기업용 근거 추론 벤치마크 OfficeQA Pro: 대규모 문서 기반 AI 평가
초록
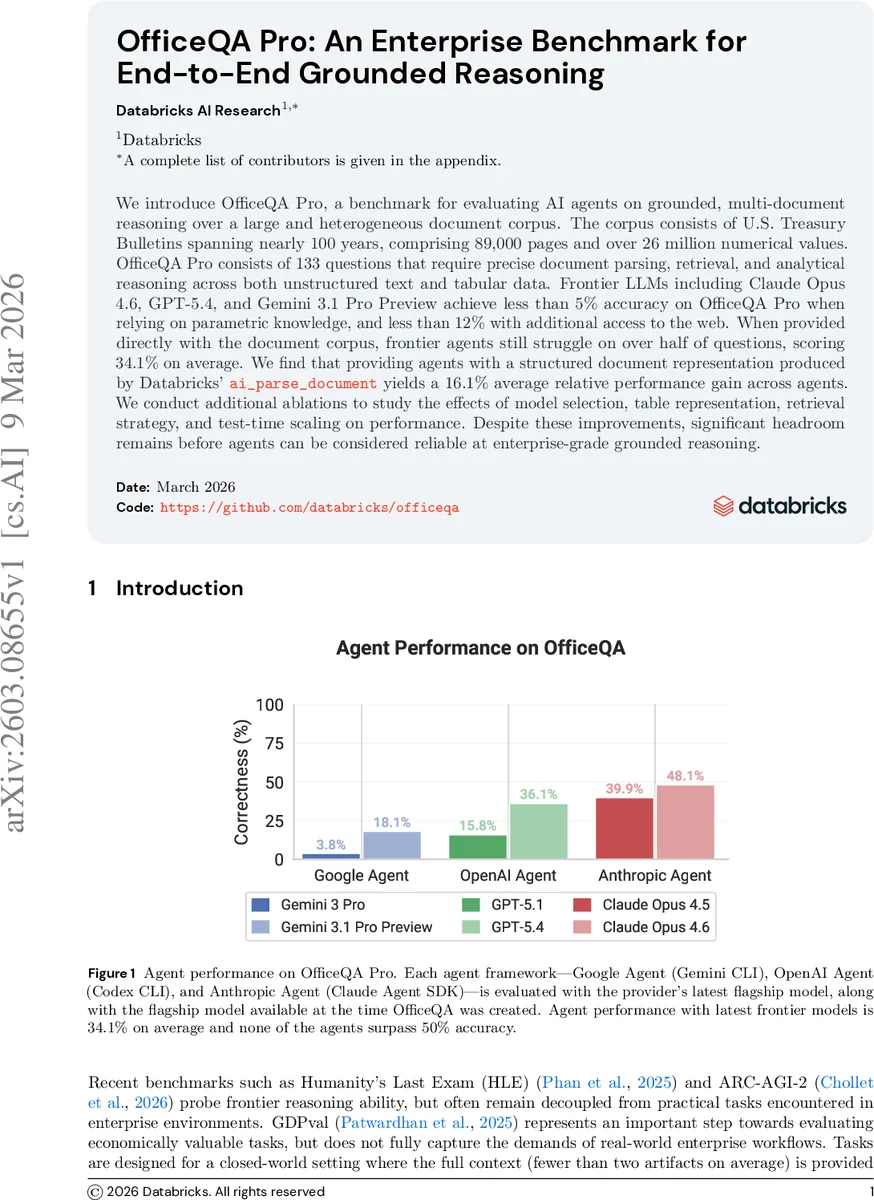
OfficeQA Pro는 100년 분량의 미국 재무청 보고서(총 89 000페이지, 2,600만 개 숫자)를 활용해, 다중 문서·표 형식 데이터를 정확히 파싱·검색·분석해야 하는 133개의 질문으로 구성된 기업용 근거 추론 벤치마크이다. 최신 LLM(Claude Opus 4.6, GPT‑5.4, Gemini 3.1 Pro)조차 파라미터 지식만으로는 5% 이하, 웹 검색까지 허용해도 12% 이하의 정확도에 머물며, 전체 문서를 직접 제공해도 평균 34.1%에 불과하다. Databricks의 ai_parse_document로 구조화된 문서 표현을 제공하면 평균 상대 성능이 16.1% 상승한다. 모델 선택, 표 표현, 검색 전략, 테스트‑타임 스케일링 등 다양한 변수에 대한 추가 실험에서도 여전히 큰 개선 여지가 남아 있다.
