블록 깊이, 연산자 유형을 독립적으로 선택하도록 구성하였다. 채널 후보는 단계별로 35가지, 깊이는 14개, 연산자는 C2f, C3k2, C2fCIB, C2PSA 등 최신 YOLOv8‑v12에서 사용된 모듈을 포함한다. 이렇게 하면 전체 조합이 수백만에 달하지만, 핵심 설계 변수만을 변형함으로써 실제 구현 가능성을 유지한다.
둘째, 데이터베이스 구축 단계에서 무작위 샘플링(200), 계층적 샘플링(400), 라틴 하이퍼큐브 샘플링(400)이라는 세 가지 보완적 전략을 동시에 적용해 1,000개의 아키텍처를 골고루 커버한다. 모든 모델은 동일한 COCO‑mini(전체 COCO의 10% 샘플, 클래스·크기 분포 유지)와 통일된 학습 파라미터(120 epoch, 배치 128, Mosaic·MixUp·Copy‑Paste 등) 하에 완전 학습된다.
셋째, 아키텍처를 24‑차원 벡터(채널·깊이 스칼라 + 연산자 원‑핫)로 인코딩하고, Gradient Boosted Decision Tree 기반 LightGBM을 회귀 서프라이즈로 채택했다. LightGBM은 범주형 특성을 자연스럽게 처리하고, 작은 데이터셋에서도 높은 일반화 능력을 보인다. 평가 지표로는 전체 회귀 정확도를 나타내는 R²와, 실질적인 순위 일관성을 강조하는 Sparse Kendall‑Tau(sKT)를 사용하였다. 초기 모델은 R² 0.770, sKT 0.694를 기록했다.
넷째, 고성능 영역에 대한 샘플링 편향을 해소하기 위해 ‘Self‑Evolving Predictor’를 도입했다. 전체 지연 시간 범위를 10개의 버킷으로 균등 분할하고, 각 버킷에서 목표 지연을 무작위로 추출한다. 이후 진화 알고리즘(EA)을 적용해 예측된 mAP를 피트니스, 실제 측정된 지연을 제약조건으로 삼아 상위 5개 아키텍처를 선정한다. 매 라운드마다 50개의 새로운 모델을 학습·통합하고, LightGBM을 재훈련한다. 10라운드 반복 후 데이터셋은 1,500개로 확대되며, 예측기의 R²는 0.815, sKT는 0.752로 향상된다.
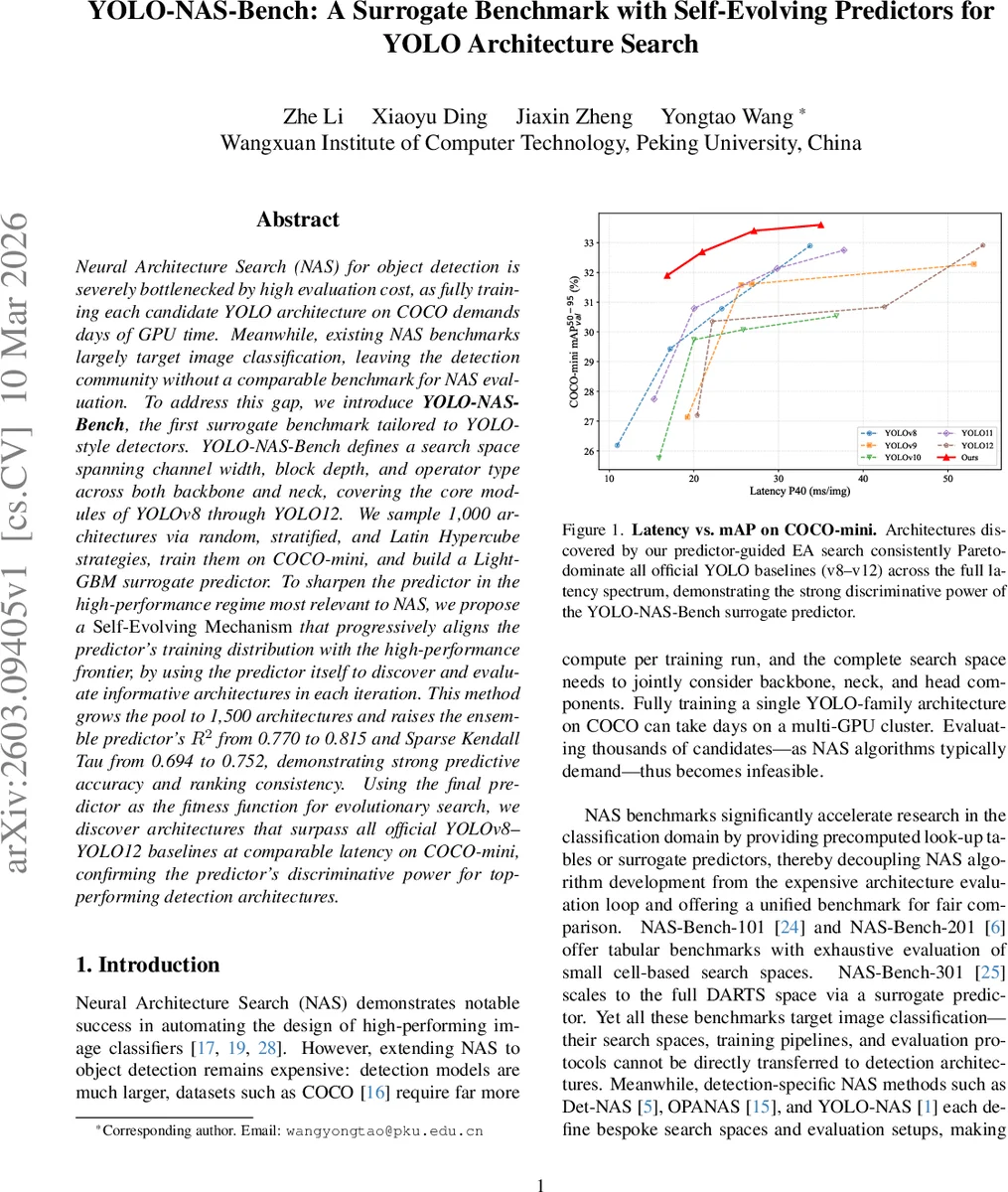
다섯째, 최종 서프라이즈를 직접 피트니스 함수로 활용해 EA 기반 탐색을 수행한 결과, 기존 YOLOv8‑v12 베이스라인을 동일 지연 구간에서 모두 능가하는 모델들을 발견했다. 이는 서프라이즈가 단순 회귀 정확도뿐 아니라 실제 NAS 과정에서의 탐색 효율성을 충분히 제공함을 증명한다.
마지막으로, 본 연구는 (1) YOLO 전용 검색 공간 정의, (2) 고품질 초기 데이터베이스 구축, (3) 고성능 영역에 초점을 맞춘 자체 진화 메커니즘, (4) 실용적인 서프라이즈 기반 NAS 평가 프레임워크라는 네 가지 핵심 기여를 제시한다. 제한점으로는 COCO‑mini 사용으로 인한 절대 성능 차이와, 백본·넥스 외에 헤드 설계가 고정된 점을 들 수 있다. 향후 전체 COCO 데이터셋에서의 재검증 및 헤드 설계까지 포함한 확장 검색 공간 구축이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기