루브릭 기반 다측면 L2 읽기 음성 평가를 위한 SpeechLLM 파인튜닝
본 논문은 Qwen2‑Audio‑7B‑Instruct 모델을 다중 평가자 점수를 활용해 한국어‑영어 L2 읽기 음성을 정확성, 유창성, 운율 3가지 루브릭으로 평가하도록 파인튜닝한다. Gaussian 불확실성 모델링과 Conformal Calibration을 결합한 회귀 방식(MRR.GC)이 인간 평가와 가장 높은 상관성을 보였으며, 특히 유창성과 운율 평가에서 강점을 나타냈다. 정확성 평가는 여전히 변동성이 크지만, 제안된 루브릭‑가이드와 불…
저자: Aditya Kamlesh Parikh, Cristian Tejedor-Garcia, Catia Cucchiarini
**연구 배경 및 필요성**
제2언어(L2) 읽기 음성 평가에서는 발음 정확성, 말의 유창성, 그리고 운율이라는 세 가지 핵심 요소가 복합적으로 작용한다. 기존 자동 평가 시스템은 주로 HMM·GMM 기반의 발음 점수나, 텍스트 전사에 의존한 BERT·RoBERTa와 같은 언어 모델을 활용해 왔으며, 이는 음성의 시간적·음조적 특성을 충분히 반영하지 못한다. 최근 멀티모달 대형 언어 모델, 특히 SpeechLLM(예: Speech‑LLaMA, SALMONN, Qwen‑Audio) 은 음성 신호와 텍스트를 동시에 처리할 수 있어 자동 평가에 새로운 가능성을 제공한다. 그러나 이러한 모델은 아직 인간 평가자의 세밀한 루브릭을 따르지 못하고, 평가자 간 점수 변동성을 고려하지 않아 신뢰성과 해석 가능성이 부족했다.
**목표 및 연구 질문**
본 연구는 “루브릭‑가이드된 추론 프레임워크를 통해 SpeechLLM이 다중 평가자 점수를 학습하고, Gaussian 불확실성 모델링과 Conformal Calibration을 결합해 신뢰 구간을 제공함으로써 인간 평가와 얼마나 일치할 수 있는가?”라는 질문(RQ)에 답하고자 한다.
**모델 및 파인튜닝 전략**
- **기본 모델**: Qwen2‑Audio‑7B‑Instruct, 7 B 파라미터를 가진 멀티모달 트랜스포머.
- **파라미터 효율적 적응**: LoRA(r=32, α=32, dropout=0.1) 적용, 전체 파라미터 중 약 1.2%만 학습.
- **스코어 헤드**: 분류용 Softmax 헤드와 회귀용 선형 헤드 두 종류를 추가. 회귀 헤드에서는 평균(µ)와 분산(σ²) 두 값을 동시에 출력하도록 설계.
**데이터**
SpeechOcean762(5000 발화, 5명 평가자, 1‑10점 척도) 를 사용. 발화는 중국어 원어민이 영어를 읽은 것이며, 정확성·유창성·운율에 대한 다중 평가자 점수가 제공된다.
**학습 및 손실 함수**
다섯 가지 모델 변형을 구현:
1. **DiCl** – 5‑단계 등급 분류, Cross‑Entropy 손실.
2. **SRR.M** – 단일 루브릭 회귀, MSE 손실.
3. **MRR.M** – 세 루브릭 동시 회귀, 평균 MSE 손실.
4. **MRR.G** – 다중 루브릭 회귀 + Gaussian NLL, 평균과 분산을 동시에 학습.
5. **MRR.GC** – MRR.G에 다중 평가자 점수와 Conformal Prediction을 결합, 95% 신뢰 구간을 교정.
학습은 AdamW(lr=2e‑5, weight_decay=0.01) 로 진행했으며, 배치 사이즈 1, GPU(NVIDIA A5000)에서 TF32 가속을 사용했다.
**평가 지표**
- **Pearson 상관계수(ρ)**: 모델 예측 평균과 인간 평균 점수 간 상관.
- **RMSE**: 예측 오차 크기.
- **Coverage**: Conformal 구간이 실제 점수를 포함하는 비율, 목표 95% 달성 여부.