상세 분석
본 논문은 기업 환경에서 흔히 마주치는 “대규모·이질적·다중 형식 문서”를 대상으로 한 근거 추론 과제를 정의하고, 이를 정량화할 수 있는 벤치마크인 OfficeQA Pro를 제시한다. 데이터셋은 1939년부터 2025년까지 발행된 미국 재무청 Bulletin을 디지털화·OCR 처리한 뒤, 89 000페이지에 걸친 텍스트와 복잡한 다중 레벨 표를 포함한다. 표는 단위 변환, 주석, 연도별 수정 등 고도의 전처리 없이도 원본 그대로 제공되어, 모델이 실제 기업 문서 파싱 파이프라인을 거쳐야 함을 강제한다.
질문 설계는 4가지 핵심 요구사항을 만족한다. 첫째, 다중 문서·다중 페이지에 걸친 정보를 종합해야 하며, 11%는 3개 이상 Bulletin을, 22%는 외부 웹 검색(예: CPI)까지 필요로 한다. 둘째, 3%는 차트·그래프 등 시각적 요소에 대한 해석을 요구한다. 셋째, 62%는 단순 산술을 넘어 회귀 분석·시계열 추정 등 고차원 수치 연산을 포함한다. 넷째, 모든 질문은 단일 명확한 정답을 갖도록 설계돼 자동 채점이 가능하도록 했다.
벤치마크 구축 과정은 “질문·정답 생성 → 다중 검증 → AI‑에이전트 충돌 검증 → 최종 확정”의 2단계 품질 관리 파이프라인을 사용한다. 초기 질문은 인간 어노테이터가 PDF를 직접 검토하며 작성하고, 독립적인 검증자에게 재답변을 요구해 정답의 재현성을 확인한다. 이후 AI 에이전트(Claude, GPT, Gemini 기반)에게 동일 질문을 제시해 상이한 답변이 도출되면, 인간 리뷰어가 원인(모델 오류, 질문 모호성, 정답 오류)을 분석하고 필요 시 질문을 수정하거나 정답을 교정한다. 이러한 반복 검증은 인간 주관에 의존하지 않는 객관적 정답 세트를 확보하는 데 핵심적이다.
성능 평가에서는 0.0% 절대 상대 오차 허용(정확히 일치) 기준을 기본으로 하며, 0.1%, 1.0%, 5.0% 등 점진적 허용치를 추가해 모델의 근사 능력을 다층적으로 측정한다. 결과는 놀라울 정도로 저조하다. 파라미터 지식만 활용한 Prompt‑Only 설정에서는 모든 모델이 3% 이하의 정확도를 기록했고, 5% 허용치에서는 17~24% 수준에 머물렀다. 웹 검색을 허용해도 12% 미만, 전체 문서를 직접 제공해도 평균 34.1%에 불과했다.
특히, Databricks의 ai_parse_document를 통해 PDF를 구조화된 텍스트·표 형태로 변환해 제공하면 평균 상대 성능이 16.1% 상승한다는 점은, 문서 파싱 단계가 전체 파이프라인에서 병목임을 시사한다. 추가 실험에서는 (1) 모델 아키텍처(Claude Opus 4.6 vs GPT‑5.4 vs Gemini 3.1) 간 차이, (2) 표 표현 방식(플랫 텍스트 vs JSON‑형식 테이블) 차이, (3) 검색 전략(BM25 vs dense retriever) 차이, (4) 테스트‑타임 토큰 수·코드 실행 횟수 확대가 성능에 미치는 영향을 분석했으며, 어느 경우에도 50%를 넘는 정확도에 도달하지 못했다.
논문은 현재 LLM이 “전문 지식·수치 연산·복합 표 해석”을 요구하는 실제 기업 업무에 적용되기엔 아직 큰 격차가 있음을 강조한다. 향후 연구 과제로는 (① 고성능 OCR·레이아웃 인식 결합, ② 도메인‑특화 툴(예: 수치 계산 엔진)과의 원활한 연동, ③ 장기 메모리·외부 지식 베이스 활용, ④ 인간‑AI 협업 인터페이스 설계) 등을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기