탄소 인식 품질 조정으로 에너지 집약 서비스 탄소 절감
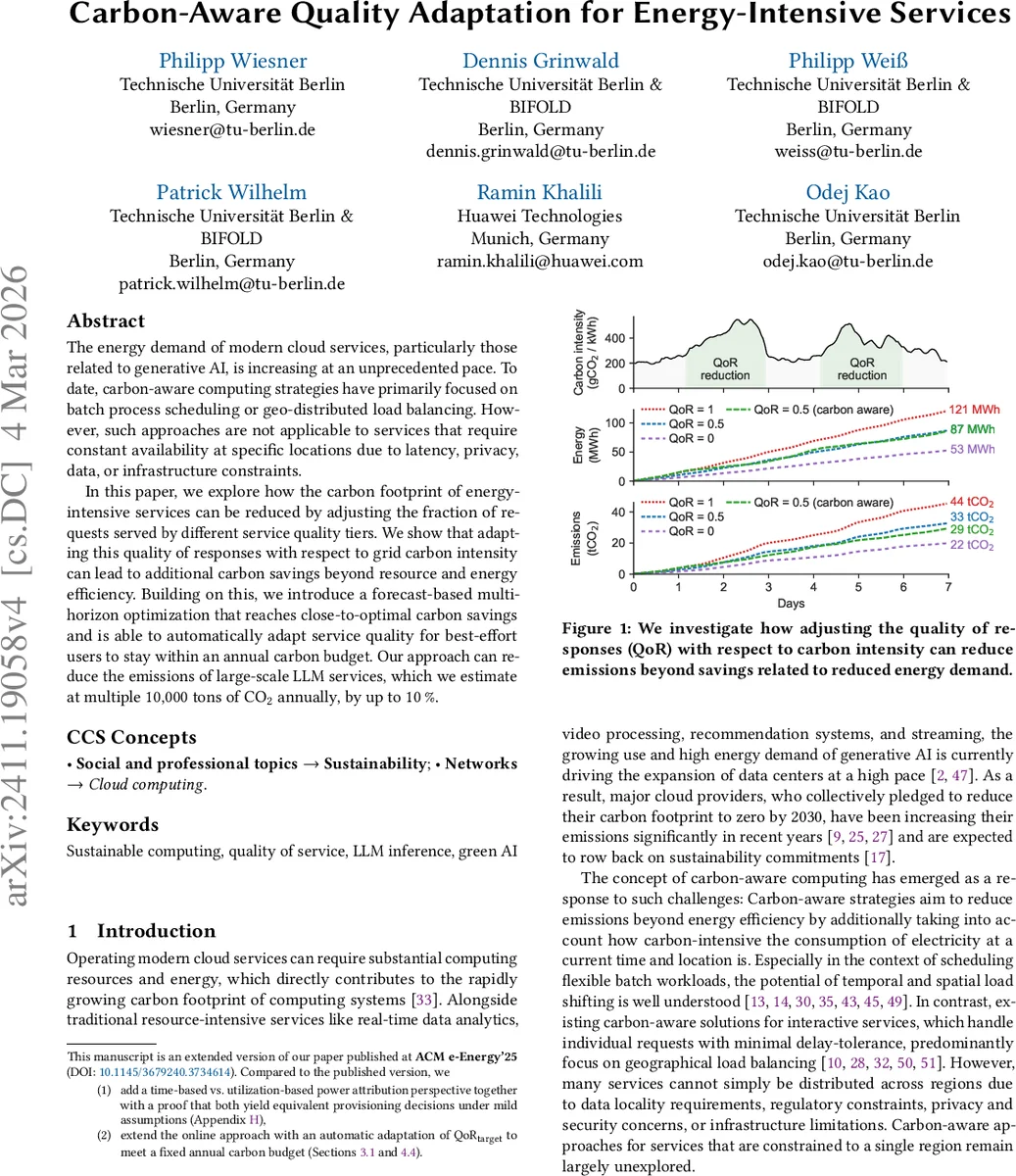
초록
본 논문은 지리적 분산이 불가능한 실시간 클라우드 서비스에서, 전력 사용량이 높은 고품질 응답과 저품질 응답을 비율적으로 조절함으로써 전력 사용량과 탄소 집약도를 동시에 최소화하는 방법을 제시한다. 탄소 강도 예측을 기반으로 한 다중 시간대 최적화 알고리즘을 설계하고, 연간 탄소 예산 내에서 최적 QoR(품질 비율)를 자동 조정한다. 대규모 LLM 추론 서비스를 사례로 시뮬레이션한 결과, 연간 수만 톤 규모의 CO₂ 배출량을 최대 10 %까지 감소시킬 수 있음을 보였다.
상세 분석
이 연구는 기존의 배치 작업 스케줄링이나 지리적 로드 밸런싱에 의존하던 탄소 인식 컴퓨팅 접근법이 실시간 서비스에는 적용이 어려운 점을 지적한다. 특히 지연, 프라이버시, 데이터 주권 등으로 특정 지역에 고정된 서비스에서는 전력 사용량을 줄이는 것만으로는 충분한 탄소 절감 효과를 기대하기 어렵다. 논문은 이러한 한계를 극복하기 위해 ‘품질 응답 비율(QoR)’이라는 새로운 QoS 지표를 도입한다. QoR은 두 가지 품질 티어(고품질·고전력, 저품질·저전력) 사이의 요청 비율을 0~1 사이의 실수로 표현한다. QoR = 1이면 모든 요청을 고품질 티어로 처리하고, QoR = 0이면 모두 저품질 티어로 처리한다.
