물리 기반 점성 가치 표현으로 강화학습 성능 향상
오프라인 목표조건 강화학습에서 값 함수의 정확한 추정은 데이터 커버리지가 제한적일 때 어려워진다. 기존 연구는 유클리드 거리와 같은 1차 편미분 방정식(Eikonal) 기반 정규화를 사용했지만 고차원 복잡 환경에서는 발산하거나 불안정해지는 문제가 있다. 본 논문은 해밀턴‑자코비‑벨만(HJB) 방정식의 점성 해(viscosity solution)를 이용한 물
초록
오프라인 목표조건 강화학습에서 값 함수의 정확한 추정은 데이터 커버리지가 제한적일 때 어려워진다. 기존 연구는 유클리드 거리와 같은 1차 편미분 방정식(Eikonal) 기반 정규화를 사용했지만 고차원 복잡 환경에서는 발산하거나 불안정해지는 문제가 있다. 본 논문은 해밀턴‑자코비‑벨만(HJB) 방정식의 점성 해(viscosity solution)를 이용한 물리‑인포드 정규화를 제안한다. Feynman‑Kac 정리를 통해 PDE 해를 기대값 형태로 변환하고, 이를 Monte‑Carlo 샘플링으로 근사함으로써 고차 미분의 수치 불안정을 회피한다. 실험 결과, 내비게이션과 고차원 조작 과제 모두에서 기하학적 일관성이 크게 향상되고, 기존 방법 대비 샘플 효율과 정책 성능이 개선됨을 보였다.
상세 요약
본 연구는 오프라인 목표조건 강화학습(GCRL)에서 가치 함수의 일반화 한계를 물리 기반 정규화로 극복하고자 한다. 핵심 아이디어는 최적 제어 이론의 근간인 해밀턴‑자코비‑벨만(HJB) 방정식의 점성 해(viscosity solution)를 활용해 가치 함수에 대한 강인한 inductive bias를 부여하는 것이다. 점성 해는 비선형 1차 편미분 방정식이 존재하지 않을 경우에도 유일하고 안정적인 약해(solution) 형태를 제공한다는 수학적 특성을 갖는다. 따라서 복잡하고 차원이 높은 상태‑액션 공간에서도 정규화가 발산하지 않고, 값 업데이트가 자연스럽게 경계조건과 물리적 제약을 만족하도록 강제한다.
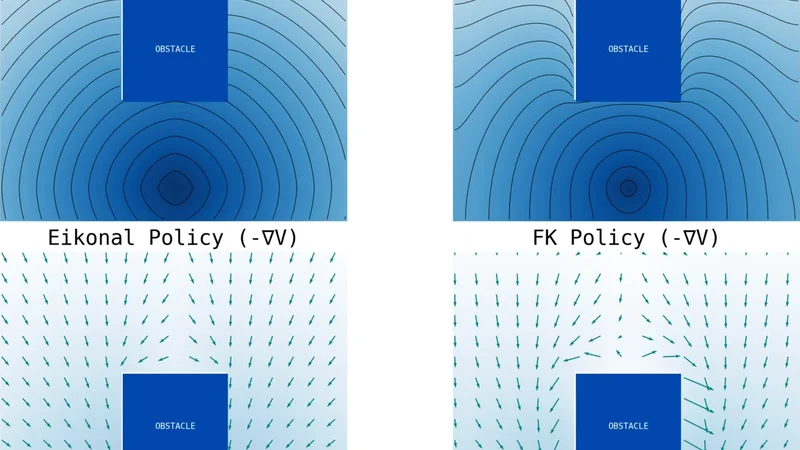
기존의 물리‑인포드 접근법은 주로 Eikonal 방정식 ‑‖∇V‖=1 형태의 1차 PDE를 정규화 항으로 사용했으며, 이는 거리 함수와 같은 기하학적 일관성을 부여하지만, 고차원에서 ∇V의 노이즈가 급격히 증폭돼 학습이 불안정해지는 단점이 있다. 특히, 값 함수가 비선형이고 다중 목표가 존재하는 환경에서는 Eikonal 정규화가 충분히 강력한 제약을 제공하지 못한다.
논문은 이러한 한계를 극복하기 위해 HJB 방정식의 점성 해를 기반으로 한 정규화 항 L_viscous를 정의한다. L_viscous는 ‖∇V(s,g) + f(s,a)‖² 형태로, 여기서 f는 시스템 동역학을 나타내는 함수이며, 목표 g에 대한 최적 가치 V와 동역학이 일치하도록 강제한다. 이때, 점성 파라미터 ε>0를 도입해 ‖∇V‖²에 작은 양의 점성 항을 추가함으로써 수치적 안정성을 확보한다.
또한, 논문은 Feynman‑Kac 정리를 이용해 HJB PDE의 해를 확률적 기대값 형태로 변환한다. 구체적으로, V(s,g)=E
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...