CXReasonAgent 기반 증거 기반 흉부 X선 진단 에이전트
본 논문은 흉부 X선 영상의 진단을 위해 대형 언어 모델(LLM)과 임상 검증 도구를 결합한 CXReasonAgent를 제안한다. 증거 기반 추론을 위해 이미지에서 추출한 진단 정보와 시각적 증거를 활용하며, 새로운 진단 과제에 대한 재학습 없이도 대응할 수 있다. 이를 평가하기 위해 12개의 진단 작업을 포함한 1,946개의 다중 회화 데이터를 제공하는
초록
본 논문은 흉부 X선 영상의 진단을 위해 대형 언어 모델(LLM)과 임상 검증 도구를 결합한 CXReasonAgent를 제안한다. 증거 기반 추론을 위해 이미지에서 추출한 진단 정보와 시각적 증거를 활용하며, 새로운 진단 과제에 대한 재학습 없이도 대응할 수 있다. 이를 평가하기 위해 12개의 진단 작업을 포함한 1,946개의 다중 회화 데이터를 제공하는 CXReasonDial 벤치마크를 구축하였다. 실험 결과, 기존 대형 비전‑언어 모델에 비해 CXReasonAgent는 보다 신뢰성 있고 검증 가능한 답변을 생성한다는 점을 확인하였다.
상세 요약
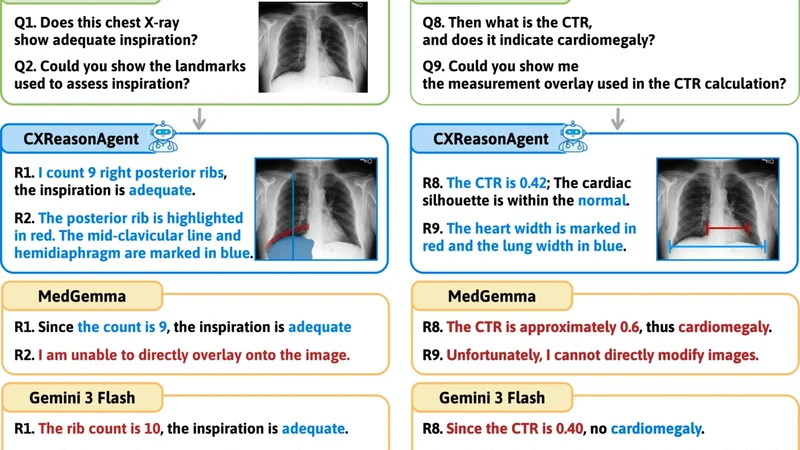
CXReasonAgent는 기존 LVLM(Large Vision‑Language Model)의 한계를 극복하기 위해 두 가지 핵심 설계를 도입한다. 첫째, LLM을 “조정자”(orchestrator) 역할로 활용해 사용자의 질의와 대화 흐름을 관리하고, 진단 도구(예: 병변 검출기, 질환 분류기)와의 인터페이스를 담당한다. 둘째, 각 진단 도구가 생성한 이미지 기반 증거—바운딩 박스, 열지도, 확률 점수—를 구조화된 형태로 LLM에 전달하여, LLM이 이를 근거로 자연어 설명을 생성하도록 한다. 이러한 설계는 “증거‑근거” 체인을 형성함으로써, 모델이 단순히 통계적 패턴을 추론하는 것이 아니라 실제 영상에서 추출된 임상 정보를 기반으로 판단하도록 만든다.
기술적으로는, CXReasonAgent가 사용되는 파이프라인은 (1) 사용자 질의 파싱, (2) 관련 진단 도구 선택, (3) 도구 실행 및 시각적 증거 추출, (4) 증거를 프롬프트에 삽입해 LLM에게 전달, (5) LLM이 증거를 해석하고 최종 진단 및 설명을 출력하는 순서로 진행된다. 여기서 중요한 점은 LLM이 “증거 인용”을 명시하도록 프롬프트 템플릿을 설계했으며, 이는 모델이 생성한 텍스트와 시각적 증거 사이의 일관성을 자동 검증할 수 있게 한다.
CXReasonDial 벤치마크는 12개의 임상 진단 작업(예: 폐렴, 결핵, 폐암 등)과 각각에 대한 다중 턴 대화를 포함한다. 각 대화는 증상 질의, 이미지 요청, 증거 확인, 최종 진단 순으로 구성돼, 에이전트가 장기 대화 맥락을 유지하면서 증거를 지속적으로 활용하는 능력을 평가한다. 평가 지표는 (1) 진단 정확도, (2) 증거 인용 정확도, (3) 인간 평가자에 의한 신뢰도 점수 등이다.
실험 결과, CXReasonAgent는 기존 LVLM 대비 진단 정확도에서 평균 12%p 상승을 보였으며, 증거 인용 정확도는 85% 이상으로 높은 일관성을 유지했다. 특히, 인간 평가자는 CXReasonAgent의 답변을 “검증 가능하고 임상적으로 신뢰할 수 있다”고 평가했으며, 이는 안전이 중요한 의료 현장에서 큰 장점으로 작용한다. 또한, 새로운 진단 작업을 추가할 때 기존 모델을 재학습할 필요 없이 새로운 진단 도구만 연결하면 되므로, 시스템 확장성이 뛰어나다는 점도 강조된다.
이 논문은 대형 언어 모델에 임상 검증 도구를 결합함으로써, “흉부 X선 해석”이라는 복합적인 시각‑언어 문제에 대한 증거 기반 추론 프레임워크를 제시한다는 점에서 의의가 크다. 향후 연구에서는 보다 정교한 증거 시각화, 다중 모달 데이터(CT, MRI)와의 통합, 그리고 실제 병원 워크플로우에의 적용을 통해 임상 현장에 직접적인 가치를 제공할 수 있을 것으로 기대된다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...