탄소 인식 QoR 조정의 핵심 아이디어는 전력 그리드의 탄소 강도(ACI)가 시간에 따라 변동한다는 사실을 활용하는 것이다. 탄소 강도가 낮은 시점에 고품질 티어를 더 많이 제공하고, 탄소 강도가 높은 시점에는 저품질 티어로 전환함으로써 동일한 서비스 수준을 유지하면서도 전체 배출량을 감소시킬 수 있다. 이를 위해 논문은 다음과 같은 수학적 모델을 구축한다.
-
시간 구간 및 유효 기간: 전체 최적화 기간 T를 Δ 간격으로 나누어 I = T/Δ개의 구간을 만든다. QoR은 겹치는 롤링 윈도우(길이 γ) 내에서 최소값을 보장하도록 정의된다. γ가 길수록 탄소 강도 변동에 대한 조정 유연성이 커지지만, 짧은 구간에서는 급격한 QoR 변동이 발생할 위험이 있다.
-
탄소 배출 모델: 각 구간 i에서의 배출량 E_i는 활성 머신의 전력 사용량 p_i,m,q와 해당 지역의 탄소 강도 C_i, 그리고 기계별 내재 배출 C_emb,m을 합산한 형태로 정의된다(Eq. 2). 전력 사용량은 두 가지 방식으로 귀속될 수 있다. (a) 활용 기반(power = f(utilization))은 실제 CPU/GPU 사용률에 따라 전력이 비선형적으로 증가한다. (b) 시간 기반은 인스턴스가 가동되는 시간당 고정 전력을 할당한다. 논문은 완만한 볼록성 가정 하에 두 방식이 동일한 배치 결정을 초래한다는 증명을 부록 H에 제공한다.
-
최적화 문제: 목표는 전체 배출량 ΣE_i를 최소화하면서 (i) 모든 요청이 어느 한 품질 티어에 할당되고, (ii) 배치된 머신 용량이 요청을 충분히 처리하며, (iii) 모든 유효 기간에 걸쳐 QoR ≥ QoR_target을 만족하도록 하는 MILP 형태의 제약식이다(Eqs. 4‑7). 이 문제는 NP‑hard이며, 미래 탄소 강도와 요청량에 대한 정확한 정보를 필요로 한다.
-
다중 시간대 온라인 알고리즘: 실시간 적용을 위해 두 단계의 최적화를 제안한다. 장기 최적화는 τ 간격(예: 24 h)마다 전체 연간 전망을 기반으로 MILP를 풀어 전역적인 QoR 제약을 만족하도록 한다. 단기 최적화는 현재 시점부터 γ 구간까지의 짧은 전망을 사용해 빠르게 (보통 1‑2 초) 최적해를 찾는다. 단기 단계에서 해결되지 않으면 QoR = 1(전부 고품질)으로 강제하고 최소 머신 수만 배치한다.
-
연간 탄소 예산 하의 QoR 자동 조정: 연간 배출 한도 B가 주어지면 QoR_target 자체를 의사결정 변수로 두고, ΣE_i ≤ B를 만족하면서 가능한 최고 QoR_target을 최대화한다(Eqs. 8‑10). 매 시점마다 이미 사용된 배출량을 차감한 남은 예산 B_rem(α)를 계산하고, 남은 기간에 대해 장기 최적화를 재실행한다.
실험에서는 2023년 실제 탄소 강도 데이터와 8개의 다양한 요청 트레이스를(정적, 랜덤, 위키 페이지뷰, 택시 호출, Borg 클러스터 합성 트레이스) 사용해 LLaMA 3.1 8B와 70B 모델을 각각 저품질·고품질 티어로 매핑하였다. EC2 p4d.24xlarge 인스턴스를 기준으로 전력 소비와 내재 배출을 모델링하고, Gurobi 솔버로 MILP를 해결했다. 결과는 다음과 같다.
- 탄소 강도가 낮은 시기에 고품질 티어 비중을 늘리고, 강도가 높은 시기에 저품질 티어로 전환함으로써 연간 배출량을 평균 6‑10 % 절감했다.
- 연간 예산 제약 하에서는 초기 QoR_target을 0.7 수준으로 설정했을 때, 전체 연간 배출량이 예산 한도 내에 머무르면서도 평균 QoR는 0.85 이상 유지되었다.
- 장기 최적화 주기를 τ를 24 h로 잡을 경우, 단기 최적화와 결합했을 때 전체 솔버 시간은 연간 시뮬레이션 전체에 대해 3 시간 미만으로 제한되었다.
이러한 결과는 서비스 품질을 일정 수준 이상 유지하면서도 탄소 배출을 실질적으로 감소시킬 수 있음을 보여준다. 특히 규제·프라이버시 등으로 지리적 이동이 불가능한 LLM 추론 서비스와 같은 고전력, 고가용성 요구 서비스에 적용 가능하다. 논문은 코드와 데이터셋을 공개함으로써 재현성을 확보하고, 향후 다중 품질 티어(>2)와 사용자 맞춤형 QoR 정책을 포함한 확장 연구 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기