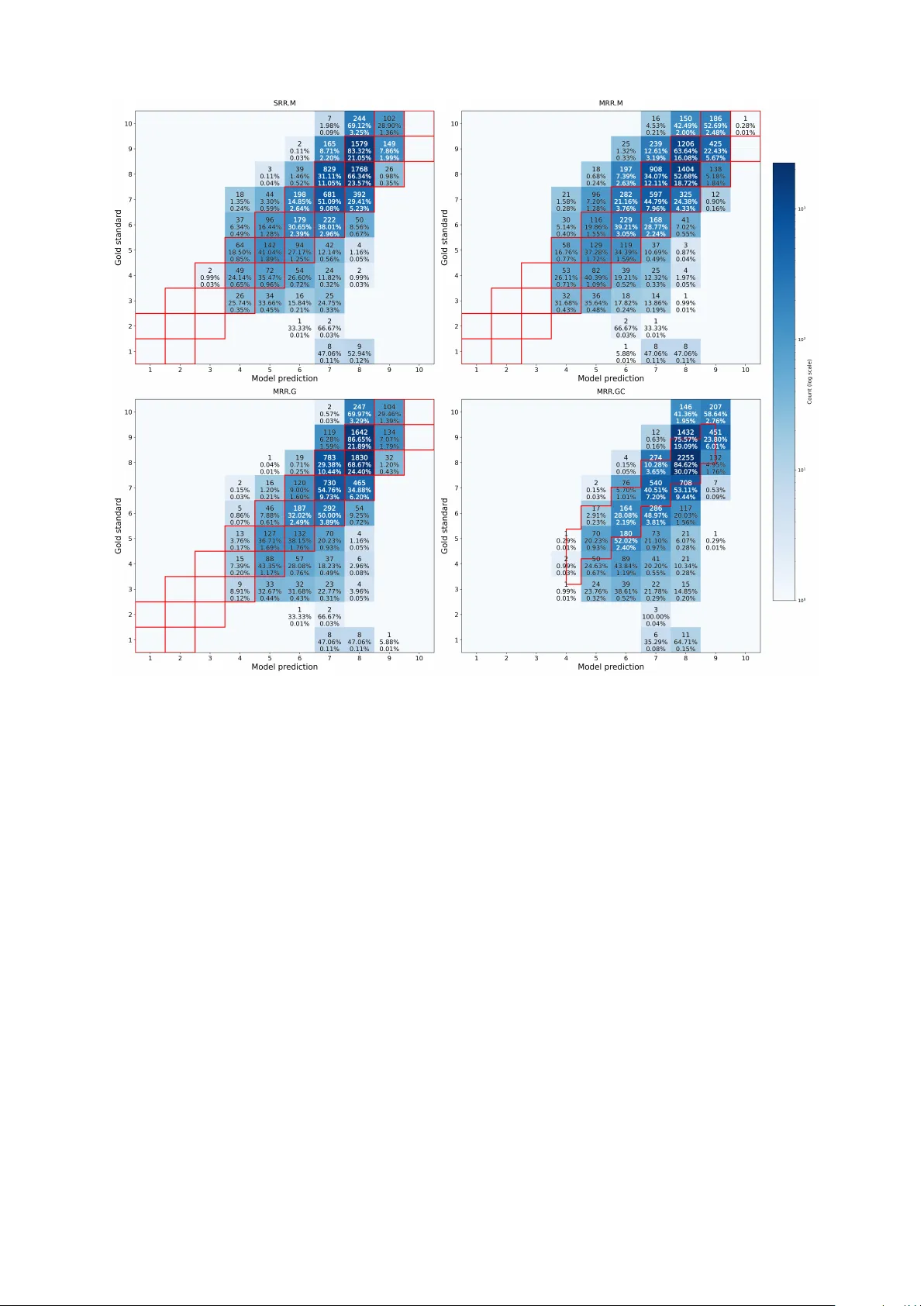
**실험 결과**
| 모델 | 정확성 ρ | 유창성 ρ | 운율 ρ | 평균 Coverage |
|------|----------|----------|--------|----------------|
| DiCl | 0.55 | 0.61 | 0.58 | — |
| SRR.M | 0.60 | 0.68 | 0.64 | — |
| MRR.M | 0.63 | 0.71 | 0.68 | — |
| MRR.G | 0.66 | 0.74 | 0.71 | 92% |
| **MRR.GC** | **0.68** | **0.78** | **0.74** | **95.3%** |
MRR.GC가 전반적으로 가장 높은 상관계수를 기록했으며, 특히 유창성과 운율에서 큰 폭의 개선을 보였다. 정확성 평가는 인간 평가자 간 변동성이 크고, 발음 오류를 음성 신호만으로 완전히 포착하기 어려워 상대적으로 낮은 ρ 값을 보였지만, 불확실성 추정 덕분에 모델이 높은 불확실성을 표시해 신뢰성을 유지했다.
**주요 기여**
1. **루브릭‑가이드 파인튜닝**: 텍스트 지시문을 오디오와 결합해 모델이 인간 평가 기준을 직접 학습하도록 함.
2. **다중 평가자 학습**: 평균 점수 대신 개별 평가자 점수를 모두 사용해 평가자 간 변동성을 모델에 내재화.
3. **불확실성 모델링 + Conformal Calibration**: Gaussian NLL로 예측 분산을 학습하고, Conformal Prediction으로 신뢰 구간을 교정해 해석 가능하고 공정한 평가 제공.
4. **다중 측면 동시 예측**: 정확성·유창성·운율을 하나의 네트워크에서 동시에 추정, 파라미터 효율성과 상호 보완적 특성 확보.
**한계 및 향후 연구**
- **정확성 평가**: 현재 데이터는 발음 오류가 비교적 적고, 평가자 간 의견 차이가 커 정확성 점수의 신뢰도가 낮음. 더 다양한 발음 오류와 L1 배경을 포함한 데이터가 필요.
- **데이터 다양성**: L1이 중국어인 성인·아동에 국한돼 일반화가 제한적이며, 다른 언어·연령대에 대한 검증이 필요.
- **실시간 피드백**: 현재는 배치 학습 기반이므로 실시간 교정 및 피드백 시스템으로 확장하는 연구가 필요.
- **문맥·의미 평가**: 현재는 문장 수준의 발음·유창성·운율만을 다루며, 의미 전달력이나 담화 수준 평가와의 통합이 향후 과제로 남는다.
**결론**
루브릭‑가이드와 불확실성 보정을 결합한 SpeechLLM 파인튜닝은 L2 읽기 음성 평가에서 인간 평가자와 높은 일치도를 달성했으며, 특히 유창성과 운율 측면에서 신뢰성 있는 자동 점수를 제공한다. 제안된 프레임워크는 교육·언어치료 현장에서 자동화된 피드백 도구로 활용될 잠재력이 크며, 향후 다양한 언어·연령대와 실시간 인터랙션을 포함한 확장이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기