다이아로그 제스처 생성의 새로운 패러다임 DyaDiT
DyaDiT는 양측 화자의 오디오와 사회적 맥락 정보를 동시에 입력받아, 대화 상황에 맞는 자연스러운 상체 제스처를 생성하는 확산 기반 트랜스포머 모델이다. ORCA 모듈로 두 오디오 스트림을 정교히 분리하고, 모션 사전과 VQ‑VAE 토크나이저를 활용해 동작의 스타일과 세부 디테일을 제어한다. 실험 결과, 기존 방법들을 객관적 지표와 사용자 평가 모두에서 크게 앞섰다.
저자: Yichen Peng, Jyun-Ting Song, Siyeol Jung
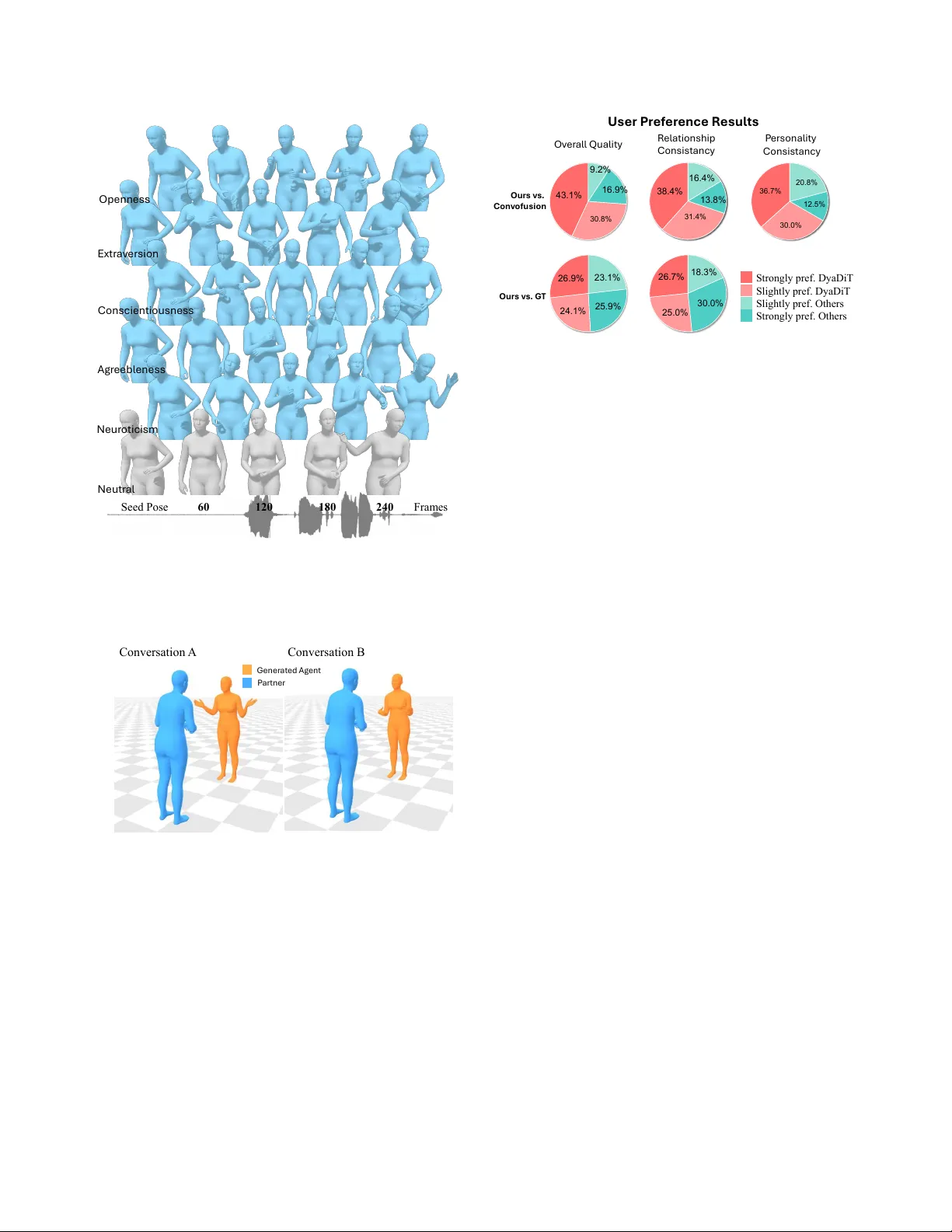
본 논문은 디지털 휴먼이 인간과 자연스럽게 대화하기 위해서는 음성뿐 아니라 몸짓까지 포함한 멀티모달 상호작용이 필요하다는 점에 착안한다. 기존 연구들은 주로 단일 화자의 음성에 대응하는 제스처를 생성하거나, dyadic 대화에서도 두 음성을 단순히 합쳐 하나의 신호로 처리해 화자 구분이 모호한 경우가 많았다. 이러한 한계를 극복하기 위해 저자들은 DyaDiT라는 새로운 모델을 설계하였다.
1) **문제 정의 및 데이터**
DyaDiT는 dyadic(양측) 대화 상황에서 한 화자(‘self’)의 음성과 상대 화자(‘other’)의 음성을 동시에 입력받아, ‘other’ 화자의 상체 제스처를 생성한다. 추가적으로 관계 유형(친구·가족·연인·낯선 사람)과 5가지 성격 점수(외향성, 친화성, 성실성, 신경성, 개방성)와 같은 사회적 컨텍스트 토큰을 옵션으로 제공한다. 학습 데이터는 Seamless Interaction Dataset에서 추출한 3,000개의 자연스러운 대화 클립(총 182시간)이며, 각 클립은 6D 회전 형태의 상체 관절 데이터와 오디오, 사회적 메타데이터를 포함한다.
2) **모델 아키텍처**
핵심은 Diffusion Transformer(DiT) 기반의 확산 모델이다. DDPM 프레임워크를 차용해, 노이즈가 섞인 잠재 포즈 x_t를 입력으로 받아 ε를 예측함으로써 점진적으로 깨끗한 제스처 시퀀스를 복원한다. 컨텍스트 c는 ORCA를 통해 정제된 오디오 토큰, 파트너 모션, 관계·성격 임베딩으로 구성된다.
- **ORCA (Audio Orthogonalization Cross Attention)**
두 화자의 오디오 특징 a_self, a_other을 Wave2Vec2로 추출한 뒤, a_self에서 a_other에 대한 투영을 빼는 정규화(a⊥self = a_self − Proj_{a_other}(a_self))를 수행한다. 이렇게 얻은 상보적 오디오 표현은 양방향 교차‑어텐션에 입력되어, ‘self → other’와 ‘other → self’의 상호 반응을 각각 캡처한다. 최종적으로 가중 게이트 σ(W_g)를 통해 두 흐름을 혼합해 f_audio를 만든다. 이 과정은 인터럽트, 겹침 등 실제 대화에서 발생하는 음성 혼합 문제를 효과적으로 완화한다.
- **Motion Dictionary (MD)**
스타일 제어를 위해 직교적인 모션 베이스 {d_0,…,d_n}를 학습한다. 훈련 시에는 실제 제스처에서 추출한 스타일 특징 f_motion =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기