무작위 네트워크 디스틸레이션과 딥 앙상블, 베이지안 추론의 등가성
본 논문은 무한 폭 신경망의 NTK 한계에서 무작위 네트워크 디스틸레이션(RND)의 불확실성 신호가 딥 앙상블의 예측 분산과 정확히 동일함을 증명하고, 특정 타깃 함수를 설계하면 RND 오류 분포가 베이지안 신경망의 사후 예측 분포와 일치한다는 두 가지 핵심 등가성을 제시한다. 이를 기반으로 수정된 “베이지안 RND” 모델을 이용해 정확한 베이지안 사후 예측을 i.i.d. 샘플링하는 알고리즘을 제안한다.
저자: Moritz A. Zanger, Yijun Wu, Pascal R. Van der Vaart
본 연구는 무작위 네트워크 디스틸레이션(RND)이 제공하는 불확실성 신호가 기존의 딥 앙상블 및 베이지안 추론과 어떤 관계에 있는지를 이론적으로 규명한다. 먼저, 저자들은 NTK(Neural Tangent Kernel) 이론을 기반으로 무한 폭 신경망의 학습 동작을 선형화한다. 이 한계에서 초기 파라미터는 가우시안 프로세스(NNGP)로 모델링되며, gradient flow 하에서 NTK는 고정된다. 이러한 특성을 이용해 RND의 두 네트워크—고정된 랜덤 타깃 g와 학습 가능한 예측기 u—의 출력 차이 ε(x)=u(x)−g(x) 를 분석한다.
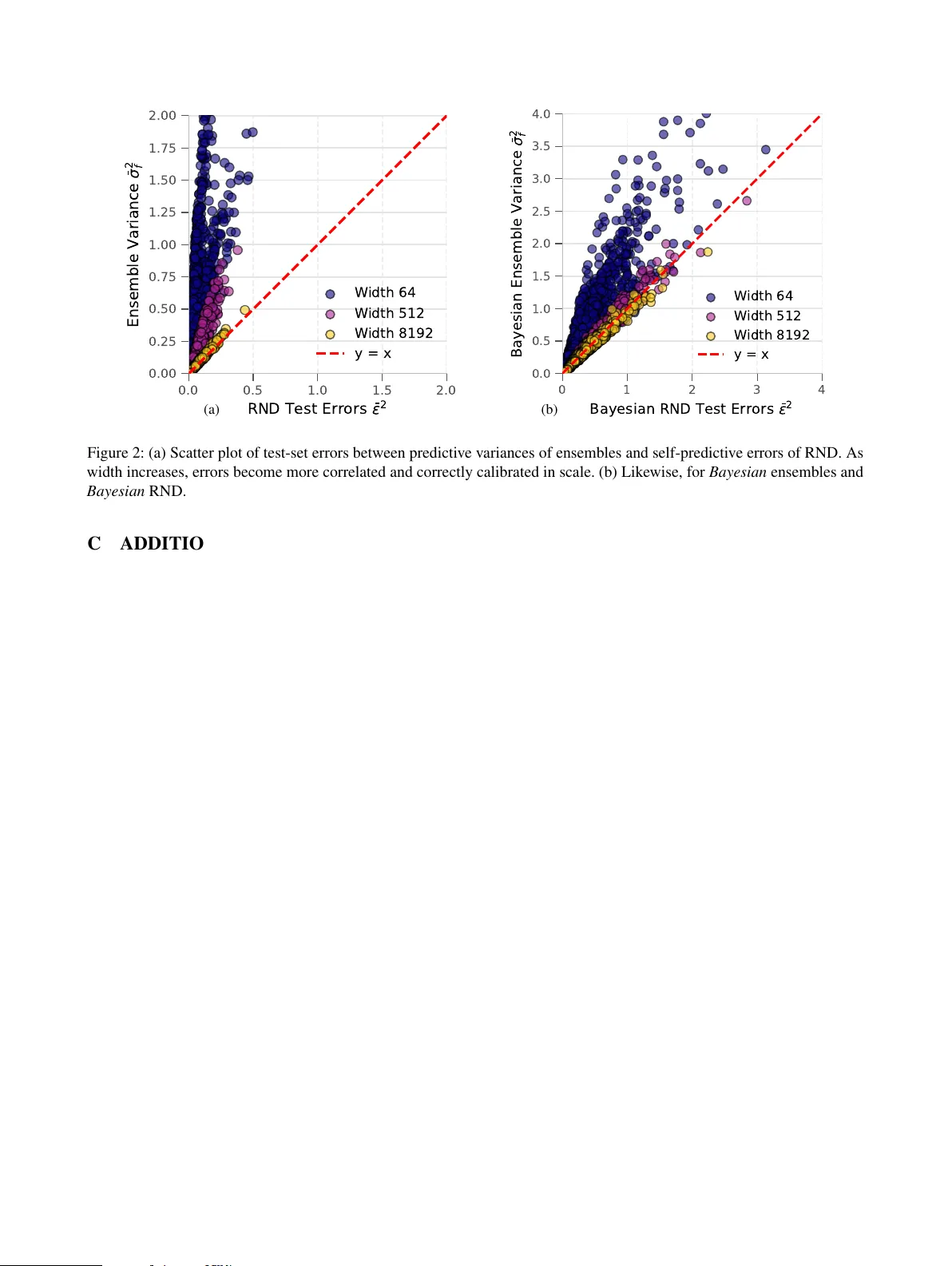
정리 3.1에 따르면, 무한 폭 한계에서 학습이 수렴한 후 ε는 평균이 0이고, 공분산이 NTK와 초기 커널 κ의 조합으로 표현되는 가우시안 프로세스가 된다. 여기서 핵심은 ε²의 기대값이 동일 아키텍처를 가진 무한 앙상블 모델의 예측 분산과 정확히 일치한다는 점이다(코롤라리 3.2). 즉, RND가 측정하는 자기‑예측 오류는 딥 앙상블이 제공하는 불확실성 추정과 수학적으로 동일한 양이다.
