효율적인 데이터셋 압축을 위한 사후 양자화
본 논문은 기존 데이터셋 축소(DC) 기법에 사후 양자화(PTQ)를 도입해 2비트 수준까지 저장 용량을 크게 줄이면서도 학습 성능을 유지하는 방법을 제안한다. 전역 양자화가 초저비트에서 성능 저하를 일으키는 문제를 해결하기 위해 패치 기반 양자화와 유사 패치 군집화를 결합하고, 양자화 손실을 보정하는 정제 모듈을 추가한다. 다양한 DC 방법에 플러그인 형태로 적용 가능하며, CIFAR‑10/100, Tiny ImageNet, ImageNet‑s…
저자: Linh-Tam Tran, Sung-Ho Bae
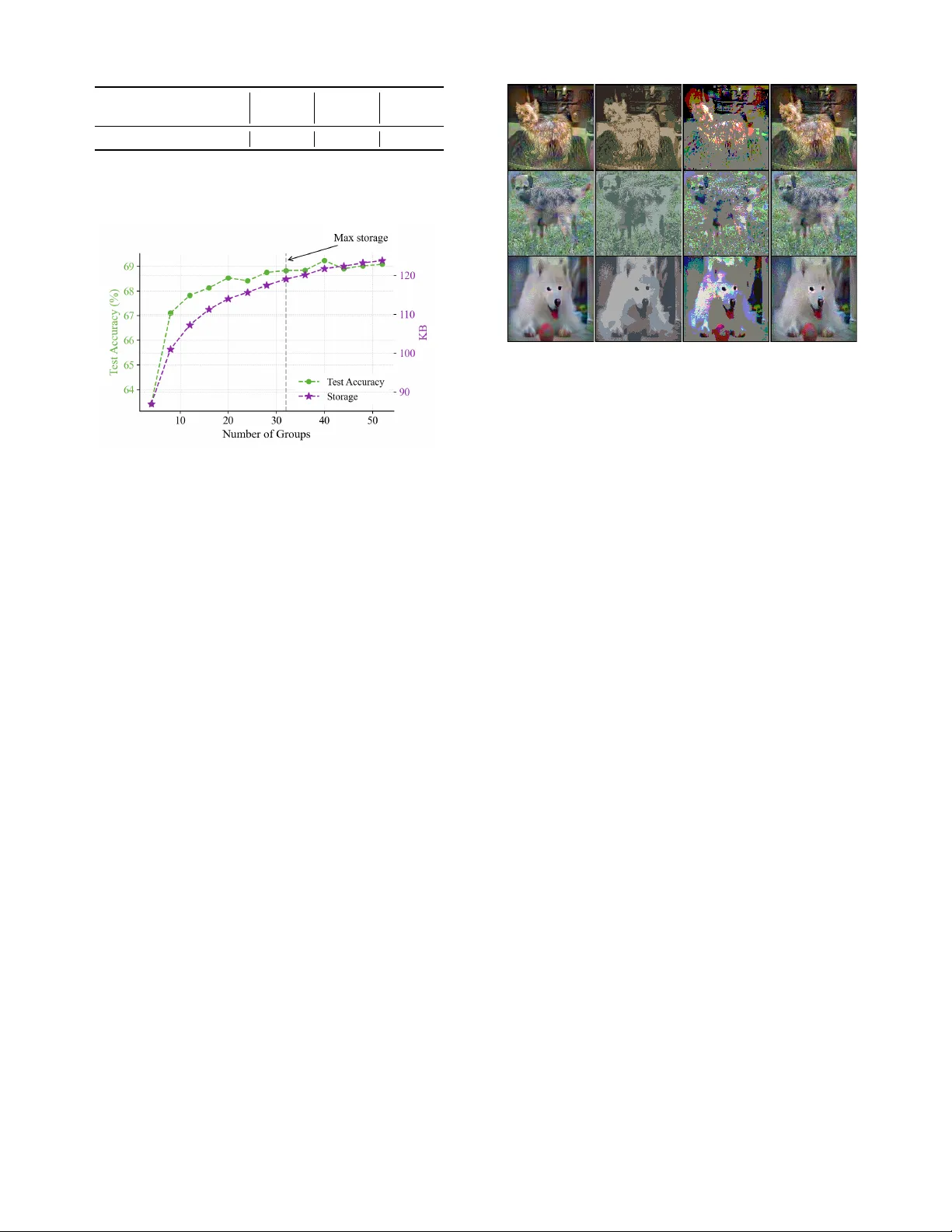
본 논문은 데이터셋 축소(Dataset Condensation, DC) 분야에서 저장 효율성을 획기적으로 개선하기 위해 사후 양자화(Post‑Training Quantization, PTQ)를 도입한다. 기존 DC 기법은 합성 이미지를 32‑bit 풀 해상도로 저장하기 때문에 대규모 모델 학습에 필요한 저장 공간을 크게 차지한다. 파라미터화 기반 DC(PDC)는 latent space나 neural field 등을 이용해 압축을 시도하지만, 복잡한 디코더가 필요하고 연산 비용이 증가한다. 이러한 문제점을 해결하고자 저자는 “패치 기반 비대칭 양자화(Patch‑based Asymmetric Quantization, PAQ)”, “양자화‑인식 패치 군집화(Quantization‑aware Grouping, GAQ)”, 그리고 “정제 모듈(Refinement Module)”이라는 세 가지 핵심 구성요소를 제안한다.
