엔터프라이즈용 트릴리언 파라미터 MoE LLM “Yuan3.0 Ultra”와 사전학습 단계 전문가 프루닝 혁신
초록
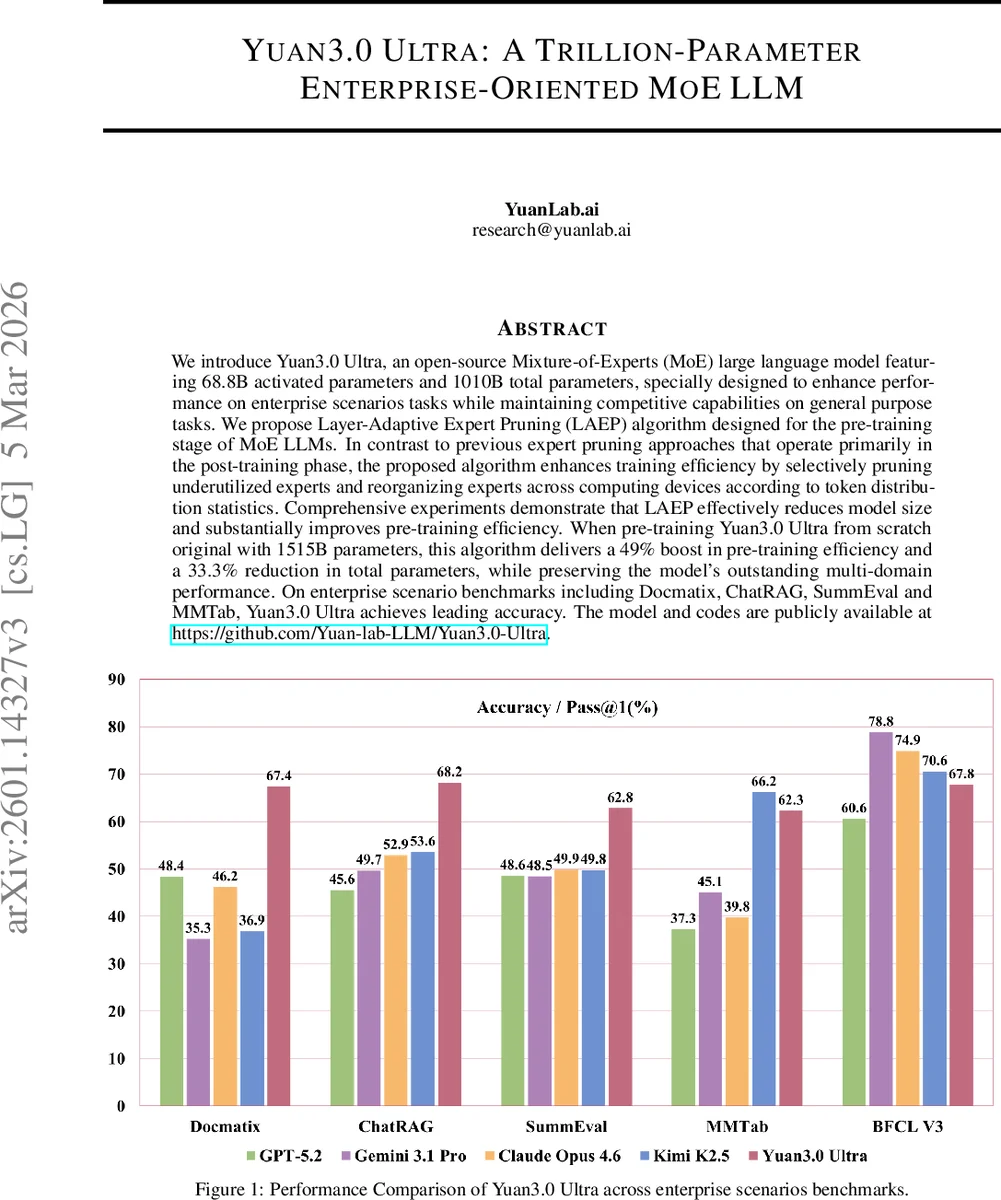
Yuan3.0 Ultra는 68.8 B 활성 파라미터와 1 010 B 전체 파라미터를 갖는 오픈소스 Mixture‑of‑Experts(모에) 대형 언어 모델이다. 논문은 사전학습 단계에서 전문가 로드 통계를 활용해 저활용 전문가를 선택적으로 제거하고, 남은 전문가를 디바이스 간 재배치하는 Layer‑Adaptive Expert Pruning(LAEP) 알고리즘을 제안한다. LAEP 적용 시 전체 파라미터가 33.3 % 감소하고, 사전학습 효율이 49 % 향상되며, 기업용 벤치마크(Docmatix, ChatRAG, SummEval, MMTab)에서 최고 수준의 정확도를 달성한다. 또한, 강화학습 기반의 Reflection Inhibition Reward Mechanism을 개선해 추가적인 성능 상승을 얻었다.
