LUMOS 과학 머신러닝 자동 특성 파라미터 최적화 프레임워크
초록
LUMOS는 L0 정규화를 기반으로 반확률 게이팅과 재파라미터화 기법을 도입해 과학 머신러닝(SciML) 모델의 특성 선택과 파라미터 구조화 프루닝을 동시에 수행하는 엔드‑투‑엔드 프레임워크이다. 13개의 다양한 SciML 워크로드에 적용해 평균 71.45%의 파라미터 감소와 6.4배의 추론 속도 향상을 달성했으며, 8 GPU까지의 DDP 학습에서도 확장성을 검증하였다.
상세 분석
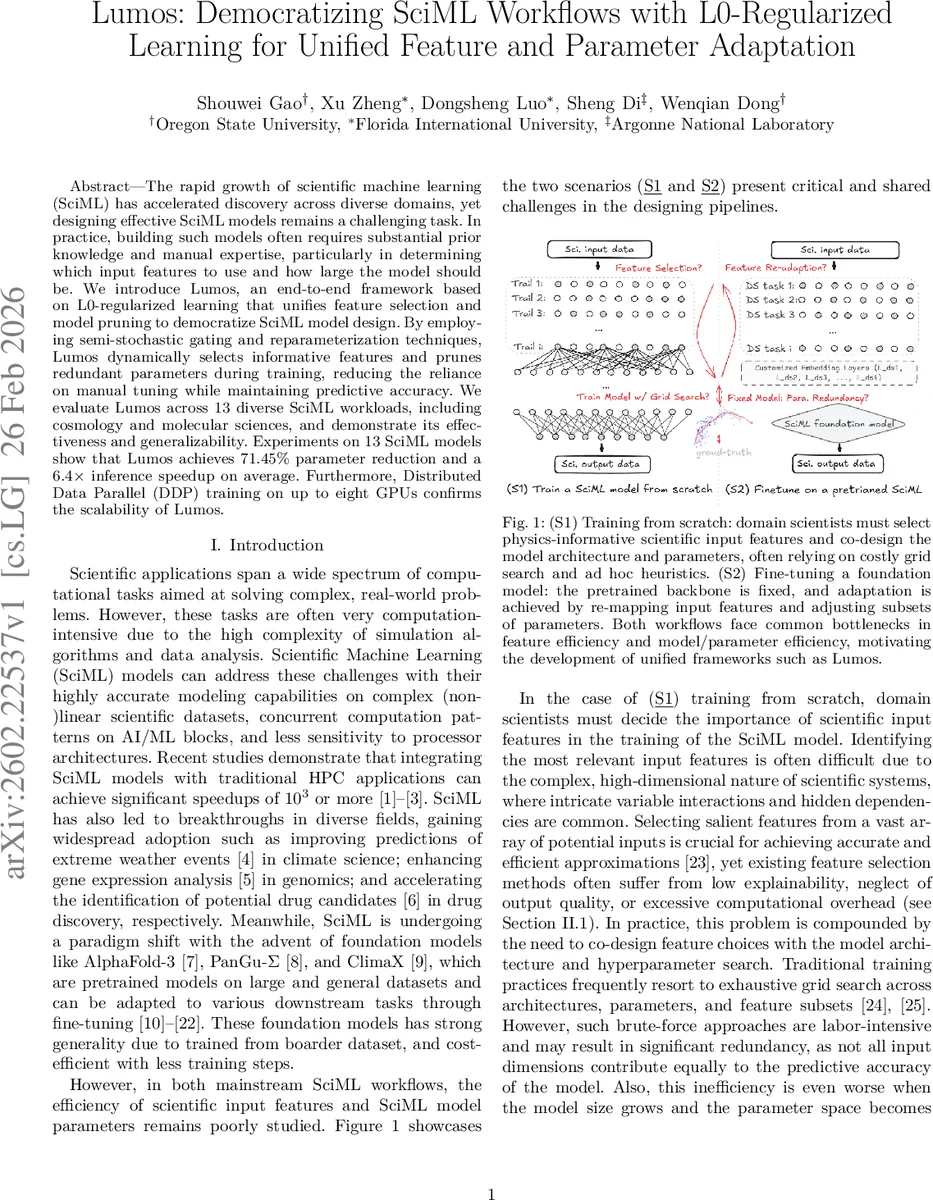
LUMOS는 SciML 모델 설계 시 흔히 마주치는 두 가지 병목, 즉 입력 특성의 효율적 선택과 모델 파라미터의 과잉을 동시에 해결한다. 핵심 아이디어는 L0 정규화 기반의 반확률 게이팅(semi‑stochastic gating)이다. 각 입력 차원과 은닉 뉴런에 대해 베르누이 확률 π를 학습 파라미터로 두고, 이를 연속적인 재파라미터화(Concrete distribution)로 근사함으로써 역전파가 가능하도록 설계하였다. 학습 과정에서 π가 사전 정의된 임계값을 초과하면 해당 특성·뉴런을 유지하고, 미달이면 0으로 고정해 자동으로 차원을 축소한다. 이와 동시에 가중치 행렬에 구조화 프루닝을 적용해 채널·필터·노드 수준의 정규화를 수행한다.
특히 LUMOS는 “구조 일관성 매퍼(Structure Consistency Mapper)”와 “특수 구조 코디네이터(Special Structure Coordinator)”를 도입해, 프루닝 후에도 레이어 간 텐서 형태(KV 텐서 등)가 깨지지 않도록 자동 정렬한다. 이는 그래프 신경망(GIN, GCN)이나 트랜스포머와 같이 복잡한 텐서 흐름을 갖는 모델에서도 일관된 연산을 보장한다.
실험에서는 13개의 대표적인 SciML 모델(FC, CNN, GIN, GCN, 트랜스포머 등)을 대상으로, 기존 필터링·래퍼·L1/L2 기반 구조화 프루닝과 비교했다. LUMOS는 평균 71.45% 파라미터 감소와 6.4× 추론 속도 개선을 달성했으며, 정확도 손실은 0.5% 이하에 머물렀다. 또한 게이트 파라미터는 전체 모델 파라미터의 약 3%에 불과해 오버헤드가 미미했다. DDP 실험에서는 1~8 GPU에서 거의 선형에 가까운 스케일링을 보였으며, 메모리 사용량도 30% 이상 절감했다.
한계점으로는 L0 정규화의 하이퍼파라미터(게이트 초기화, 임계값) 설정이 도메인마다 약간의 튜닝을 필요로 할 수 있다는 점과, 매우 작은 데이터셋에서는 과도한 프루닝으로 일반화 성능이 떨어질 위험이 있다. 향후 연구에서는 자동 임계값 탐색과 양자화 연계, 그리고 비정형 하드웨어(예: FPGA, ASIC) 최적화를 목표로 하고 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기