1. **패치 기반 비대칭 양자화(PAQ)**
- 이미지를 겹치지 않는 작은 패치(예: 4×4, 8×8)로 분할하고, 각 패치마다 독립적인 스케일(α)과 제로‑포인트(z)를 계산한다. 이는 비대칭 양자화의 기본 식 α = (max−min)/(Qmax−Qmin), z = round(Qmin−min/α) 를 패치 단위에 적용한다는 의미이다. 전역 양자화가 저비트(특히 2‑bit)에서 색상·텍스처 정보를 크게 손실시키는 반면, PAQ는 각 패치의 통계적 특성을 반영해 양자화 오차를 최소화한다. 실험에서 2‑bit PAQ 적용 시 원본 32‑bit 대비 MSE가 40% 이상 감소했으며, 특징 맵의 코사인 유사도도 크게 향상되었다.
2. **양자화‑인식 패치 군집화(GAQ)**
- 패치마다 별도 파라미터를 저장하면 파라미터 오버헤드가 급증한다. 이를 해결하기 위해 각 패치의 양자화 파라미터(α, z)를 2‑차원 벡터로 보고 k‑means 클러스터링을 수행한다. 동일 클러스터에 속한 패치는 평균 파라미터를 공유하게 되며, 클러스터 수 G는 저장 용량과 양자화 품질 사이의 트레이드‑오프를 조절한다. 클러스터링 후에는 각 클러스터에 포함된 모든 패치를 하나의 텐서로 연결(concat)하고, 이 텐서에 대해 재정규화(calibration)를 수행해 최적의 스케일·제로‑포인트를 다시 계산한다. 이 과정은 파라미터 저장량을 70~80% 절감하면서도 양자화 오차를 최소화한다.
3. **정제 모듈(Refinement)**
- 양자화·역양자화 과정에서 발생하는 미세한 특징 왜곡을 보정하기 위해 합성 이미지를 미세하게 업데이트한다. 구체적으로, 양자화된 이미지와 원본 이미지의 특징 맵을 동일한 사전 학습된 네트워크 f(·)에 입력하고, L2 손실 ‖f(x)−f(Q⁻¹(Q(x)))‖₂² 를 최소화하도록 역전파한다. 이 단계는 별도의 추가 학습 없이도 양자화 전후의 분포 차이를 줄여, 최종 학습 시 모델이 양자화된 데이터를 보다 효과적으로 활용하도록 만든다.
**실험 설정 및 결과**
- 평가 데이터셋: CIFAR‑10, CIFAR‑100, Tiny ImageNet, ImageNet‑subset.
- 비교 대상: 기존 DC 방법(DMA, DSA, DATM 등) 및 파라미터화 기반 PDC(IPC, HaBa, SPEED, FREd, Spectral 등).
- 압축 비율: 2‑bit 저장(전역 양자화 대비 16배 압축).
- 주요 결과:
* IPC=1 상황에서 DSA는 28.8%→52.1%, DM은 26.0%→54.1% 로 정확도가 거의 두 배에 달함.
* IPC=10, 50에서도 기존 방법 대비 평균 12~15%p 상승을 기록하였다.
* 파라미터화 기반 PDC와 비교했을 때, 연산 오버헤드가 거의 없으며(디코더 필요 없음) 저장 효율성은 2‑bit 수준으로 최고 수준을 달성했다.
* 정량적 평가 외에도 시각적 비교에서 PAQ가 2‑bit에서도 원본 이미지와 거의 구분이 어려운 품질을 유지함을 확인하였다.
**한계 및 향후 연구**
- 현재 패치 크기와 클러스터 수는 고정값으로 설정했으며, 데이터셋 특성에 따라 자동 튜닝이 필요할 수 있다.
- 라벨(특히 소프트 라벨)이나 메타데이터에 대한 양자화 효과는 아직 조사되지 않았다.
- 온‑디바이스 학습 시 양자화 파라미터 로드 비용을 최소화하는 하드웨어 친화적 구현이 필요하다.
- 더 낮은 비트(1‑bit 혹은 ternary)에서도 성능을 유지할 수 있는 양자화 스킴 개발이 향후 과제로 남는다.
결론적으로, 본 논문은 데이터셋 축소와 비트‑레벨 압축을 결합함으로써 저장 효율성을 극대화하고, 저비트 환경에서도 높은 학습 성능을 유지할 수 있음을 실험적으로 입증하였다. 제안된 패치 기반 양자화와 군집화‑정제 파이프라인은 기존 DC 방법에 플러그인 형태로 쉽게 적용 가능하며, 저장 제한이 큰 모바일·엣지 디바이스에서의 데이터셋 배포 및 학습에 큰 잠재력을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기