상세 분석
Yuan3.0 Ultra 논문은 현재 MoE 기반 LLM이 직면한 두 가지 핵심 문제—전문가 로드 불균형과 사후 프루닝에만 의존하는 비효율성을 정확히 짚어낸다. 저자들은 20 B 규모 모델을 사전학습하면서 토큰이 각 전문가에 할당되는 패턴을 시계열적으로 분석했으며, 초기 전이 단계와 안정 단계라는 두 구간을 정의한다. 초기 단계에서는 무작위 초기화의 영향으로 토큰 분배가 급격히 변동하지만, 수백만 토큰을 학습한 뒤에는 각 레이어별 전문가 간 토큰 수가 상대적으로 고정된 순위를 형성한다는 점을 발견했다. 이 고정된 순위는 ‘지속적으로 저활용되는 전문가’를 식별하는 신뢰할 수 있는 신호가 된다.
LAEP는 이러한 통계를 기반으로 두 단계의 기준을 적용한다. 첫 번째는 누적 토큰 비율(β) 기준으로 전체 토큰 중 일정 비율 이하를 차지하는 전문가들을 후보군으로 선정한다. 두 번째는 개별 토큰 평균 비율(α) 기준으로 후보군 중 평균 대비 현저히 낮은 로드를 보이는 전문가만을 실제로 제거한다. 수식(2)·(3)에서 α와 β는 각각 전문가당 최소 토큰 수와 전체 토큰 대비 최소 비중을 의미한다. 이중 기준을 통해 과도한 프루닝을 방지하면서도 비효율적인 파라미터를 효과적으로 축소한다.
프루닝 이후 남은 전문가들은 디바이스 간 로드 불균형을 해소하기 위해 greedy 재배치 알고리즘을 적용한다. 전문가를 토큰 로드 기준으로 정렬한 뒤, 고부하와 저부하 전문가를 교차 배치함으로써 각 GPU/TPU의 토큰 처리량 분산을 최소화한다. 이는 기존 MoE 모델에서 흔히 사용되는 부가적인 로드‑밸런싱 손실(auxiliary loss)의 하이퍼파라미터 튜닝 필요성을 없애고, 순수히 데이터‑드리븐 방식으로 효율성을 끌어올린다.
실험 결과는 설득력 있다. 1 515 B 전체 파라미터를 갖는 베이스 모델을 LAEP로 사전학습하면 전체 파라미터가 33.3 % 감소하고, 동일 토큰 수 대비 학습 시간·연산량이 49 % 절감된다. 테스트 손실 측면에서도 α와 β를 적절히 조정하면 프루닝 후 모델이 오히려 베이스보다 낮은 손실을 기록한다(예: β = 0.1, α ≤ 0.4). 이는 ‘프루닝이 정규화 효과’를 제공해 과적합을 완화하고 일반화 성능을 높일 수 있음을 시사한다.
또한, 다양한 어텐션 변형(LFA vs. 전통 Self‑Attention)에서도 LAEP의 효과가 일관되게 나타난다. LFA를 적용한 모델이 기본보다 낮은 손실을 보였으며, 프루닝 후에도 동일한 추세가 유지된다. 이는 LAEP가 모델 아키텍처에 독립적인 일반화 가능성을 갖는다는 증거다.
다운스트림 평가에서는 20 B 모델에 LAEP를 적용했을 때 CMath, GSM8K, TRIVIAQA 등 수치·언어 이해 벤치마크에서 손실이 감소하고, 기업용 시나리오(Docmatix, ChatRAG, SummEval, MMTab)에서는 최고 수준의 정확도를 달성했다. 특히, 파라미터 수를 26.5 %까지 줄이면서도 성능 저하가 거의 없었으며, 일부 태스크에서는 오히려 개선되었다.
마지막으로, 저자들은 Yuan3.0 Flash에서 제안된 Reflection Inhibition Reward Mechanism(RIRM)을 강화학습 파이프라인에 통합해 ‘빠른 사고’(fast‑thinking) 정책을 학습시켰다. 이 개선된 RIRM은 학습 정확도를 16.33 % 상승시키고, 출력 토큰 길이를 14.38 % 단축시켰다. 이는 프루닝과 별개로 모델의 추론 효율성을 높이는 부가적인 기여를 보여준다.
전반적으로, 이 논문은 MoE LLM의 사전학습 단계에서 구조적 프루닝을 적용함으로써 파라미터 효율성, 학습 속도, 그리고 실제 적용 성능을 동시에 개선한 최초 사례이며, 향후 대규모 MoE 모델 개발에 중요한 설계 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기