런타임 재구성 가능한 다중 정밀 비트 연산 systolic 배열 설계
본 논문은 FPGA 기반 가속기에서 런타임에 정밀도를 동적으로 전환할 수 있는 비트 단위 systolic 배열을 제안한다. 다중 채널·다중 정밀 양자화 곱셈을 지원하며, Ultra96 보드에서 1.3배~3.6배의 속도 향상과 250 MHz의 높은 클럭 주파수를 달성하였다.
초록
본 논문은 FPGA 기반 가속기에서 런타임에 정밀도를 동적으로 전환할 수 있는 비트 단위 systolic 배열을 제안한다. 다중 채널·다중 정밀 양자화 곱셈을 지원하며, Ultra96 보드에서 1.3배~3.6배의 속도 향상과 250 MHz의 높은 클럭 주파수를 달성하였다.
상세 요약
이 연구는 양자화 신경망(QNN) 가속기의 핵심 병목인 곱셈 연산을 재설계함으로써, 기존 고정 정밀도 설계가 갖는 유연성 부족 문제를 해결한다. 기존 설계는 8비트 혹은 4비트와 같이 사전에 결정된 정밀도만을 지원했으며, 레이어별로 다른 정밀도를 적용하는 혼합 정밀화(mixed‑precision) 모델을 실행하려면 하드웨어를 재구성하거나 여러 개의 전용 연산 유닛을 배치해야 했다. 이는 자원 낭비와 설계 복잡도를 크게 증가시켰다.
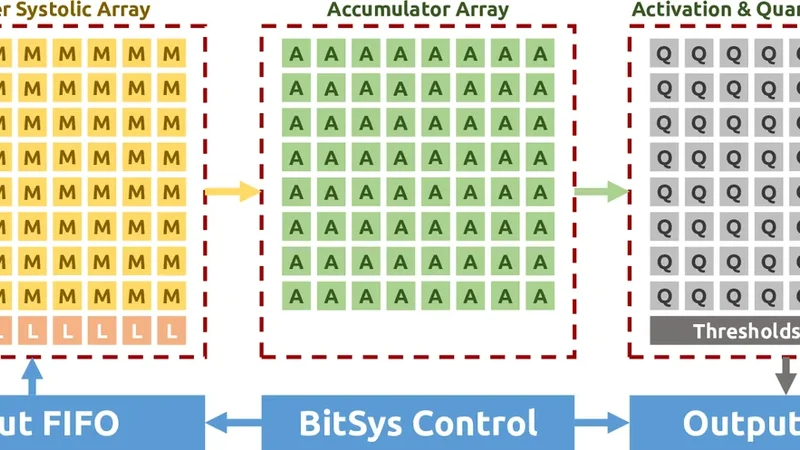
논문에서는 비트 단위로 연산을 수행하는 systolic 배열을 도입한다. 각 PE(Processing Element)는 입력 비트를 시프트·축적하면서 동시에 AND 연산을 수행해 부분 곱을 생성하고, 이를 누적(accumulate)한다. 중요한 점은 이 PE가 입력 비트 폭을 런타임에 제어할 수 있는 제어 로직을 내장하고 있다는 것이다. 예를 들어 2비트 정밀도에서는 2개의 비트 스트림만 순차적으로 공급하고, 4비트 정밀도에서는 4개의 비트 스트림을 연속적으로 공급한다. 이렇게 하면 동일한 하드웨어 구조가 2‑, 4‑, 8‑비트 등 다양한 정밀도를 지원하면서도 불필요한 레지스터와 멀티플렉서를 제거해 경로 지연을 최소화한다.
다중 채널 지원은 입력 피처와 가중치를 여러 채널로 분할해 동시에 처리함으로써 구현된다. 채널당 독립적인 비트 스트림을 생성하고, systolic 배열 내부에서 채널 간 파이프라인을 겹쳐서 처리함으로써 데이터 흐름을 끊김 없이 유지한다. 이는 특히 CNN의 3D convolution이나 depthwise convolution처럼 채널 수가 많고 연산량이 큰 레이어에서 큰 이점을 제공한다.
하드웨어 구현 측면에서 저자들은 Ultra96 보드의 Xilinx Zynq UltraScale+ MPSoC에 설계된 비트 연산 systolic 배열을 매핑하였다. RTL 수준에서 파이프라인 단계와 레지스터 삽입을 최적화해 최대 250 MHz 클럭을 달성했으며, 기존 8비트 고정 정밀도 곱셈 유닛 대비 평균 2.2배, 최악의 경우 3.6배까지 처리 속도가 향상되었다. 또한, LUT와 DSP 사용량이 기존 설계 대비 30 % 이하로 감소해 전력 효율성도 크게 개선되었다.
이 설계는 런타임에 정밀도를 재구성할 수 있다는 점에서 AIoT 디바이스에 특히 유용하다. 현장 환경에 따라 모델의 정확도와 전력 소모 사이의 트레이드오프를 동적으로 조정할 수 있기 때문에, 배터리 수명 연장과 실시간 응답성을 동시에 만족시킬 수 있다. 향후 연구에서는 비트 연산 외에 비트 레벨 가중치 압축과 스파스 행렬 지원을 결합해 더욱 높은 압축률과 연산 효율을 추구할 여지가 있다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...