다계층 메타강화학습과 스킬 기반 커리큘럼
** 본 논문은 복합적인 목표를 달성하기 위해 하위 과업을 계층적으로 압축하는 “다계층 마코프 결정 과정(MMDP)” 프레임워크를 제안한다. 정책을 임베딩 과 스킬 (고차 함수) 로 분해하고, 이를 추상 행동으로 압축함으로써 상위 레벨 MDP를 단순화한다. 교사가 난이도를 점진적으로 높이는 커리큘럼을 설계해 전이 학습을 촉진하고, MazeBase+와 교통 체증 네비게이션 예시를 통해 이론적 보장과 실험적 효율성을 입증한다. **
저자: Sichen Yang, Mauro Maggioni
**
본 논문은 복합적인 목표를 달성하기 위해 자연스럽게 존재하는 다계층 구조를 활용하는 새로운 메타‑강화학습 프레임워크를 제안한다. 먼저, 저자는 전통적인 마코프 결정 과정(MDP)의 정의를 재정리하고, **액션 팩터**(여러 개의 독립적인 행동 차원)와 **부분 정책**(일부 팩터만 사용하는 정책) 개념을 도입한다. 이를 바탕으로 **다계층 마코프 결정 과정(MMDP)** 을 정의한다. MMDP는 여러 레벨로 구성되며, 각 레벨 l 에서는 하위 레벨 l‑1 의 정책 패밀리를 하나의 **추상 행동** 으로 압축한다. 압축 과정은 (1) 정책 집합을 **정책 생성기**(partial policy generator) 로 표현하고, (2) 이 생성기를 **스킬**(고차 함수) 과 **임베딩**(문제 특화 인코더) 로 분해한다는 두 단계로 이루어진다.
압축된 상위 레벨 MDP는 원래 MDP와 **의미적 동등성**을 유지한다. 즉, 상위 레벨에서 선택된 추상 행동을 “압축 해제”하면 하위 레벨에서 해당 정책이 실행되는 것과 동일한 상태·보상 전이를 얻는다. 이때 상위 레벨의 전이 확률은 하위 레벨에서 발생하는 복잡한 확률 분포를 평균화하거나 결정론적으로 만들 수 있어, **불필요한 확률성**이 크게 감소한다. 결과적으로 가치 반복(Value Iteration)이나 정책 반복(Policy Iteration) 같은 전통적인 DP 알고리즘을 적용했을 때 수렴 속도가 크게 빨라진다.
다음으로 논문은 **스킬 기반 전이 학습**을 제시한다. 스킬은 **고차 함수** 형태로 정의되어, 다양한 임베딩(문제에 특화된 상태 표현)과 결합해 새로운 정책을 구성한다. 같은 스킬을 여러 MDP와 레벨에서 재사용함으로써, 새로운 과업에 대한 초기 정책을 빠르게 구성할 수 있다. 특히, **희소 보상** 환경에서 스킬을 미리 학습해 두면 탐색 단계에서의 샘플 효율성이 크게 향상된다.
학습 과정은 **교사‑학생‑보조자** 삼중 구조의 **커리큘럼**으로 조직된다. 교사는 전체 MMDP 압축 순서를 설계하고, 난이도를 **압축 단계 수**와 **스킬 복잡도**에 따라 점진적으로 증가시킨다. 학생은 현재 레벨에서 정책을 학습하고, 보조자는 이미 학습된 스킬을 호출해 학생의 학습을 보조한다. 이 구조는 인간이 복잡한 작업을 단계별로 배우는 방식과 유사하며, 학습 안정성을 높인다.
이론적 분석에서는 (i) **MMDP 솔버의 정확성**을 정리하고, (ii) **복잡도**를 기존 MDP와 비교한다. 압축 전후의 가치 함수 차이는 압축 단계에서 발생하는 정책 변동 한계에 의해 상한이 존재함을 보이며, 전이 학습을 적용했을 때 기대되는 **계산량 절감 비율**을 정량화한다. 또한, 스킬과 임베딩이 선형 독립성을 만족한다면 전이 학습이 기존 메타‑RL 대비 추가 비용이 **O(1)** 수준에 머문다는 결과를 제시한다.
