미세조정 없이 인컨텍스트 학습 유지 선형 어텐션 모델 이론
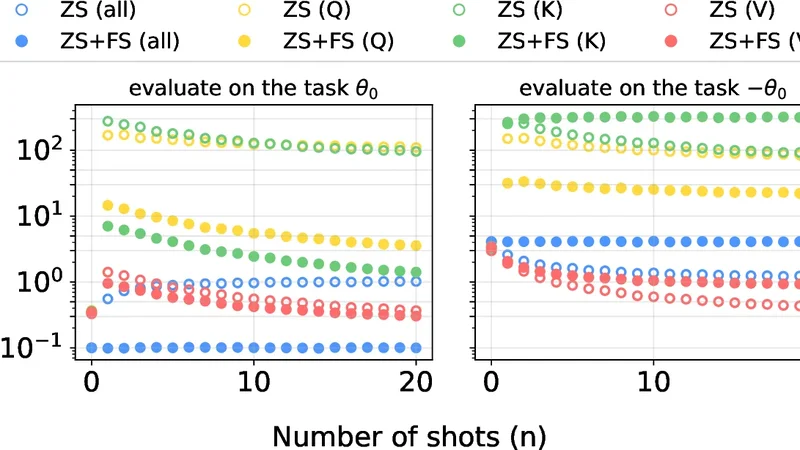
본 논문은 선형 어텐션 구조를 이용해 대형 언어 모델의 미세조정이 인컨텍스트 학습에 미치는 영향을 이론적으로 분석한다. 모든 어텐션 파라미터를 업데이트하면 몇 샷 성능이 저하되는 반면, 값(value) 행렬만 제한적으로 조정하면 제로샷 성능을 높이면서 인컨텍스트 학습을 보존한다. 또한 보조 몇 샷 손실을 도입하면 목표 작업에 대한 인컨텍스트 학습이 향상되지
초록
본 논문은 선형 어텐션 구조를 이용해 대형 언어 모델의 미세조정이 인컨텍스트 학습에 미치는 영향을 이론적으로 분석한다. 모든 어텐션 파라미터를 업데이트하면 몇 샷 성능이 저하되는 반면, 값(value) 행렬만 제한적으로 조정하면 제로샷 성능을 높이면서 인컨텍스트 학습을 보존한다. 또한 보조 몇 샷 손실을 도입하면 목표 작업에 대한 인컨텍스트 학습이 향상되지만, 미세조정되지 않은 다른 작업에서는 성능이 떨어진다. 실험을 통해 이론적 예측을 검증하였다.
상세 요약
이 연구는 트랜스포머 기반 대형 언어 모델이 프롬프트에 포함된 몇 개의 예시(데모)를 통해 새로운 작업을 즉석에서 학습하는 인컨텍스트 학습 능력을 갖는다는 사실에 착안한다. 그러나 실제 서비스에서는 비용 절감을 위해 모델을 미세조정(fine‑tuning)하여 제로샷 성능을 높이려는 경우가 많다. 저자는 선형 어텐션(linear attention)이라는 단순화된 어텐션 메커니즘을 채택해, 미세조정 과정에서 파라미터가 어떻게 변하고 이것이 인컨텍스트 학습에 어떤 영향을 미치는지를 수학적으로 규명한다. 주요 결과는 다음과 같다. 첫째, 전체 어텐션 행렬(Q, K, V)을 자유롭게 업데이트하면, 학습 데이터에 특화된 방향으로 파라미터가 이동해 데모 입력에 대한 표현이 왜곡된다. 이로 인해 프롬프트에 포함된 새로운 예시가 기존 파라미터와 일치하지 않아, 몇 샷 성능이 급격히 저하된다. 둘째, 업데이트를 V(값) 행렬에만 제한하면, 키와 쿼리의 관계는 유지된 채 출력값만 조정된다. 이는 제로샷 성능을 향상시키면서도, 프롬프트 내 데모가 여전히 올바른 키‑쿼리 매칭을 수행하도록 하여 인컨텍스트 학습을 보존한다. 셋째, 보조적인 몇 샷 손실을 미세조정 목표에 추가하면, 목표 작업에 대한 인컨텍스트 학습은 크게 개선되지만, 이 손실이 다른 작업에 대한 일반적인 인컨텍스트 능력을 억제한다는 트레이드오프가 발생한다. 저자는 이러한 현상을 정규화된 손실 함수와 파라미터 업데이트 식을 통해 명시적으로 도출하고, 파라미터 공간에서의 이동 거리와 학습된 프롬프트 표현 간의 상관관계를 분석한다. 마지막으로, 이론적 결과를 검증하기 위해 실제 선형 어텐션 기반 모델을 사용해 다양한 자연어 처리 벤치마크에 대해 미세조정 전후의 제로샷·몇 샷 성능을 측정하였다. 실험은 이론이 예측한 대로, 전체 파라미터 업데이트 시 몇 샷 성능이 크게 감소하고, V‑만 업데이트 시 두 성능이 모두 유지되는 것을 보여준다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...