PureCC: 순수 학습 기반 텍스트‑투‑이미지 개념 맞춤화
초록
PureCC는 기존 맞춤화 기법이 원본 모델의 행동과 품질을 손상시키는 문제를 해결하기 위해, 목표 개념의 암시적 가이던스와 원본 조건 예측을 분리한 새로운 학습 목표를 제시한다. 고정된 표현 추출기와 학습 가능한 흐름 모델을 결합한 이중‑브랜치 파이프라인을 통해 개념만을 순수하게 학습하고, 적응형 가이드 스케일 λ*를 도입해 맞춤화 정확도와 원본 보존 사이의 균형을 동적으로 조절한다. 실험 결과 DreamBooth와 LoRA 대비 KL‑다이버전스와 프롬프트 준수도에서 현저히 우수함을 보인다.
상세 분석
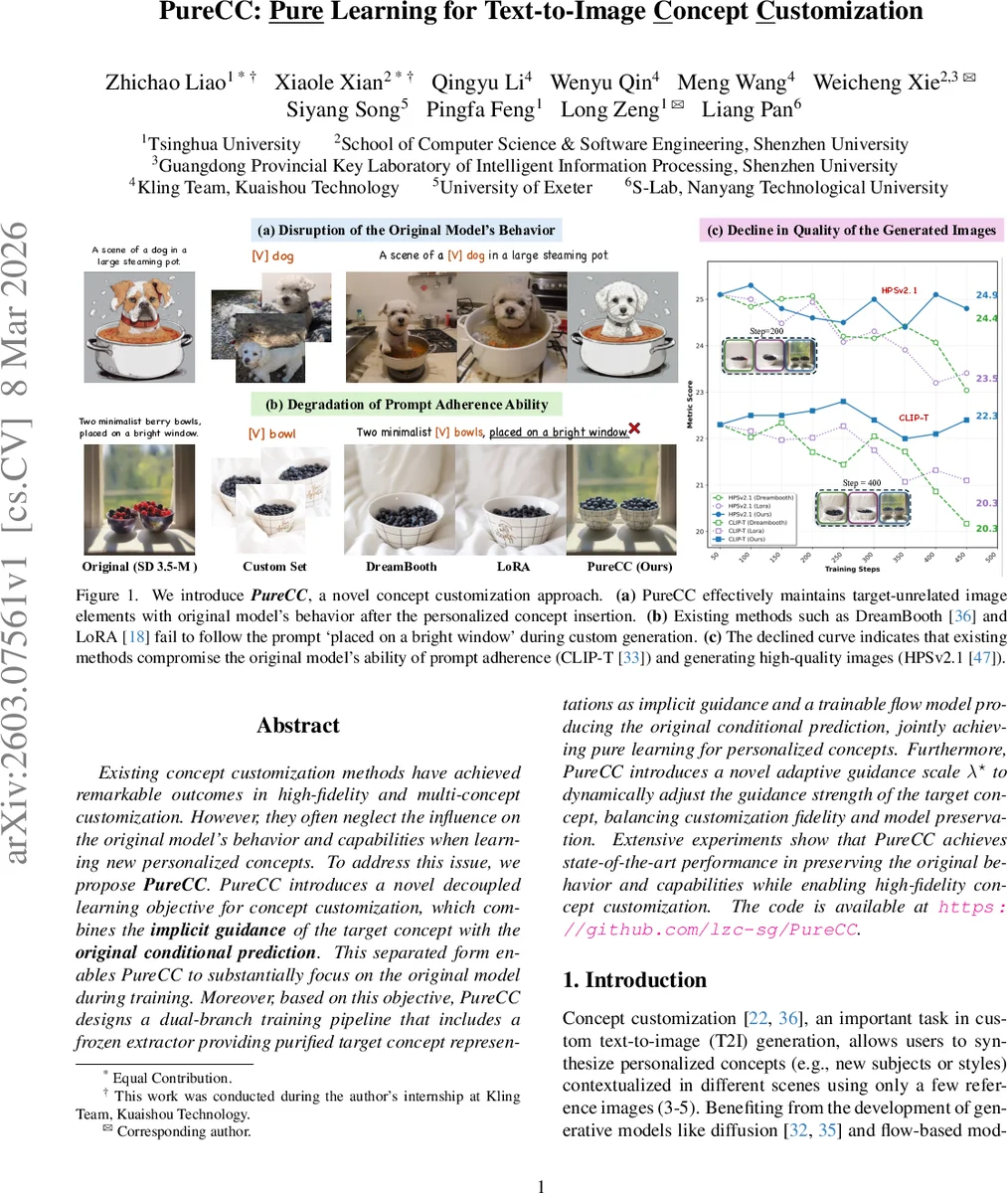
PureCC는 텍스트‑투‑이미지(T2I) 모델의 ‘개념 맞춤화(Concept Customization)’ 작업을 재정의한다. 기존 DreamBooth·LoRA 계열은 전체 파라미터를 미세조정하거나 저‑랭크 서브스페이스를 삽입해 목표 개념을 학습하지만, 제한된 레퍼런스 이미지로 인해 원본 모델이 학습 데이터에 과도하게 적응해 배경·스타일·조명 등 비목표 요소가 변형되는 ‘원본 행동 파괴’를 초래한다. PureCC는 이를 방지하기 위해 두 가지 핵심 설계를 도입한다. 첫째, 목표 개념을 암시적 가이던스로 활용하면서도 원본 조건 예측을 별도로 유지하는 ‘분리형 학습 목표’를 정의한다. 수식적으로는 목표 속도장(vₜ) = v_originalₜ + λ·v_targetₜ 형태이며, 여기서 v_originalₜ는 원본 모델이 제공하는 무조건 예측, v_targetₜ는 고정된 표현 추출기가 생성하는 목표 개념의 편향이다. 이 구조는 학습 중 원본 모델에 대한 손실을 최소화하면서 목표 개념만을 강화한다는 이론적 근거를 제공한다. 둘째, 이중‑브랜치 파이프라인을 구현한다. (1) ‘표현 추출기’는 사전 훈련된 흐름 기반 모델에 LoRA와 레이어‑와이즈 튜너블 개념 임베딩을 적용해 목표 개념을 정교하게 캡처하고, 학습 단계에서는 완전히 고정한다. (2) ‘학습 가능한 흐름 모델’은 별도 사전 훈련된 흐름 모델을 초기화해 원본 조건 예측을 담당한다. 두 브랜치의 출력 차이를 λ에 의해 가중합함으로써, 목표 개념의 가이드 강도를 동적으로 조절한다. λ는 두 브랜치 간 표현 정렬 정도(예: 코사인 유사도)로 정의되어, 목표 개념이 충분히 학습되면 가이던스 강도를 낮추고, 아직 부족하면 강도를 높인다. 이러한 적응형 스케일링은 맞춤화 정확도와 원본 보존 사이의 트레이드오프를 자동으로 최적화한다. 실험에서는 KL‑다이버전스, CLIP‑T(프롬프트 준수), HPSv2.1(이미지 품질) 세 가지 지표를 사용해 DreamBooth·LoRA 대비 5‑10배 낮은 분포 이동과 거의 동일한 프롬프트 충실도를 기록한다. 특히 ‘
댓글 및 학술 토론
Loading comments...
의견 남기기