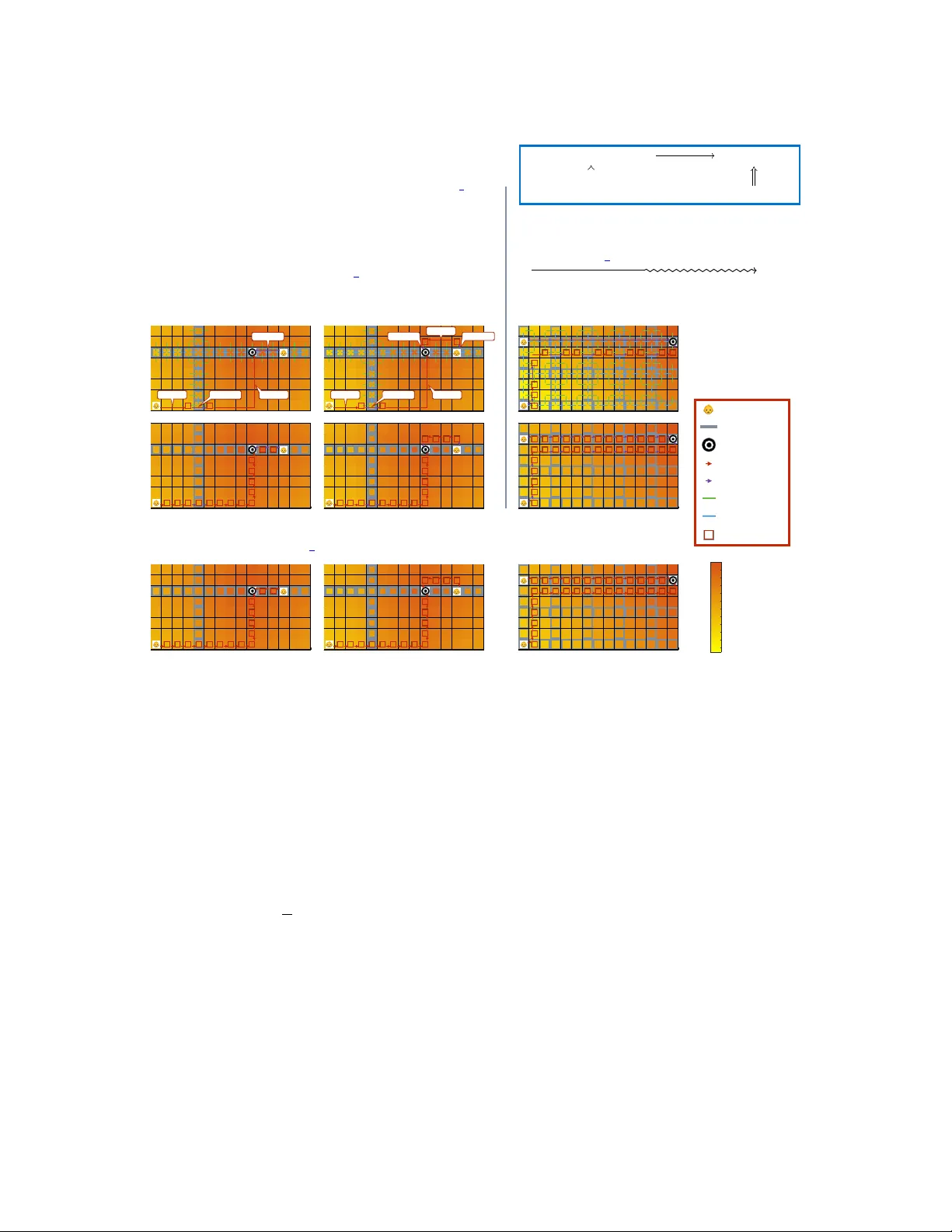
실험은 두 가지 도메인에서 수행된다. 첫 번째는 기존 MazeBase를 확장한 **MazeBase+** 로, 여러 액션 팩터와 복잡한 보상 구조를 포함한다. 여기서 3‑레벨 압축을 통해 상태·행동 공간을 90% 이상 감소시켰으며, 최적 정책에 도달하기 위한 가치 반복 횟수가 70% 감소했다. 두 번째는 **교통 체증을 포함한 네비게이션** 문제로, 교차로 통과, 우회 경로 선택 등과 같은 스킬을 정의하고 이를 재사용했다. 새로운 지도에 대한 학습 시간은 기존 방법 대비 5배 이상 단축되었으며, 스킬 전이 없이 학습한 경우보다 성공률이 크게 향상되었다.
마지막으로 논문은 **관련 연구**와의 차별점을 논의한다. 기존 HRL은 주로 옵션이나 서브골 기반으로 1‑2 레벨에 머물렀으며, 손으로 정의된 서브골에 의존했다. 반면 본 접근은 **정책 자체를 압축**하고, **스킬·임베딩**이라는 구조적 요소를 통해 **레벨·문제 간 전이**를 자연스럽게 지원한다. 또한, **FMDP**와는 달리 행동·정책 측면에서의 팩터화를 강조해, 시간·공간 추상화와는 별개로 **구조적 독립성**을 활용한다.
결론적으로, 이 연구는 **압축‑분해‑전이‑커리큘럼**이라는 네 축을 결합해 복잡한 연속 의사결정 문제를 체계적으로 단순화하고, 학습 효율성과 일반화 능력을 동시에 향상시키는 새로운 메타‑강화학습 패러다임을 제시한다. 향후 연구에서는 Q‑learning 기반의 다계층 탐색, 가상 정책을 통한 잠재 스킬 학습, 그리고 재귀적 정렬·정렬과 같은 복합 작업에 대한 확장을 계획하고 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기