다중 헤드 구조를 고려한 경우, 정리 3.3은 출력 차원 간 독립성이 NTK 한계에서 유지된다는 사실을 증명한다. 이를 바탕으로 정리 3.4는 K개의 헤드가 있는 RND 모델의 평균 오류 \(\bar ε^2\) 와 K+1개의 독립 신경망으로 구성된 딥 앙상블의 샘플 분산 \(\bar σ^2\) 가 동일한 분포를 갖는다고 보여준다. 따라서 실무에서 흔히 사용하는 다중 헤드 RND도 딥 앙상블의 불확실성 추정과 동등한 역할을 한다는 결론에 도달한다.
두 번째 주요 기여는 “베이지안 RND” 모델이다. 저자들은 타깃 함수 g를 특별히 설계해, 초기 오류 ε₀의 공분산이 NTK와 일치하도록 만든다. 이렇게 하면 학습 후 ε의 분포가 베이지안 신경망의 사후 예측 분포와 동일해진다. 이를 기반으로 다중 헤드 베이지안 RND를 구성하고, 각 헤드에서 독립적인 샘플을 추출하면 무한 폭 베이지안 신경망의 사후 예측을 정확히 i.i.d. 샘플링할 수 있다. 이 방법은 기존의 MCMC나 변분 추정보다 계산·메모리 효율이 높으며, NTK 한계에서 정확성을 보장한다.
논문은 실험적 결과를 제시하지는 않지만, 이론적 증명을 통해 RND가 단순히 탐색 보상이나 OOD 탐지에 쓰이는 경험적 기법을 넘어, 딥 앙상블과 베이지안 추론이라는 두 주요 불확실성 프레임워크와 수학적으로 동일한 위치에 있음을 확립한다. 이는 RND를 실용적인 불확실성 추정 도구로 활용함과 동시에, 베이지안 이론에 기반한 효율적인 사후 샘플링 방법을 제공한다는 점에서 학계와 산업계 모두에 중요한 시사점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기