컨텍스트와 잔차 정보를 활용한 효율적 방사선 보고서 생성
초록
본 논문은 X‑ray 이미지의 시각 토큰을 선형 복잡도를 갖는 Mamba 백본으로 추출하고, 학습 단계에서 동일 미니배치 내 양·음성 컨텍스트 샘플을 검색해 잔차 토큰을 만든 뒤, 이를 프롬프트와 함께 대형 언어 모델(LLM)에 입력하여 고품질 방사선 보고서를 자동 생성한다. IU X‑Ray, MIMIC‑CXR, CheXpert Plus 세 데이터셋에서 기존 Transformer 기반 방법 대비 성능·효율성을 모두 향상시켰다.
상세 분석
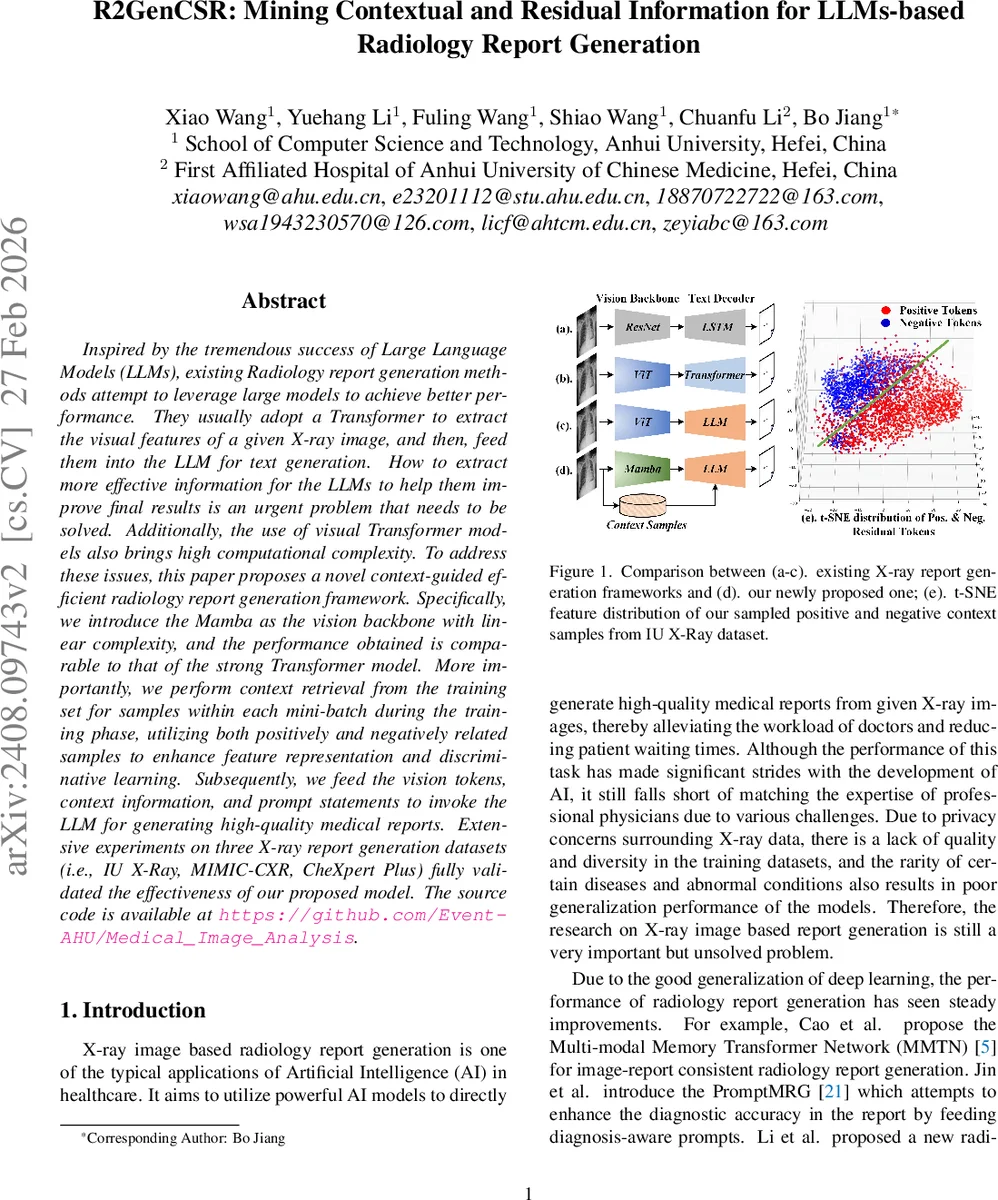
R2GenCSR는 기존 방사선 보고서 생성 파이프라인의 두 가지 핵심 병목을 동시에 해결한다. 첫 번째는 시각 인코더의 계산량이다. 대부분의 최신 연구가 Vision Transformer(ViT)나 그 변형을 사용해 이미지 패치를 토큰화하고 전역 self‑attention을 적용한다. 이는 토큰 수 N에 대해 O(N²) 복잡도를 초래해 고해상도 X‑ray를 처리할 때 메모리와 시간 비용이 급증한다. 저자는 이러한 문제를 State‑Space Model(SSM) 기반의 Mamba 구조로 대체한다. Mamba는 연속적인 상태 전이 행렬 A와 입력‑출력 매트릭스 B를 시간‑가변적으로 조정하면서도 재귀적 업데이트를 통해 전체 시퀀스를 선형 O(N) 비용으로 처리한다. 이미지 패치를 순차적으로 입력하면, 숨겨진 상태 hₜ가 이전 패치들의 누적 정보를 저장하므로 명시적인 전역 receptive field를 구현하면서도 계산량을 크게 줄인다. 또한, 입력‑의존적 선택 메커니즘이 비정상 영역을 강조하고 정상 영역을 압축하는 효과를 제공한다는 점에서 의료 영상의 특성(병변이 국소적이면서도 전체 해부학적 맥락이 필요)과 잘 맞는다.
두 번째 병목은 LLM에 전달되는 텍스트 프롬프트의 풍부함이다. 기존 연구는 이미지 토큰만을 LLM에 주입하거나, 간단한 질의‑응답 형태의 프롬프트만 사용한다. R2GenCSR는 미니배치 내에서 현재 이미지와 가장 유사한 양성(질병 있음) 및 음성(정상) 샘플을 동적으로 검색한다. 검색 기준은 시각 토큰 공간에서의 코사인 유사도 혹은 학습된 임베딩 거리이며, 양·음성 샘플을 모두 활용함으로써 “대조적 컨텍스트”를 제공한다. 검색된 샘플은 동일한 Mamba 백본을 거쳐 토큰화된 후, 현재 이미지의 글로벌 토큰(예:
댓글 및 학술 토론
Loading comments...
의견 남기기